Spark Streaming(流处理)
Spark Streaming(流处理)
什么是流处理?
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。批量处理模型中,一般先有全量数据集,然后定义计算逻辑,并将计算应用于全量数据。特点是全量计算,并且计算结果一次性全量输出。

Spark Streaming是核心Spark API的扩展,可实现实时数据流的可扩展,高吞吐量,容错流处理。数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字)中获取,并且可以使用以高级函数(如map,reduce,join和window)表示的复杂算法进行处理。最后,处理后的数据可以推送到文件系统,数据库和实时dashboards。

在内部,它的工作原理如下。 Spark Streaming接收实时输入数据流并将数据分成批处理,然后由Spark引擎处理以批量生成最终结果流。
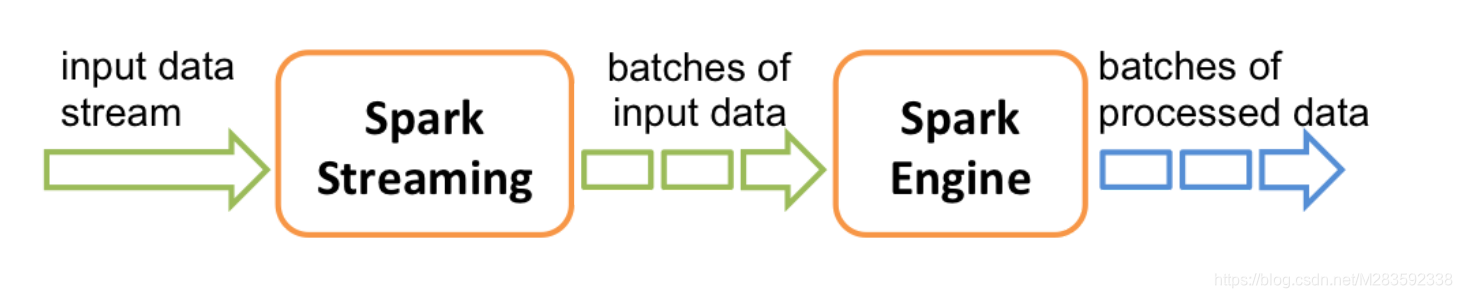
Spark Streaming提供称为离散流或DStream的高级抽象,表示连续的数据流。DStream可以从来自Kafka,Flume和Kinesis等源的输入数据流创建,也可以通过在其他DStream上应用高级操作来创建。在内部DStream表示为一系列RDD。
备注:Spark Streaming 因为底层使用批处理模拟流处理,因此在实时性上大打折扣,这就导致了Spark Streaming在流处理领域有者着先天的劣势。虽然Spark Streaming 在实时性上不如一些专业的流处理引擎(Storm/Flink)但是Spark Stream在使用吸取RDD设计经验,提供了比较友好的API算子,使得使用RDD做批处理的程序员可以平滑的过渡到流处理。
针对于Spark Streaming的微观的批处理问题,目前大数据处理领域又诞生了新秀
Flink,该大数据处理引擎,在API易用性上和实时性上都有一定的兼顾,但是与spark最大的差异是Flink底层的处理引擎是流处理引擎,因此Flink天生就是流处理,但是Spark因为底层是批处理,导致了Spark Streaming在实时性上就没法和其他的专业流处理框架对比了。
快速入门
- pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.3</version>
</dependency>
- SparkStreamWordCounts
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()//等待系统发送指定关闭流计算
需要注意:
[root@CentOS ~]# yum install -y nc启动nc服务[root@CentOS ~]# nc -lk 9999,注意在调用改程序的时候,需要设置local[n],n>1
概念介绍
通过上述案例的运行,现在我们来一起探讨一些流处理的概念。在处理流计算的时候,除去spark-core依赖以外我们还需要引入spark-streaming模块。要从Spark Streaming核心API中不存在的Kafka,Flume和Kinesis等源中提取数据,您必须将相应的工件spark-streaming-xxx_2.11添加到依赖项中。xxx例如Kafka
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.3</version>
</dependency>
初始化 StreamingContext
要初始化Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark Streaming功能的主要入口点。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
appName参数是应用程序在集群UI上显示的名称。 master是Spark,YARN群集URL,或者是在本地模式下运行的特殊local [*]字符串。实际上,在群集上运行时,您不希望在程序中对master进行硬编码,而是使用spark-submit启动指定–master配置。但是,对于本地测试和单元测试,您可以传递local [*]以在进程中运行Spark Streaming(系统会自动检测本地系统的核的数目)。
请注意ssc会在内部创建一个SparkContext(所有Spark功能的起点),如果需要获取SparkContext对象用户可以调用ssc.sparkContext访问。例如用户使用SparkContext关闭日志。
val conf = new SparkConf()
.setMaster("local[5]")
.setAppName("wordCount")
val ssc = new StreamingContext(conf,Seconds(1))
//关闭其他日志
ssc.sparkContext.setLogLevel("FATAL")
必须根据应用程序的延迟要求和可用的群集资源设置批处理间隔。要使群集上运行的Spark Streaming应用程序保持稳定,系统应该能够以接收数据的速度处理数据。换句话说,批处理数据应该在生成时尽快处理。通过监视流式Web UI中的处理时间可以找到是否适用于应用程序,其中批处理时间应小于批处理间隔。
val conf = new SparkConf()
.setMaster("local[5]")
.setAppName("wordCount")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(1))
当用户创建完StreamingContext对象之后,用户需要完成以下步骤
- 定义数据源,用于创建输入的 DStreams.
- 定义流计算算子,通过定义这些算子实现对DStream数据转换和输出
- 调用streamingContext.start()启动数据.
- 等待计算结束 (人工结束或者是错误) 调用 streamingContext.awaitTermination().
- 如果是人工结束,程序应当调用 streamingContext.stop()结束流计算.
重要因素需要谨记
- 一旦流计算启动,无法再往计算流程中添加任何计算算子
- 一旦SparkContext对象被stop后,无法重启。
- 一个JVM系统中只能实例化一个StreamingContext对象。
- SparkContext被stop()后,内部创建的SparkContext也会被stop.如果仅仅是想Stop StreamingContext, 可以设置stop() 中的可选参数 stopSparkContext=false即可.
ssc.stop(stopSparkContext = false)
- 一个SparkContext 可以重复使用并且创建多个StreamingContexts, 前提是上一个启动的StreamingContext 被停止了(但是并没有关闭 SparkContext对象) 。
Discretized Streams (DStreams)
Discretized Stream或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变分布式数据集的抽象。DStream中的每个RDD都包含来自特定时间间隔的数据,如下图所示。
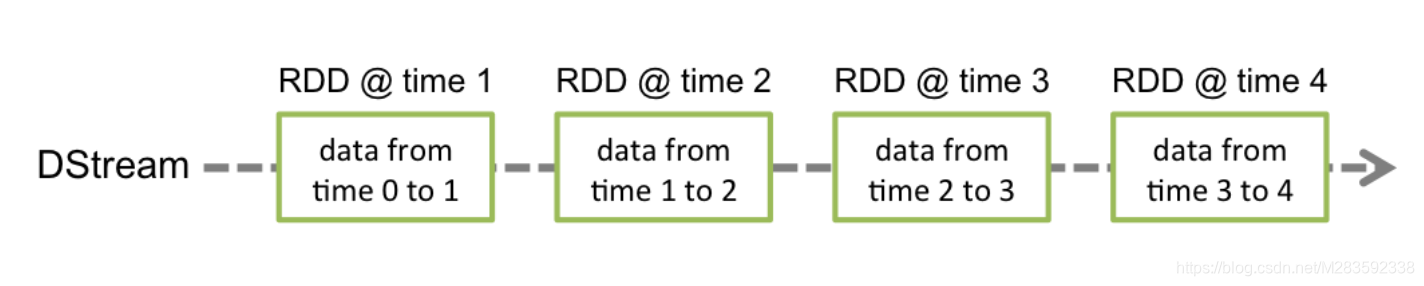
应用于DStream的任何操作都转换为底层RDD上的操作。例如,在先前Quick Start示例中,flatMap操作应用于行DStream中的每个RDD以生成单词DStream的RDD。如下图所示。

这些底层RDD转换由Spark引擎计算。 DStream操作隐藏了大部分细节,并为开发人员提供了更高级别的API以方便使用。
InputStream & Receivers
Input DStream 表示流计算的输入,Spark中默认提供了两类的InputStream:
- Baisc Source :例如 filesystem、scoket
- Advance Source:例如:Kafka、Flume等外围系统的数据。
除filesystem以外,其他的Input DStream默认都会占用一个Core(计算资源),在测试或者生产环境下,分配给计算应用的Core数目必须大于Receivers个数。(本质上除filesystem源以外,其他的输入都是Receiver抽象类的实现。)了例如socketTextStream底层封装了SocketReceiver
Basic Sources
因为在快速入门案例中已经使用了socketTextStream,后续我们只测试一下filesystem对于从与HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件读取数据,可以通过StreamingContext.fileStream [KeyClass,ValueClass,InputFormatClass]创建DStream。文件流不需要运行Receiver,因此不需要为接收文件数据分配任何core。对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)
val conf = new SparkConf().setMaster("local[2]").setAppName("FileSystemWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
val lines = ssc.textFileStream("hdfs://CentOS:9000/demo/words")
lines.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
在HDFS上创建目录
[root@CentOS ~]# hdfs dfs -mkdir -p /demo/words
[root@CentOS ~]# hdfs dfs -put install.log /demo/words
Queue of RDDs as a Stream(测试)
为了使用测试数据测试Spark Streaming应用程序,还可以使用streamingContext.queueStream(queueOfRDDs)基于RDD队列创建DStream。推入队列的每个RDD将被视为DStream中的一批数据,并像流一样处理。
val conf = new SparkConf().setMaster("local[2]").setAppName("FileSystemWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
val queue=new mutable.Queue[RDD[String]]();
val lines = ssc.queueStream(queue)
lines.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
for(i <- 1 to 30){
queue += ssc.sparkContext.makeRDD(List("this is a demo","hello how are you"))
Thread.sleep(1000)
}
ssc.stop()
Advance Source Kafka
- pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.3</version>
</dependency>
- Kafka对接Spark Streaming
val conf = new SparkConf().setMaster("local[2]").setAppName("FileSystemWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "CentOS:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group1",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,//设置加载数据位置策略,
Subscribe[String,String](Array("topic01"),kafkaParams))
.map(record => record.value())
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
Spark Stream 算子
- transform(func)
该算子可以将DStream的数据转变成RDD,用户操作流数据就像操作RDD感觉是一样的。
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "CentOS:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group1",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val cacheRDD = ssc.sparkContext.makeRDD(List("001 zhangsan", "002 lisi", "003 zhaoliu"))
.map(item => (item.split("\\s+")(0), item.split("\\s+")(1)))
.distinct()
.cache()
//001 apple
KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
Subscribe[String,String](Array("topic01"),kafkaParams))
.map(record => record.value())
.map(value=>{
val tokens = value.split("\\s+")
(tokens(0),tokens(1))
})
.transform(rdd=>{rdd.rightOuterJoin(cacheRDD)})
.filter(t=> {t._2._1!=None})
.print()
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("hdfs://CentOS:9000/checkpoints")//在JVM启动参数中添加-D HADOOP_USER_NAME=root
def updateFun(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
var total= newValues.sum+runningCount.getOrElse(0)
Some(total)
}
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.updateStateByKey(updateFun)
.print()
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()
因为UpdateStateByKey 算子每一次的输出都是全量输出,在做状态更新的时候代价较高,因此推荐大家使用
mapWithState
- mapWithState
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("hdfs://CentOS:9000/checkpoints")
def updateFun(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
var total= newValues.sum+runningCount.getOrElse(0)
Some(total)
}
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.mapWithState(StateSpec.function((k:String,v:Option[Int],state:State[Int])=>{
var total=0
if(state.exists()){
total=state.getOption().getOrElse(0)
}
total += v.getOrElse(1)
state.update(total)//更新状态
(k,total)
}))
.print()
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()
重故障中|重启中状态恢复
var checkpointPath="hdfs://CentOS:9000/checkpoints"//设置检查点目录,一般将检查点目录存储在HDFS上
var ssc=StreamingContext.getOrCreate(checkpointPath,()=>{//第一次启时候初始化,一旦书写完成后,无法进行修改!
println("=======init=======")
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint(checkpointPath)
def updateFun(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
var total= newValues.sum+runningCount.getOrElse(0)
Some(total)
}
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.mapWithState(StateSpec.function((k:String,v:Option[Int],state:State[Int])=>{
var total=0
if(state.exists()){
total=state.getOption().getOrElse(0)
}
total += v.getOrElse(1)
state.update(total)//更新状态
(k,total)
}))
.checkpoint(Seconds(5))//设置状态持久化的频率,该频率不能高于 微批 拆分频率 ts>=5s
.print()
ssc
})
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()
窗口函数 - window
Spark Streaming还提供窗口计算,允许您在滑动数据窗口上应用转换。下图说明了此滑动窗口。
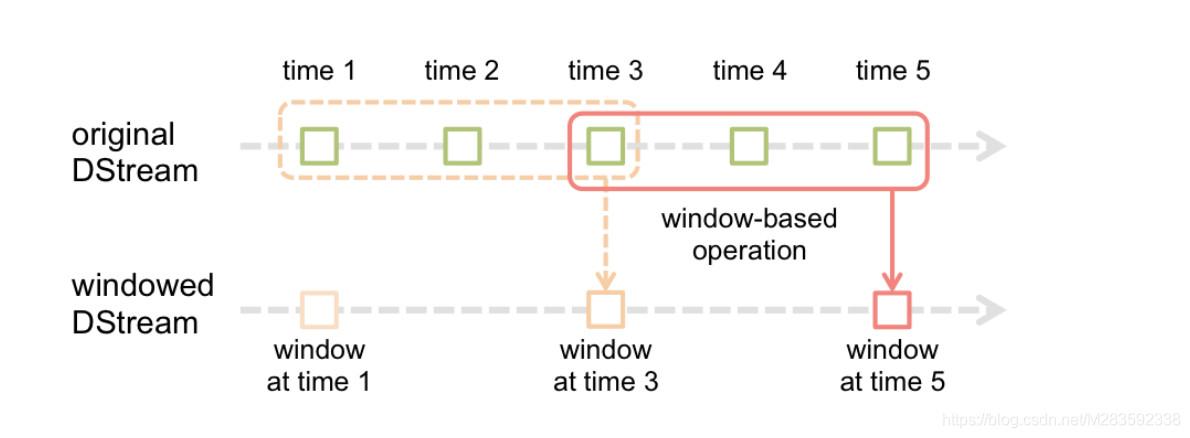
以上描述了窗口长度是3个时间单位的微批,窗口的滑动间隔是2个时间单位的微批,注意:Spark的流处理中要求窗口的长度以及滑动间隔必须是微批的整数倍。
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKeyAndWindow((v1:Int,v2:Int)=> v1+v2,Seconds(5),Seconds(5))
.print()
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()
Output Operations
- foreachRDD(func)
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreamWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.window(Seconds(5),Seconds(5))
.reduceByKey((v1:Int,v2:Int)=> v1+v2)
.foreachRDD(rdd=>{
rdd.foreachPartition(items=>{
var jedisPool=new JedisPool("CentOS",6379)
val jedis = jedisPool.getResource
val pipeline = jedis.pipelined()//jedis批处理
val map = items.map(t=>(t._1,t._2+"")).toMap.asJava
pipeline.hmset("wordcount",map)
pipeline.sync()
jedis.close()
})
})
ssc.sparkContext.setLogLevel("FATAL")//关闭日志打印
ssc.start()
ssc.awaitTermination()