从本系列文章开始,作者正式开始研究Python深度学习、神经网络及人工智能相关知识。前五篇文章讲解了神经网络基础概念、Theano库的安装过程及基础用法、theano实现回归神经网络、theano实现分类神经网络、theano正规化处理,这篇文章讲解神经网络的评价指标、特征标准化和特征选择,均是基础性知识。主要是学习"莫烦大神" 网易云视频的在线笔记,后面随着深入会讲解具体的项目及应用。基础性文章和在线笔记,希望对您有所帮助,本系列作者采用一篇基础一篇代码的形式讲解,也建议大家一步步跟着学习,同时文章中存在错误或不足之处,还请海涵~
"莫烦大神" 网易云视频地址:http://study.163.com/provider/1111519/course.html
从2014年开始,作者主要写了三个Python系列文章,分别是基础知识、网络爬虫和数据分析。
- Python基础知识系列:Pythonj基础知识学习与提升
- Python网络爬虫系列:Python爬虫之Selenium+Phantomjs+CasperJS
- Python数据分析系列:知识图谱、web数据挖掘及NLP


前文参考:
[Python人工智能] 一.神经网络入门及theano基础代码讲解
[Python人工智能] 二.theano实现回归神经网络分析
[Python人工智能] 三.theano实现分类神经网络及机器学习基础
[Python人工智能] 四.神经网络和深度学习入门知识
[Python人工智能] 五.theano实现神经网络正规化Regularization处理
一. 神经网络评价指标
由于各种问题影响,会导致神经网络的学习效率不高,或者干扰因素太多导致分析结果不理想。这些因素可能是数据问题,学习参数问题等。这就涉及到了神经网络评价指标。
如何评价(Evaluate)神经网络呢?我们可以通过一些指标对神经网络进行评价,通过评价来改进我们的神经网络。评价神经网络的方法和评价机器学习的方法大同小异,常见的包括误差、准确率、R2 score等。

数据分析通常会将数据集划分为训练数据和预测数据,常见的如70%训练集和30%测试集,或者80%训练集和20%测试集。例如,我们读书时包括作业题和考试题,虽然期末考试时间很少,但其得分比例要高于平时作业。
1.误差(Error)
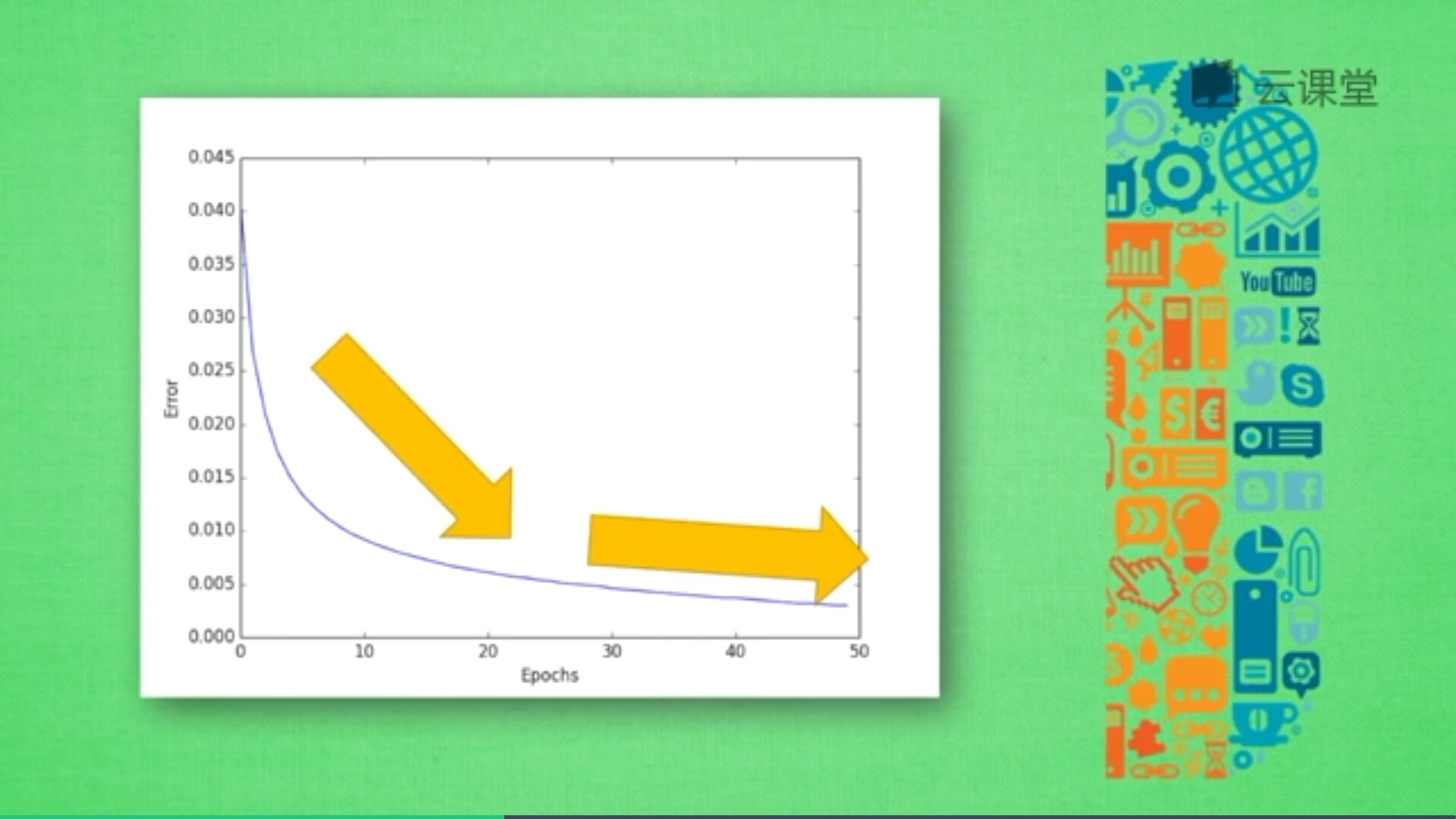
先用误差评价神经网络,如下图所示,随着训练时间增长,预测误差会不断减小,得到更为准确的答案,最后误差会趋近于水平。
2.精准度(Accuracy)
精准度是指预测结果与真实结果的准确率,接近100%是最好的结果。例如,神经网络中分类问题,100个样本中有90个分类正确,则其预测精准度为90%。通过可以使用精准度预测分类问题,那么,如果是回归问题呢?如何评价连续值的精准度呢?我们使用R2 Score值来进行。

3.R2 Score
在评价回归模型时,sklearn中提供了四种评价尺度,分别为mean_squared_error、mean_absolute_error、explained_variance_score 和 r2_score。
参考:https://blog.csdn.net/Softdiamonds/article/details/80061191
(1) 均方差(mean_squared_error)
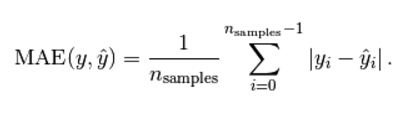
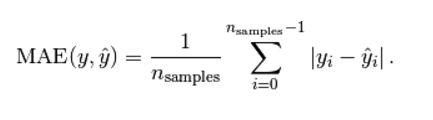
(2) 平均绝对值误差(mean_absolute_error)
(3) 可释方差得分(explained_variance_score)
Explained variation measures the proportion to which a mathematical model accounts for the variation (dispersion) of a given data set.
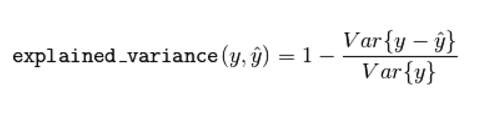
(4) 中值绝对误差(Median absolute error)
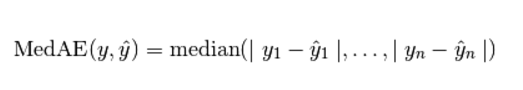
(5) R2 决定系数(拟合优度)
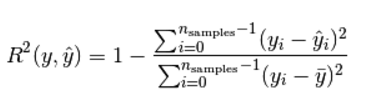
模型越好:r2→1,模型越差:r2→0。Sklearn代码调用如下:
from sklearn.metrics import r2_score
y_true = [1,2,4]
y_pred = [1.3,2.5,3.7]
r2_score(y_true,y_pred)
4.其他标准。
如F1 Score值,用于测量不均衡数据的精度。
过拟合问题:
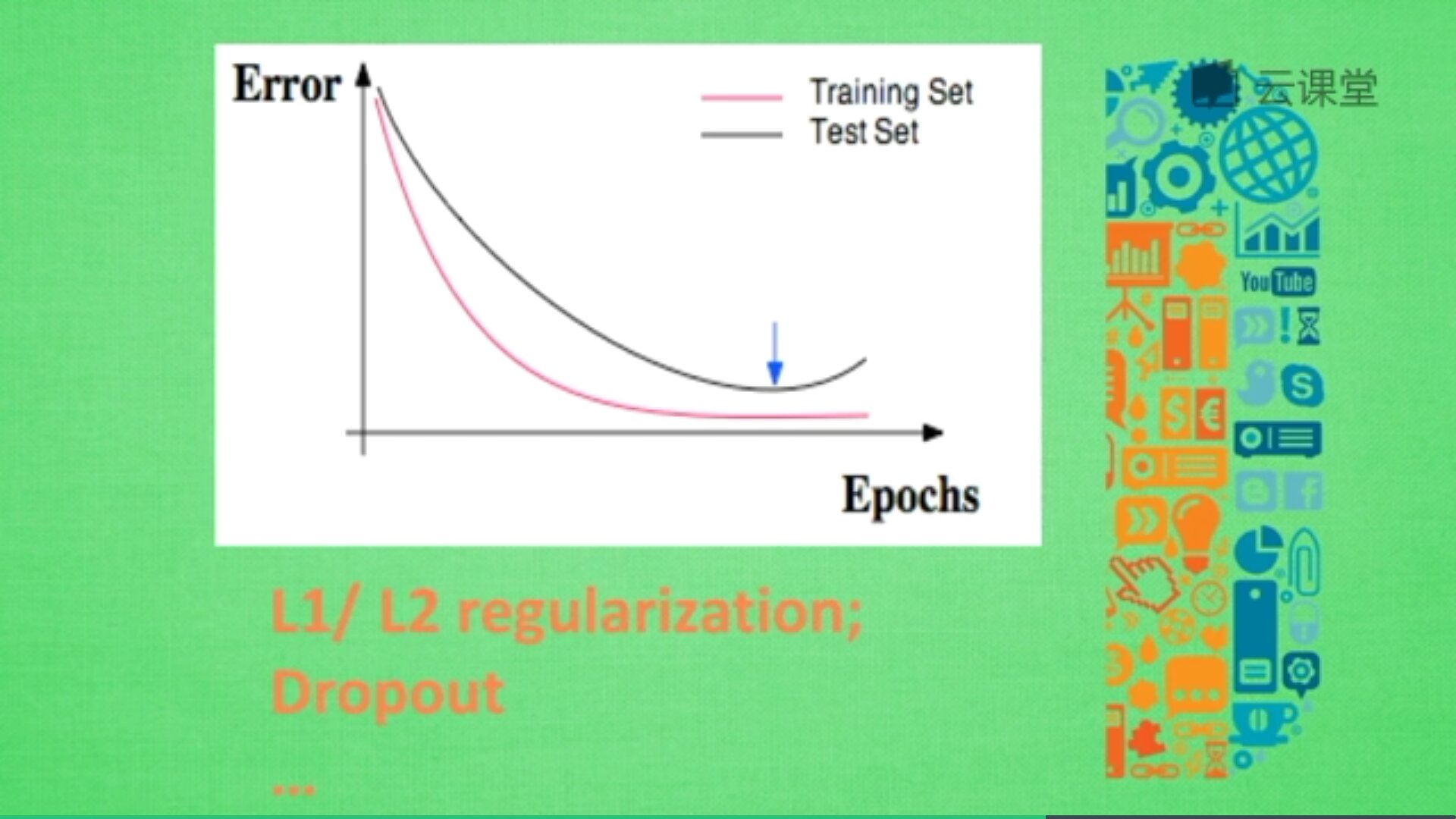
有时候意外猝不及防,作业题明明会做,但是考试却不理想,因为我们只复习了作业题,而没有深入拓展作业反映的知识。这样的问题也会发生在机器学习中,我们称为过拟合。简言之,过拟合就是训练样本得到的输出和期望输出基本一致,但是测试样本的输出和测试样本的期望输出相差却很大 。当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,我们称过拟合发生了。这意味着训练数据中的噪音或者随机波动也被当做概念被模型学习了。而问题就在于这些概念不适用于新的数据,从而导致模型泛化性能的变差。
下图是经典的误差曲线,红色曲线为训练误差,黑色曲线为测试误差,训练误差校友测试误差,但由于过于依赖平时作业,考试成绩不理想,没把知识拓展开来。
机器学习中解决过拟合方法有很多,常用的包括L1/L2 Regularization(正规化)、Dropout等。
代码详见前一篇博客:[Python人工智能] 五.theano实现神经网络正规化Regularization处理
交叉验证:
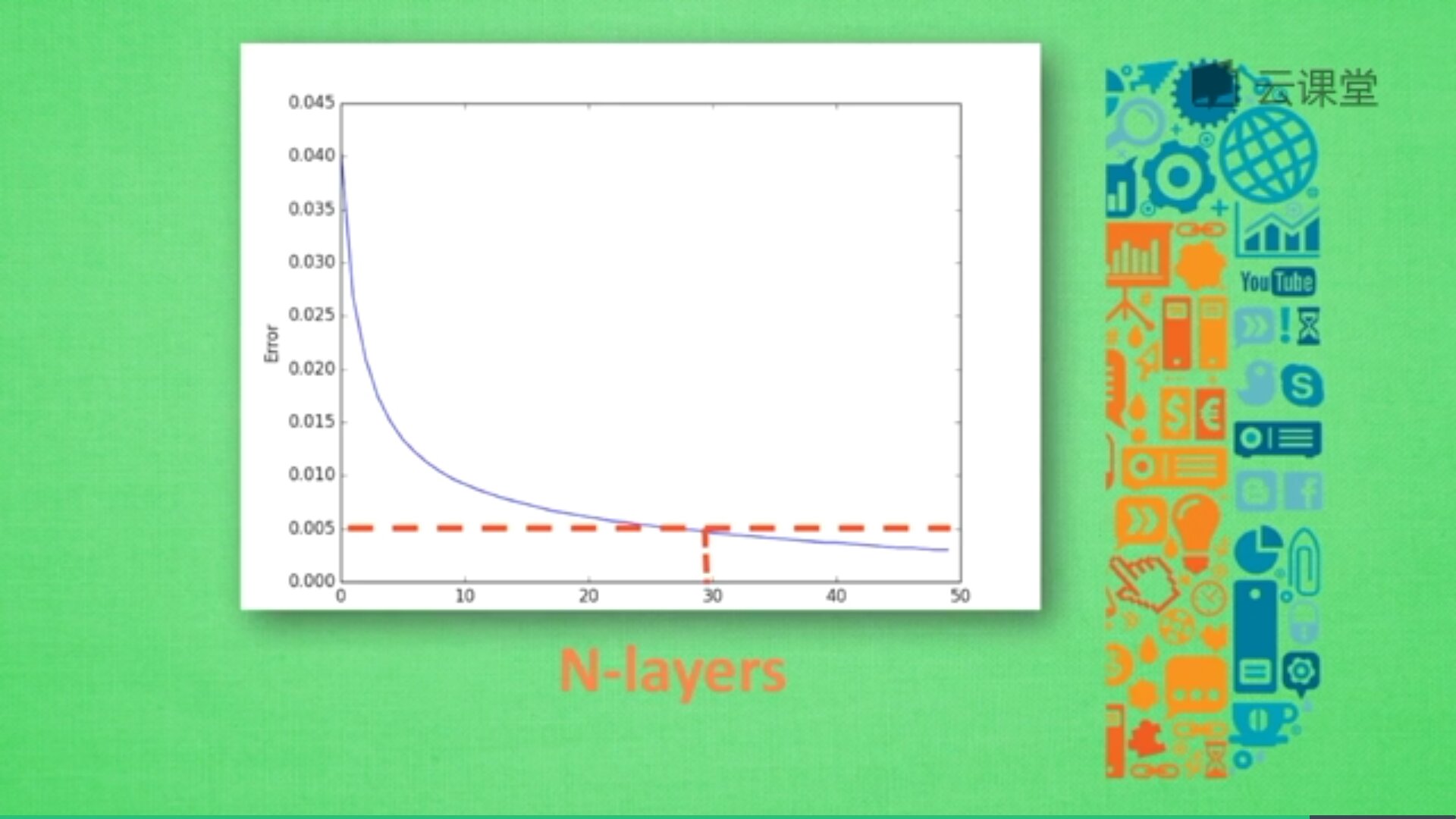
神经网络中有很多参数,我们怎么确定哪些参数更有效解决现有问题呢?这时候交叉验证是最好的途径。交叉验证不仅可以用于神经网络调参,还可以用于其他机器学习的调参。例如:X轴为学习率(Learning rate)、神经网络层数(N-layers),Y轴为Error或精确度,不同神经层数对应的误差值或精准度也不同。

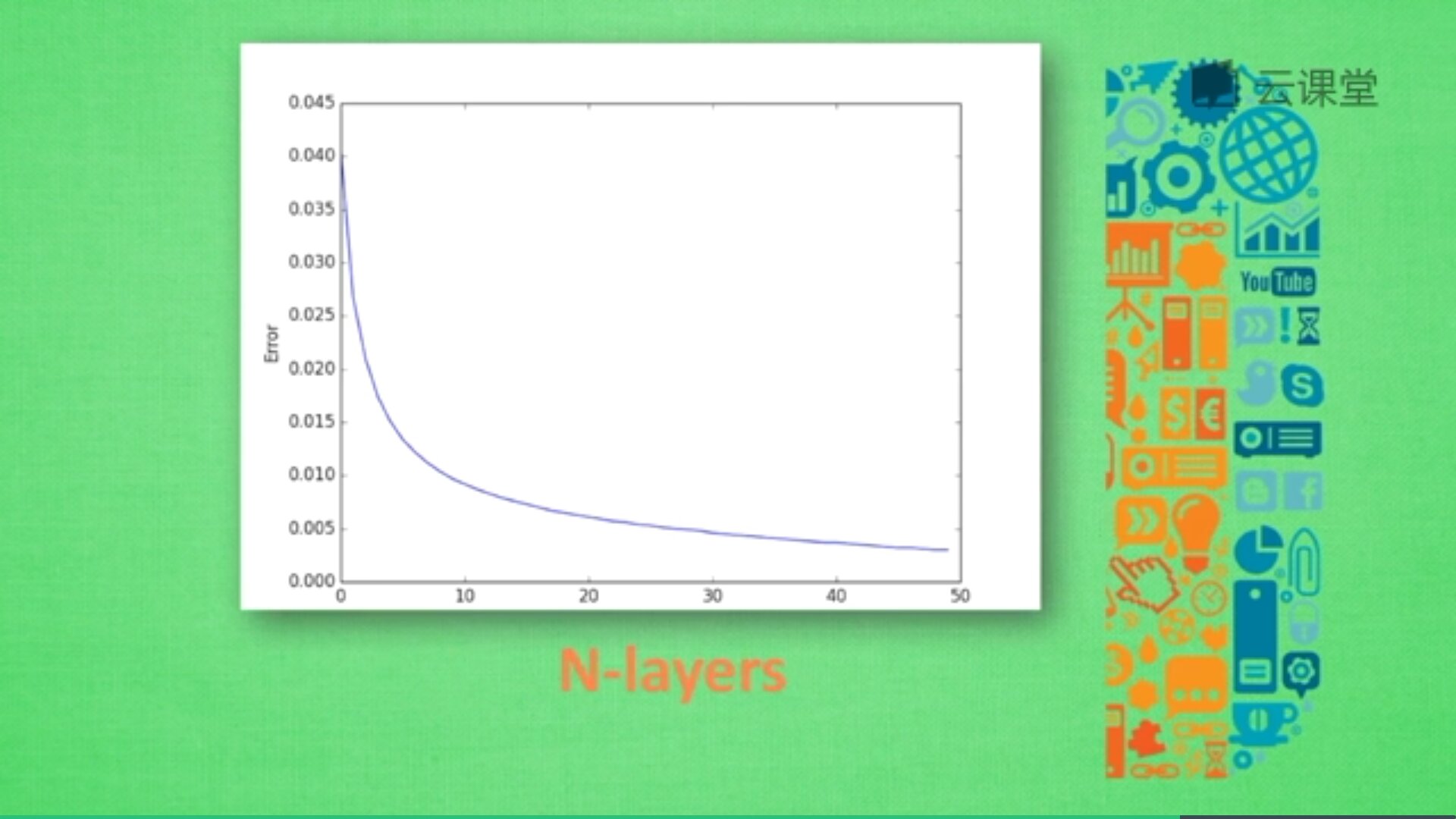
由于神经层数目越多,计算机消耗的时间也会增加,所以只需要找到满足误差要求又能节约时间的层结构即可。例如,当误差在0.005以下时都能接收,则采用30层(N-layers=30)的结构即可。
二. 特征标准化
特征标准化(Feature Normalization)又称为正常化或归一化。为什么需要进行特征标准化呢?
为了让机器学习更好地消化,我们需要对数据动些手脚,这就包括特征标准化。现实中,数据来自不同的地方,有不同的规格,被不同人采集。比如房价预测数据,房屋特征可能包括:离市中心距离、楼层数目、房屋面积、所在城市等。

假设用线性回归来做预测,方程可能为:价格 = a*离市中心 + b*楼层 + c*面积
机器学习要求出a、b、c,然后预测价格,其误差定义为:误差 = 预测值 - 实际价格

接着需要对误差进行数据处理,使之变成进步的阶梯,然后反向传递a、b、c,提升下一次的精确度。
那么,这些概念和标准化又有什么关系呢?
我们可以把 a、b、c 想象成三个人,他们共同努力解决一个问题。在该问题中,a工作时总是不知道发生了什么,b的能力适中,c的能力最强。老板看了以后,说你们的结果和我期望的还有些差距,你们快去缩小差距。老板给出的要求是缩小差距,可是a、b、c不知道如何缩小差距,不知道差距在哪?他们只好平分任务,c很快就完成了,b要慢点,a最慢,但总时间很长,c、b需要等a把工作完成才给老板看结果。

这样的效率并不高,把这个问题放到机器学习中,怎么解决呢?
为了方便理解,我们先把b去除掉,留下两个特征属性,如下:价格 = a*离市中心 + c*面积
其中离市中心距离一般0-10取值,而面积一般100-300取值,在公式中,c只要稍微变化一点,它对价格的影响很大,而a变化对价格的影响不会像c那么大,这样的差别会影响最终的效率,所以我们需要进行特征标准化处理,从而提升效率。

我们在机器学习之前,先对数据预先处理一下,对取值跨度大的数据浓缩一下,跨度小的数据扩展一下,使得他们的跨度尽量统一,通常有两种方法:
1.minmax normalization
它们会将所有数据按照比例缩放到0到1之间,有的也可以是-1到1区间。
2.std normalization
它会将所有数据浓缩成平均值为0,方差为1的数据。
通过这些标准化手段,我们不仅能加快机器学习的学习速度,还可以避免机器学习学得特别扭曲。

minmax normalization标准化方法代码如下(参考前文):
#正常化处理 数据降为0-1之间
def minmax_normalization(data):
xs_max = np.max(data, axis=0)
xs_min = np.min(data, axis=0)
xs = (1-0) * (data - xs_min) / (xs_max - xs_min) + 0
return xs 三. 特征选择
这里使用机器学习的分类器作为贯穿特征选择的例子,分类器只有你在提供好特征时,才能发挥出最好效果,这也意味着找到好的特征,才是机器学习能学好的重要前提。那么,如何区分哪些是好的特征(good feature)?你怎么知道特征是好还是坏呢?
我们在用特征描述一个物体,比如A和B两种物体中,包括两个属性长度和颜色。然后用这些属性描述类别,好的特征能够让我们更轻松的辨别出相应特征所代表的类别,而不好的特征会混乱我们的感官,带来一些没用的信息,浪费计算资源。
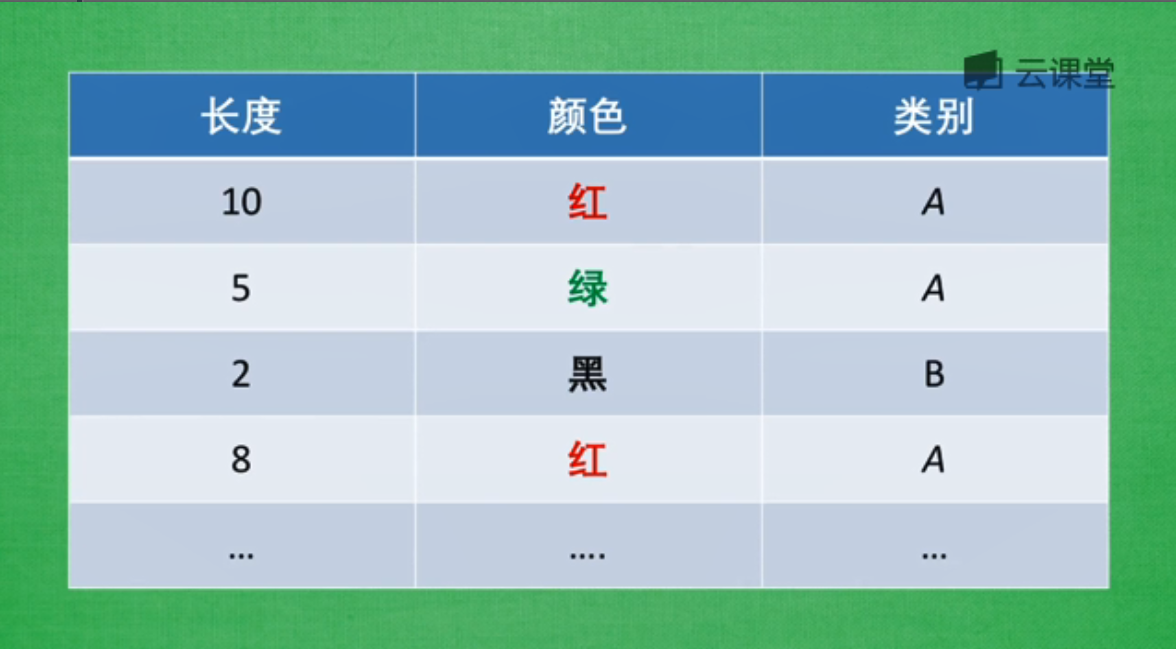
避免无意义的信息:
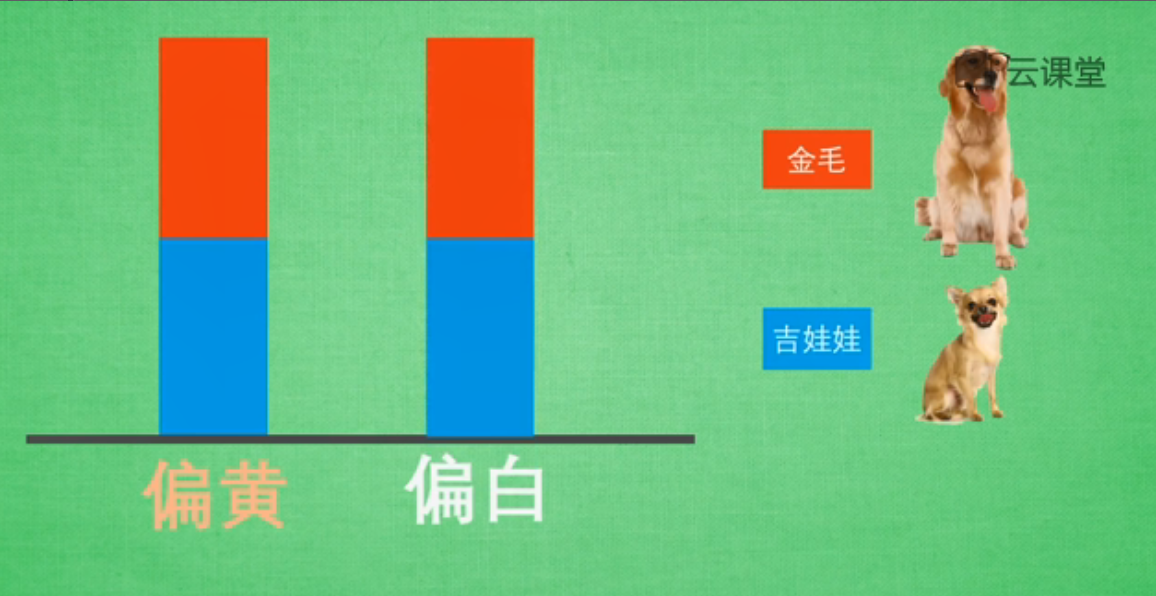
比如对比金毛和吉娃娃,它们有很多特征可以对比,比如眼睛的颜色、毛色、体重、身高等,为了简化我们的问题,我们主要观察毛色和身高这两个特征,而且我们假设这两种狗毛色仅为偏黄色或偏白色。接着我们来对比毛色,结果发现金毛和吉娃娃两种颜色的比例各占一半。


然后我们将它们用数据形式展现出来,假设只有两种颜色(偏黄、偏白),用红色表示金毛,蓝色表示吉娃娃,两种狗所占比例各为一半。该数据说明:给你一只毛色偏黄的特征,你是无法判断这只狗是金毛还是吉娃娃的,这就意味着通过毛色判断两种狗的品种是不恰当的,这个特征在区分品种上没有起到作用,我们要避免这种无意义的特征信息。
接下来我们尝试用身高来进行分类,使用Python可视化来进行实验。
----------------------------------------------------------------------------------
import matplotlib.pyplot as plt
import numpy as np
#定义400个样本
gold, chihh = 400, 400
#平均身高假设为40厘米加上一个随机数,金毛随机幅度稍微大些,吉娃娃小些
gold_height = 40 + 10 * np.random.randn(gold)
chihh_height = 25 + 6 * np.random.randn(gold)
#柱状图可视化显示这些高度数据,红色金毛高度个数,蓝色代表吉娃娃
plt.hist([gold_height, chihh_height], stacked=True, color=['r', 'b'])
plt.show()
----------------------------------------------------------------------------------
如下图所示,高度为50的红色这组数据中,基本上判断这只狗就是金毛,同样高度大于50的也是金毛;而当数据为20时,我们能够说它很可能就是吉娃娃;而高度为30的范围,我们很难判断它是金毛还是吉娃娃,因为两种狗都存在而且数量差别不大。
所以,虽然高度是一个非常有用的特征,但并不完美,这就需要我们引入更多的特征来判断机器学习中的问题。

如果要收集更多的信息,我们就要剔除那些没有意义或不能区分信息的特征,比如毛色,而高度比较有用,保留该特征;同时需要寻找更多的特征来弥补高度的不足,比如体重、跑步速度、耳朵形状等,用这些加起来的信息我们就能弥补单一特征所缺失的信息量。

有时候,我们会有很多特征信息数据,而有些特征虽然名字不同,但描述的意义却相似,比如描述距离的公里和里两种单位,虽然它们在数值上并不重复,但都表示同一个意思。在机器学习中,特征越多越好,但是把这两种信息都放入机器学习中,它并没有更多的帮助。

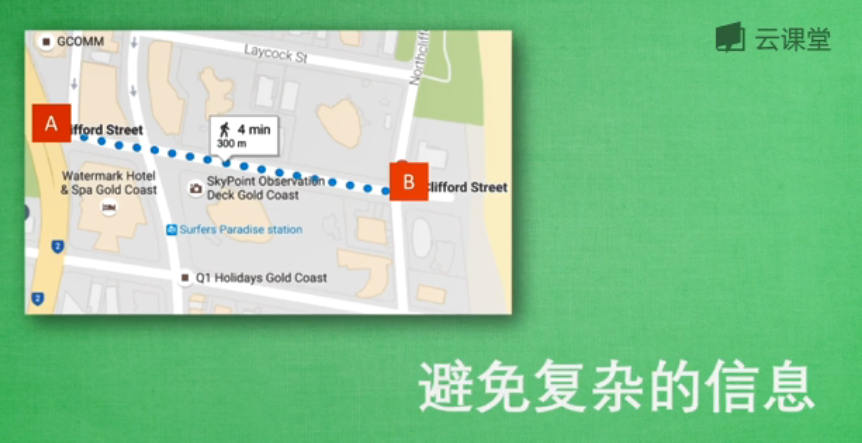
避免复杂性特征:
同样在这张图片中,如果从A到B,有两种方式可供选择,一种是经纬度,另一种是AB之间的距离。虽然都属于地理为止信息,但是处理经纬度会比计算距离麻烦很多,所以我们在挑选特征时,会增加一条:避免复杂的特征。因为特征与结果之间的关系越简单,机器学习就能够更快地学习到东西,所以选择特征时,需要注意这三点:避免无意义的信息、避免重复性的信息、避免复杂的信息。
一个人如果总是自己说自己厉害,那么他就已经再走下坡路了,最近很浮躁,少发点朋友圈和说说吧,更需要不忘初心,砥砺前行。珍惜每一段学习时光,也享受公交车的视频学习之路,加油,最近兴起的傲娇和看重基金之心快离去吧,平常心才是更美,当然娜最美,早安。
(By:Eastmount 2018-06-12 深夜1点 http://blog.csdn.net/eastmount/ )