本文主要参考厦门大学林子雨老师的课程《Spark编程基础》(Scala版)
大数据技术概述
大数据时代

大数据时代技术支撑(存储,计算,网络)
- 存储,存储设备容量越来越大,价格越来越便宜
- 计算,CPU处理能力不断提升(摩尔定律),多核
- 网络,网络带宽提高,分布式处理
数据产生方式的变革促使大数据时代的来临,从运营式(沃尔玛大型超市购物系统),到用户原创(微博、微信),再到感知式(物联网)。
大数据概念
- Volume,大量
- Variety,多样(文件,音视频……)
- Velocity,快速(1秒定律,数据价值通常在诞生1秒内有效,比如在购物网站上实时点击流信息计算,构建用户画像,快速推荐相关商品)
- Value,价值密度低(比如大量摄像头存储的视频,只有车丢的那个瞬间视频才有用……)
大数据的影响
- 全样而非抽样(不存在抽样误差)
- 效率而非精确(1秒定律,不追求算法精度)
- 相关而非因果(比如去网上买一本书,被推荐另一本书,只关心两本书相关性,不必问有何因果关系)
大数据关键技术
- 数据采集
- 数据存储和管理
- 数据处理与分析
- 数据隐私与安全
两大核心技术:分布式存储和分布式处理(很多技术都来自Google公司,论文被实现成了 Hadoop 的分布式文件系统 HDFS 和分布式数据库 HBase)
大数据计算模式

Hadoop

MapReduce 把大数据切分并行计算,并且计算向数据靠拢。比如词频统计,计算程序分别对各部分单词进行词频统计,再汇总。
Yarn 进行资源调度。如果批处理任务和流任务各自进行资源调度,会一起抢CPU等资源,混乱!Yarn 可以为他们统一调度资源。
Spark
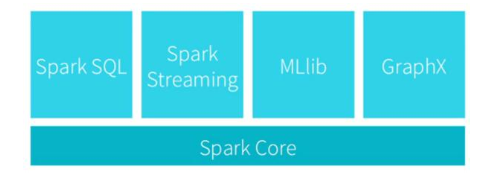
Spark 提供了一站式的服务,并且可以和其他组件结合。

MapReduce 磁盘I/O开销大(比如机器学习里有很多迭代计算,不断磁盘I/O太慢了);表达能力有限(只能搞成 Map 和 Reduce 两个操作);延迟高(一是磁盘I/O比较慢,二是一个任务必须所有 Map 之后才能 Reduce,等待耗时)。
Spark 在借鉴 Hadoop MapReduce 优点的同时,很好地解决了 MapReduce 的缺点问题。Spark 提供了更多的数据集操作类型,提供了内存计算,基于 DAG 任务调度执行机制。

Flink 是和 Spark 同时出来的类似的技术!Beam 则是想提供统一编程接口,底层自动转成 Hadoop/Spark/Flink 等,一统所有大数据技术!
Scala 语言基础
函数式编程
像 C/C++/Java 等语言都是命令式编程,就是翻译成一个一个命令,计算机逐条执行命令。在多核 CPU 下,命令式编程采用锁机制解决一些并行共享状态问题,但一旦锁起来就不能并行,这样并行能力不好!而函数式编程不需要在多线程中共享状态,可以充分利用多核 CPU 并行处理能力。
Scala 学习资料
Programming in Scala, First Edition
by Martin Odersky, Lex Spoon, and Bill Venners
December 10, 2008
Spark 的设计与运行原理















安装 Spark
参考该篇博文Hadoop 安装完成 Hadoop 的安装,关闭 Hadoop 命令 sbin/stop-dfs.sh,开启 Hadoop 命令sbin/start-dfs.sh。然后为 Spark 配置 HDFS,在 spark 的目录下,cp ./conf/spark-env.sh.template ./conf/spark-env.sh 并在该文件第一行添加export SPARK_DIST_CLASSPATH=$(Hadoop路径/bin/hadoop classpath)。要使用 HDFS,首先需要在 HDFS 中创建用户目录。

然后在/spark/bin下执行 ./run-example SparkPi,这是 Spark 计算圆周率的例子!再试试运行 ./spark-shell命令!
Spark独立应用程序编程
- 安装 sbt。下载 sbt,
sbt/bin$ cp sbt-launch.jar ../,把 bin 目录下的 sbt-launch.jar 复制到 sbt 安装目录下。 - 在 sbt 安装目录下,创建脚本 sbt,并授予执行权限,
chmod 764 sbt。
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
- 编写 Scala 应用程序,在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(
vi ./sparkapp/src/main/scala/SimpleApp.scala),
cd ~ # 进入用户主文件夹
mkdir ./sparkapp # 创建应用程序根目录
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///spark安装目录/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
- 用 sbt 打包,该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。 请在./sparkapp 中新建文件 simple.sbt(
vi ./sparkapp/simple.sbt)。并确认结构。
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.6"
使用下面命令打包,对于刚安装好的Spark和sbt而言,第一次运行上面的打包命令时,会需要几分钟的运行时间,因为系统会自动从网络上下载各种文件(笔者发现很慢,并且不知为何,笔者的 Ubuntu 有时会连不上网……)。编译成功出现信息 [success] Total time: 206 s (03:26), completed Jul 26, 2020 1:06:04 AM。
~/sparkapp$ /home/mi2/env/sbt/sbt package
- 通过 spark-submit 运行程序
spark路径/bin/spark-submit --class "SimpleApp" sparkapp路径/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar

RDD 编程
RDD 创建
makeRDD

从本地文件加载数据



从并行集合(数组/List)加载数据









下面是一个实例,计算每个键对应的平均值,转换步骤下图示意(笔者数字不同)


从HDFS加载数据
能够通过 Spark 访问 HDFS,得益于在 Spark 的配置文件中配置了 hadoop 命令的路径,并且笔者实现在 hadoop 的路径下创建了 /user/mi2 这一 HDFS 文件路径。



了解 HBase
HBase 基于 HDFS。也可从 HBase 中读取数据。。

例子(求多文件某列的topN)
如下,两个文件 file1.txt 和 file2.txt,有很多条记录,求出这些文件所有记录中第 2 列所有数的 top3。
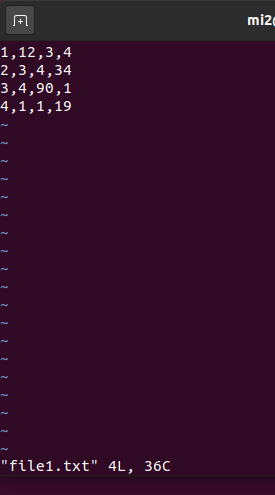
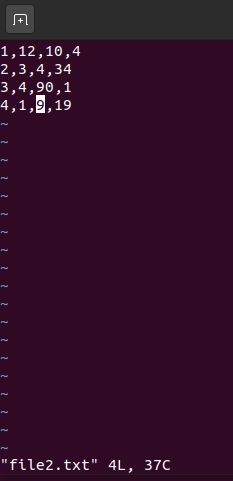
val lines = sc.textFile("/user/mi2/chapter5")
lines.filter(line => line.trim.length > 0 && line.split(",").length == 4).map(_.split(",")(2)).sortBy(x => x.toInt, false).take(3).foreach(println)
例子(求多文件最大/小值)
$ hadoop fs -mkdir /user/mi2/chapter5.2
$ vi f1.txt
$ vi f2.txt
$ hadoop fs -put f1.txt /user/mi2/chapter5.2
$ hadoop fs -put f2.txt /user/mi2/chapter5.2
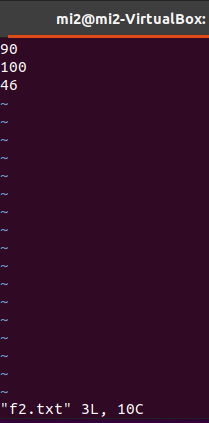
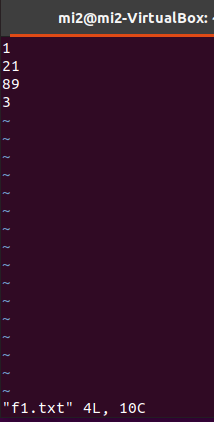
val lines = sc.textFile("/user/mi2/chapter5.2")
lines.filter(_.trim.length > 0).map(line => ("key", line.toInt)).groupByKey.map(x => {
var min = Integer.MAX_VALUE
var max = Integer.MIN_VALUE
for(num <- x._2){
if(num < min) min = num
if(num > max) max = num
}
(max, min)
}).collect.foreach(x => {
println("max=" + x._1)
println("min=" + x._2)
})
Spark SQL



官方教程之 Getting Started
// 本部分其实就讲解了下面这份官方示例代码,涉及 DataFrame 和 DataSet,及 RDD 转成 DataFrame 的操作。
spark/examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala
// 把 Spark 已经打好的包拷贝到自己的 sparkapp 中
~/env/spark/examples/jars$ cp spark-examples_2.11-2.4.6.jar /home/mi2/sparkapp/target/
// 把 examples 的资源拷贝到 hdfs 中(示例代码中引用了该路径)
$ hadoop fs -put /home/mi2/env/spark/examples /user/mi2
// 执行示例代码,注意写类的全限定名
~/env/spark/bin$ ./spark-submit --class "org.apache.spark.examples.sql.SparkSQLExample" /home/mi2/sparkapp/target/spark-examples_2.11-2.4.6.jar
官网示例代码,SparkSQLExample.scala
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.examples.sql
import org.apache.spark.sql.Row
// $example on:init_session$
import org.apache.spark.sql.SparkSession
// $example off:init_session$
// $example on:programmatic_schema$
// $example on:data_types$
import org.apache.spark.sql.types._
// $example off:data_types$
// $example off:programmatic_schema$
object SparkSQLExample {
// $example on:create_ds$
case class Person(name: String, age: Long)
// $example off:create_ds$
def main(args: Array[String]) {
// $example on:init_session$
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
// $example off:init_session$
runBasicDataFrameExample(spark)
runDatasetCreationExample(spark)
runInferSchemaExample(spark)
runProgrammaticSchemaExample(spark)
spark.stop()
}
private def runBasicDataFrameExample(spark: SparkSession): Unit = {
// $example on:create_df$
val df = spark.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:create_df$
// $example on:untyped_ops$
// This import is needed to use the $-notation
import spark.implicits._
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
// $example off:untyped_ops$
// $example on:run_sql$
// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:run_sql$
// $example on:global_temp_view$
// Register the DataFrame as a global temporary view
df.createGlobalTempView("people")
// Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:global_temp_view$
}
private def runDatasetCreationExample(spark: SparkSession): Unit = {
import spark.implicits._
// $example on:create_ds$
// Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:create_ds$
}
private def runInferSchemaExample(spark: SparkSession): Unit = {
// $example on:schema_inferring$
// For implicit conversions from RDDs to DataFrames
import spark.implicits._
// Create an RDD of Person objects from a text file, convert it to a Dataframe
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by Spark
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// The columns of a row in the result can be accessed by field index
teenagersDF.map(teenager => "Name: " + teenager(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// or by field name
teenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// No pre-defined encoders for Dataset[Map[K,V]], define explicitly
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
// Primitive types and case classes can be also defined as
// implicit val stringIntMapEncoder: Encoder[Map[String, Any]] = ExpressionEncoder()
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]
teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect()
// Array(Map("name" -> "Justin", "age" -> 19))
// $example off:schema_inferring$
}
private def runProgrammaticSchemaExample(spark: SparkSession): Unit = {
import spark.implicits._
// $example on:programmatic_schema$
// Create an RDD
val peopleRDD = spark.sparkContext.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a string
val schemaString = "name age"
// Generate the schema based on the string of schema
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// Convert records of the RDD (people) to Rows
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// Apply the schema to the RDD
val peopleDF = spark.createDataFrame(rowRDD, schema)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL can be run over a temporary view created using DataFrames
val results = spark.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations
// The columns of a row in the result can be accessed by field index or by field name
results.map(attributes => "Name: " + attributes(0)).show()
// +-------------+
// | value|
// +-------------+
// |Name: Michael|
// | Name: Andy|
// | Name: Justin|
// +-------------+
// $example off:programmatic_schema$
}
}
Spark Streaming
待续……
Spark MLib
待续……
参考资料
[1] 《Spark编程基础(Scala版)》厦门大学 林子雨老师
[2] Spark 安装教程
[3] Spark 官方文档
[4] Spark 官方教程