解析链接
我们经常需要对url进行合并,提取,转换等操作,urllib下的parse模块了解一下~
解析链接
urlparse()
把url解析为一个6元素的列表,包括scheme,netloc,path,params,query,fragment.
urlunparse()
urlparse的逆操作,把列表转化成url.
urlsplit()
和urlparse()函数类似,区别在于解析为5个元素,params不单解析出来。
urlunsplit()
urlparse()的逆操作。
链接拼接
urljoin()
把两个url合并,接受两个url参数,以第二个为基准,主要判定scheme,netloc,path三个元素,第二个参数缺啥就用第一个参数补齐。
参数序列化
urlencode()
在我要爬爬虫(1)已经学习过,是将参数(可迭代对象)解析成字符串的函数,是一个序列化的过程。
parse_qs()
逆序列化操作,将字符串转换成字典。
parse_qsl()
逆序列化操作,将字符串转换成元组构成的列表。
中文转url
quote()
url带有中文,有可能导致乱码,所以要先转换成url编码。
unquote()
quote()函数的逆操作。
代码操作
Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)] on win32
from urllib.parse import urlparse
url='http://www.baidu.com/index.heml;user?id=5#comment'
result=urlparse(url)
result
Out[5]:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.heml', params='user', query='id=5', fragment='comment')
result.scheme
Out[6]:
'http'
urlparse(url)
Out[7]:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.heml', params='user', query='id=5', fragment='comment')
from urllib.parse import urlunparse
urlunparse(result)
Out[10]:
'http://www.baidu.com/index.heml;user?id=5#comment'
from urllib.parse import urljoin
urljoin('http://www.baidu.com','https://zdz.com/index')
Out[12]:
'https://zdz.com/index'
from urllib.parse import urlencode
params={
'user':'Tom',
'pw':123
}
urlencode(params)
Out[15]:
'user=Tom&pw=123'
from urllib.parse import parse_qs
param=urlencode(params)
parse_qs(param)
Out[18]:
{'pw': ['123'], 'user': ['Tom']}
from urllib.parse import quote
keyword='中文'
quote(keyword)
Out[21]:
'%E4%B8%AD%E6%96%87'Robots协议
在网站的根目录下会存放一个Robots.txt文件,类似于这样的内容:
#这条协议对所有爬虫有效
User-Agent:*
#不允许爬虫访问所有目录
Disallow:/
#允许爬虫访问/public/目录
Allow:/public/这是百度的Robots文件,可以看到它规定了一些不能爬取的目录。
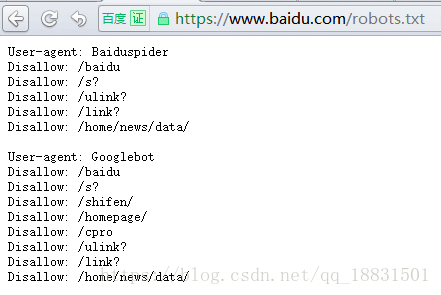
一般在Robots.txt的末尾,都要由这样一句协议:
User-Agent:*
Disallow:/这样使得除了以上的提到的爬虫和目录外,其他任何爬虫都不能访问本站任何目录。
解析Robots协议
利用robotparser模块下的RobotFileParser()函数来解析Robots协议,参数即为该网站的Robots.txt的路径。
robot=RobotFileParser(url/robots.txt')
这样就实例化一个解析该网站Robots协议的解析器。
必要的,调用解析器的read()方法,对协议进行解析。
robot.read()
最后使用解析器的can_fetch()方法:
robot.can_fetch(爬虫名,该网站下要爬的url)
from urllib.robotparser import RobotFileParser
rp=RobotFileParser('https://www.baidu.com/robots.txt')
rp.read()
print(rp.can_fetch('Baiduspider','https://www.baidu.com/s?wd=python'))
print(rp.can_fetch('Baiduspider','http://www.baidu.com/duty/'))结果:
False
True对比上方的百度Robots协议,可以看到BaiduSpider在/s?目录下是禁止访问的;而在/duty目录下可以访问。
顺便说一下,爬虫名不区分大小写。