从本篇文章开始,作者正式开始研究Python深度学习、神经网络及人工智能相关知识。前三篇文章讲解了神经网络基础概念、Theano库的安装过程及基础用法、theano实现回归神经网络、theano实现分类神经网络,这篇文章又回到基础知识,结合莫烦大神的视频学习,讲解机器学习基础知识、神经网络基础、CNN、RNN、LSTM RNN、GAN等知识,主要是学习"莫烦大神" 网易云视频的在线笔记,后面随着深入会讲解具体的项目及应用。基础性文章和在线笔记,希望对您有所帮助,也建议大家一步步跟着学习,同时文章中存在错误或不足之处,还请海涵~
"莫烦大神" 网易云视频地址:http://study.163.com/provider/1111519/course.html
从2014年开始,作者主要写了三个Python系列文章,分别是基础知识、网络爬虫和数据分析。
- Python基础知识系列:Pythonj基础知识学习与提升
- Python网络爬虫系列:Python爬虫之Selenium+Phantomjs+CasperJS
- Python数据分析系列:知识图谱、web数据挖掘及NLP


前文参考:
[Python人工智能] 一.神经网络入门及theano基础代码讲解
[Python人工智能] 二.theano实现回归神经网络分析
[Python人工智能] 三.theano实现分类神经网络及机器学习基础
目录:
一.机器学习
二.神经网络
三.卷积神经网络
四.循环神经网络
五.LSTM RNN
六.自编码
七.GAN
一.机器学习
首先第一部分也是莫烦老师的在线学习笔记,个人感觉挺好的基础知识,推荐给大家学习。对机器学习进行分类,包括:
1.监督学习:通过数据和标签进行学习,比如从海量图片中学习模型来判断是狗还是猫,包括分类、回归、神经网络等算法;

2.无监督学习:只有数据没有类标,根据数据特征的相似性形成规律,比如不知道类标的情况进行分类猫或狗,常见的聚类算法(物以类聚);

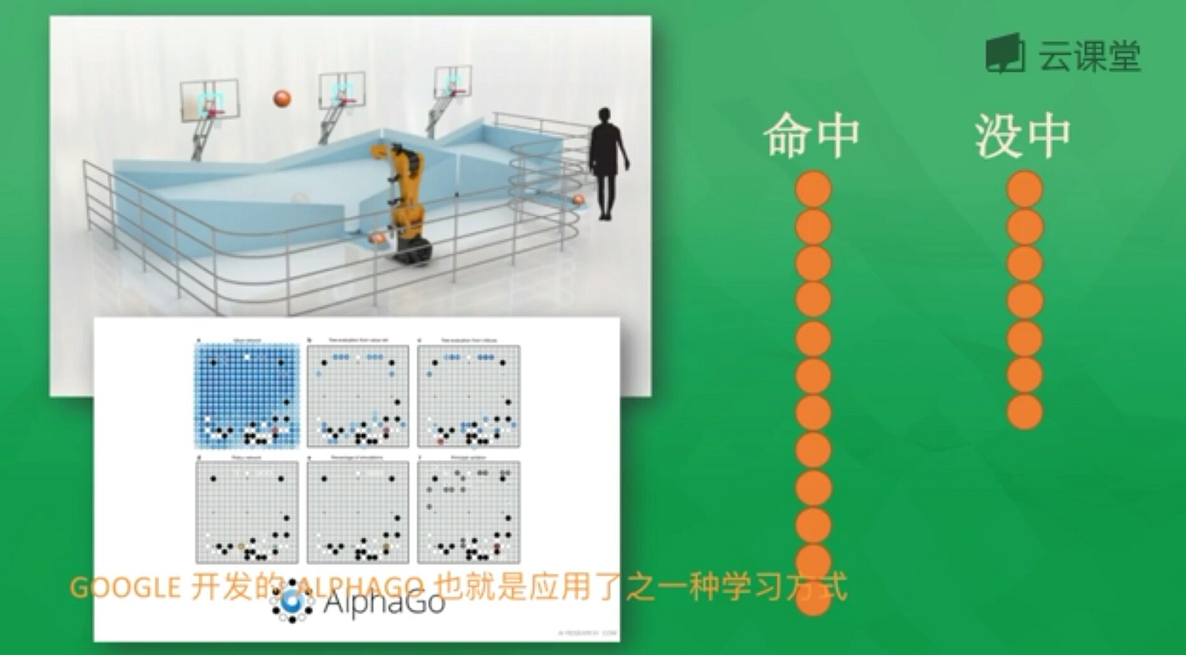
4.强化学习:常用于规划机器人行为准则,把计算机置于陌生环境去完成一项未知任务,比如投篮,它会自己总结失败经验和投篮命中的经验,进而惩罚或奖励机器人从而提升命中率,比如阿尔法狗;
二.神经网络
神经网络也称为人工神经网络ANN(Artifical Neural Network),是80年代非常流行的机器学习算法,在90年代衰退,现在随着"深度学习"和"人工智能"之势重新归来,成为最强大的机器学习算法之一。
神经网络是模拟生物神经网络结构和功能的计算模型,由很多神经层组成,每一层存在着很多神经元,这些神经元是识别事物的关键。神经网络通过这些神经元进行计算学习,每个神经元有相关的激励函数(sigmoid、Softmax、tanh等),包括输入层、隐藏层(可多层或无)和输出层,当神经元计算结果大于某个阈值时会产生积极作用(输出1),相反产生抑制作用(输出0),常见的类型包括回归神经网络(画线拟合一堆散点)和分类神经网络(图像识别分类)。
如下图所示,它表示的是一个人工神经细胞。其中: 输入(Inputs):神经细胞的输入;权重(Weight):左边五个灰色圆底字母w代表浮点数;激励函数(Activation Function):大圆,所有经过权重调整后的输入加起来,形成单个的激励值;输出(Output):神经细胞的输出。
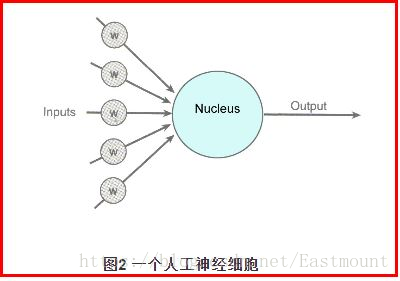
进入人工神经细胞的每一个input(输入)都与一个权重w相联系,正是这些权重将决定神经网络的整体活跃性。假设权重为-1和1之间的一个随机数,权重可正可负(激发和抑制作用)。当输入信号进入神经细胞时,它们的值将与它们对应的权重相乘,作为图中大圆的输入。如果激励值超过某个阀值(假设阀值为1.0),就会产生一个值为1的信号输出;如果激励值小于阀值1.0,则输出一个0。这是人工神经细胞激励函数的一种最简单的类型。涉及的数学知识如下图所示:

如果最后计算的结果激励值大于阈值1.0,则神经细胞就输出1;如果激励值小于阈值则输出0。这和一个生物神经细胞的兴奋状态或抑制状态是等价的。
下面简单讲解"莫烦大神"网易云课程的一个示例。假设存在千万张图片,现在需要通过神经网络识别出某一张图片是狗还是猫,如下图所示共包括输入层、隐藏层(3层)和输出层。
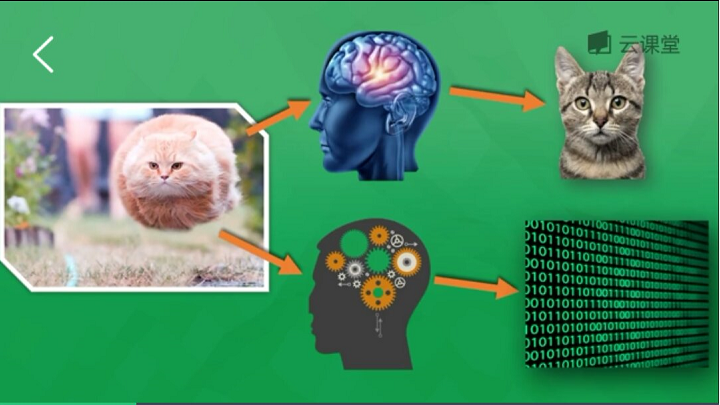
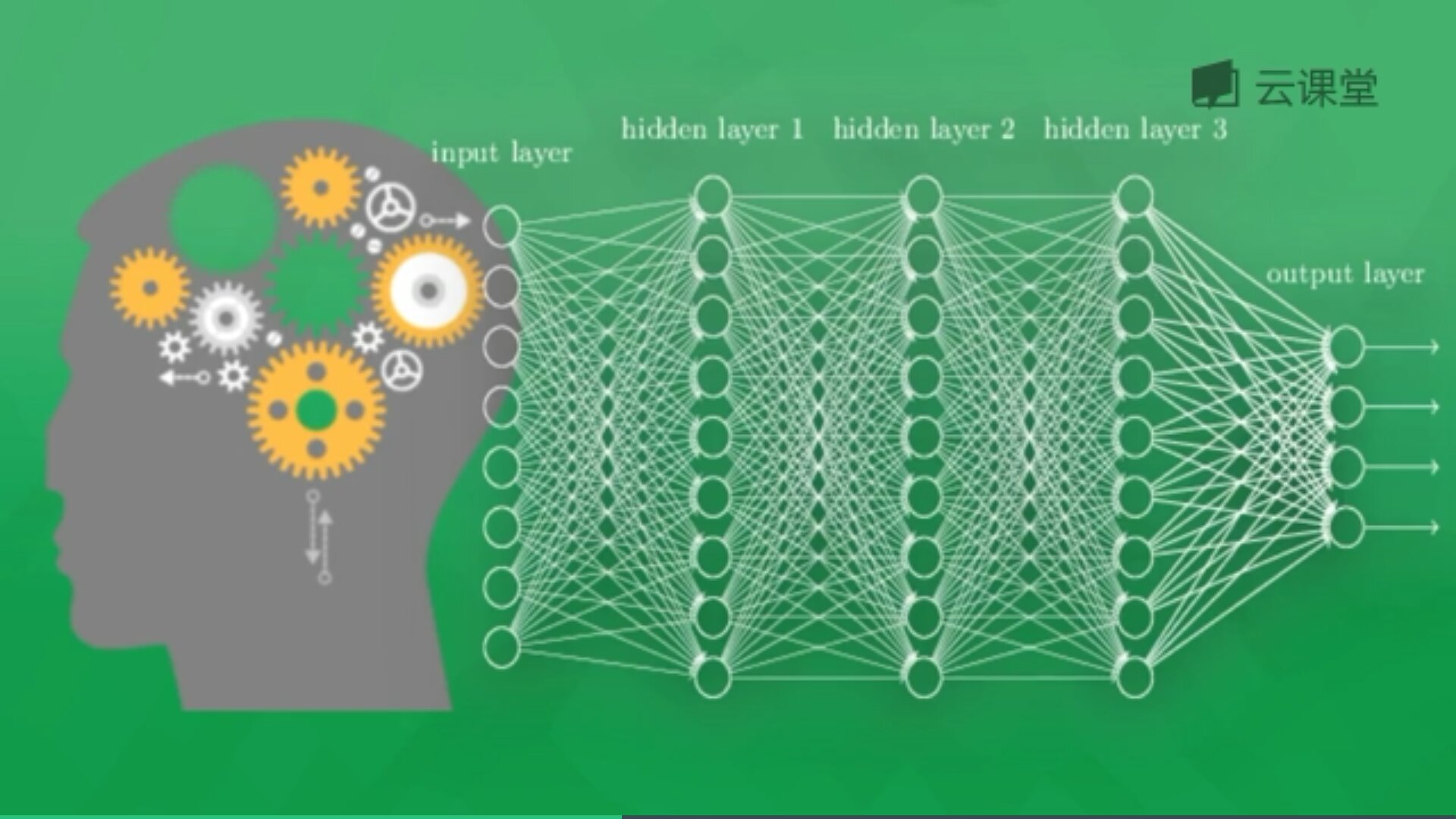

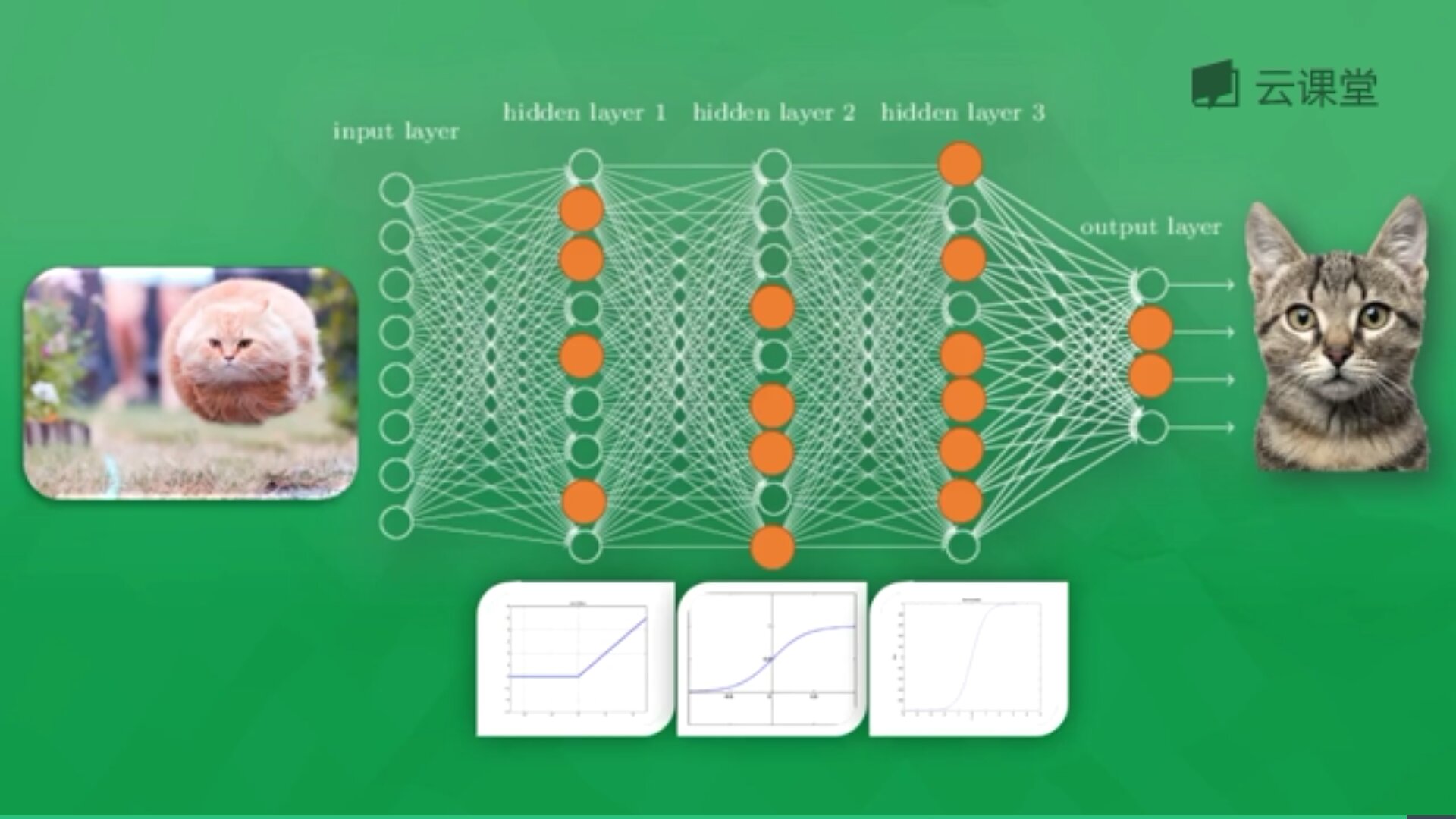
每一个神经元都有一个激励函数,被激励的神经元传递的信息最有价值,它也决定最后的输出结果,经过海量数据的训练,最终神经网络将可以用于识别猫或狗。
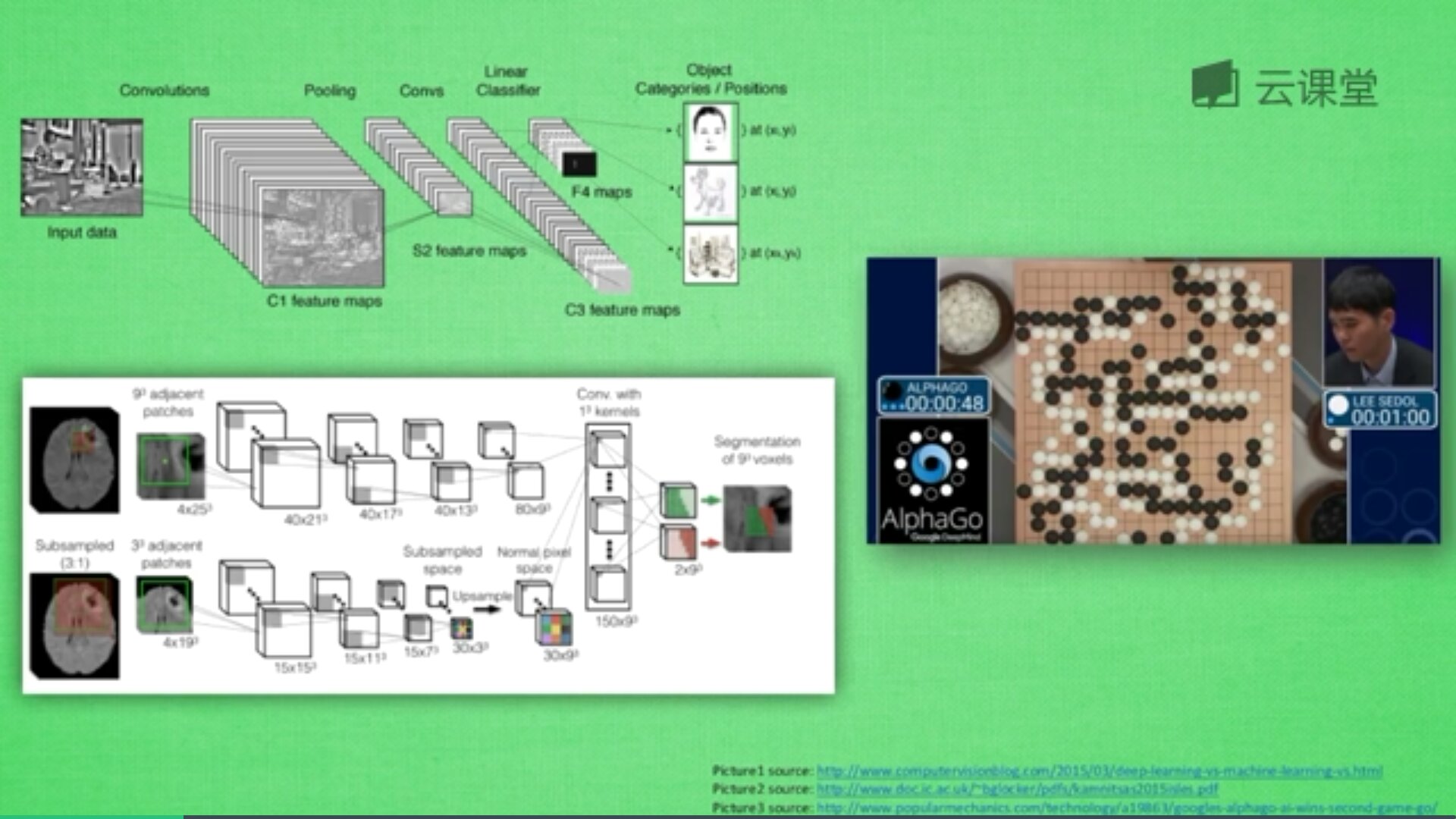
三. 卷积神经网络
卷积神经网络英文是Convolutional Neural Network,简称CNN。它通常应用于图片识别和语音识等领域,并能给出更优秀的结果,也可以应用于视频分析、机器翻译、自然语言处理、药物发现等领域。著名的阿尔法狗让计算机看懂围棋就是基于卷积神经网络的。
神经网络是由很多神经层组成,每一层神经层中存在很多神经元,这些神经元是识别事物的关键,当输入是图片时,其实就是一堆数字。
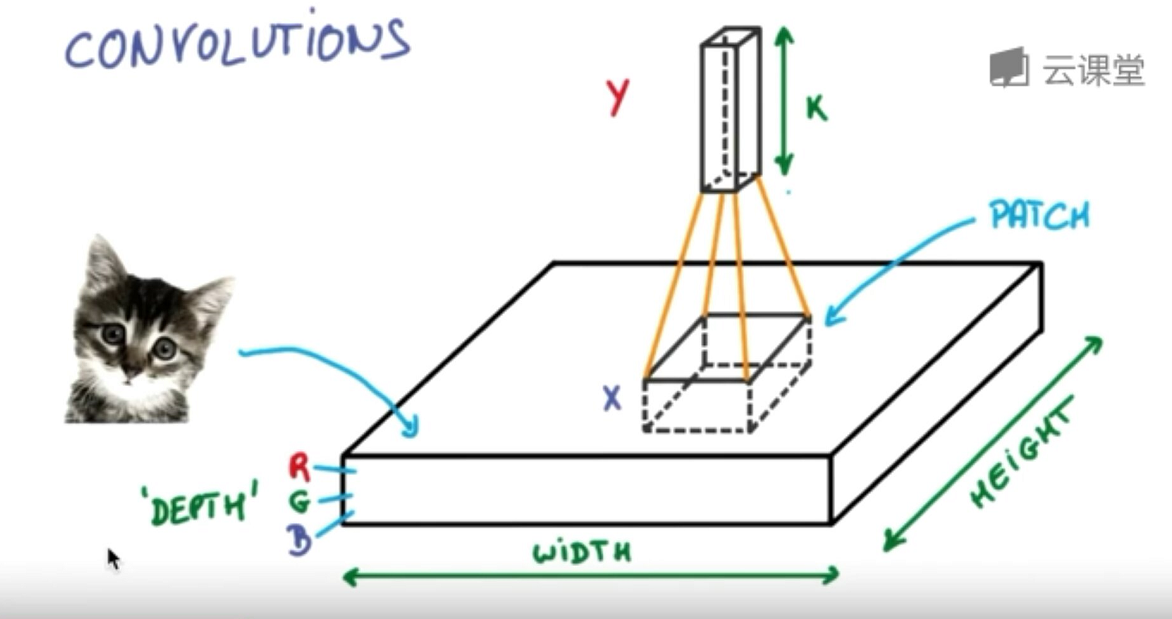
首先,卷积是什么意思呢?卷积是指不在对每个像素做处理,而是对图片区域进行处理,这种做法加强了图片的连续性,看到的是一个图形而不是一个点,也加深了神经网络对图片的理解。
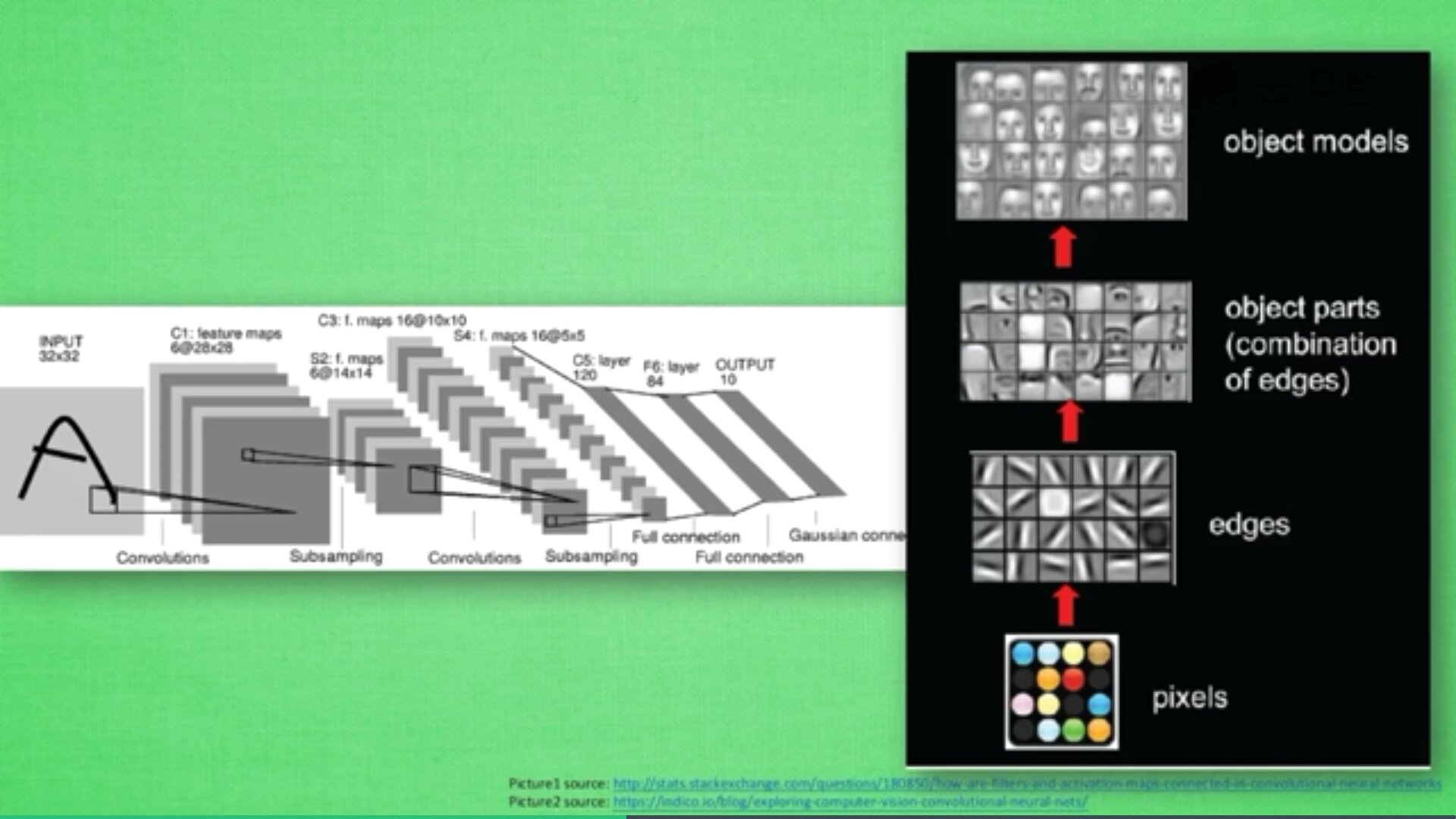
卷积神经网络批量过滤器,持续不断在图片上滚动搜集信息,每一次搜索都是一小块信息,整理这一小块信息之后得到边缘信息。比如第一次得出眼睛鼻子轮廓等,再经过一次过滤,将脸部信息总结出来,再将这些信息放到全神经网络中进行训练,反复扫描最终得出的分类结果。如下图所示,猫的一张照片需要转换为数学的形式,这里采用长宽高存储,其中黑白照片的高度为1,彩色照片的高度为3(RGB)。
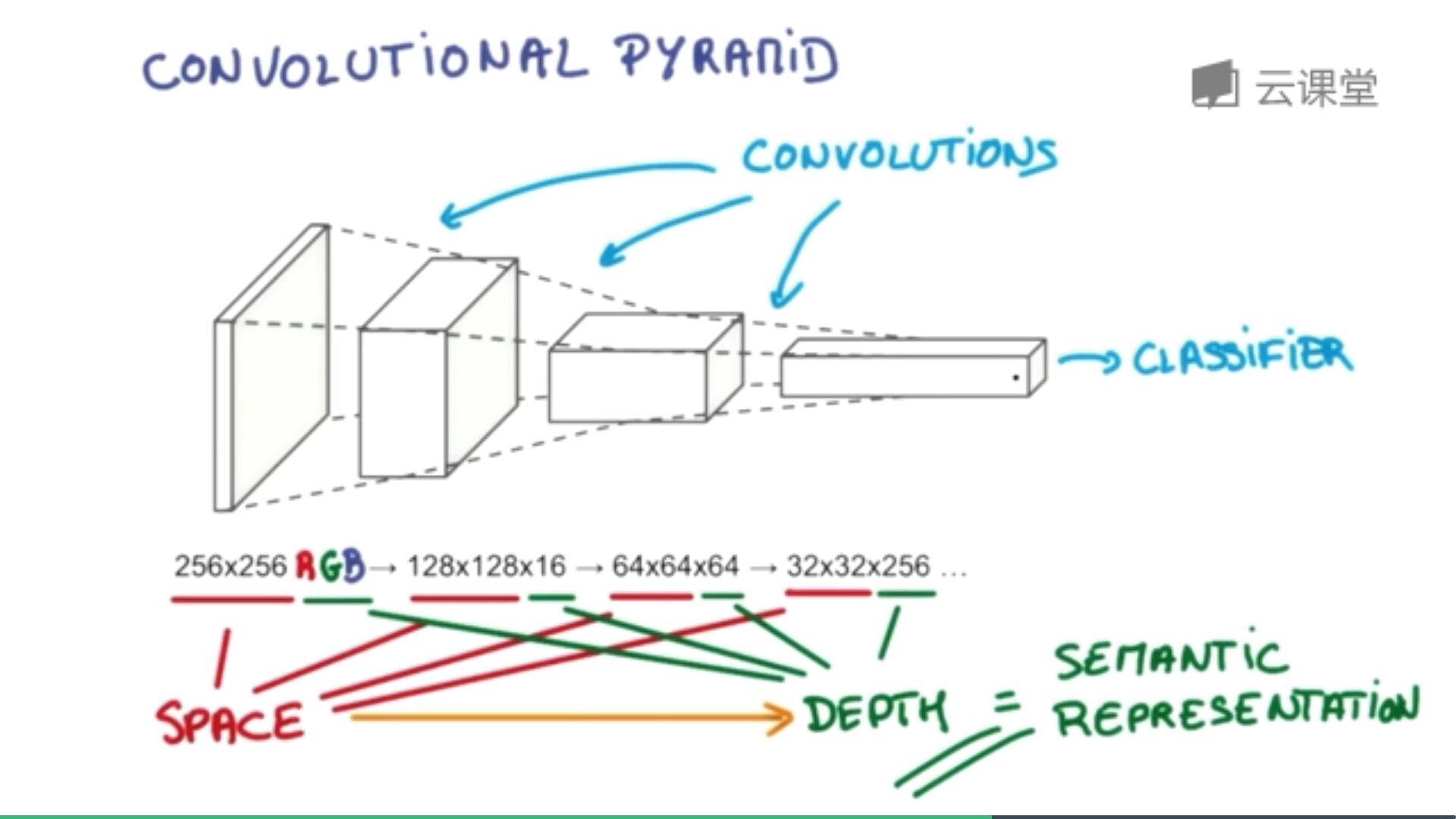
过滤器搜集这些信息,将得到一个更小的图片,再经过压缩增高信息嵌入到普通神经层上,最终得到分类的结果,这个过程即是卷积。如下图所示,它将一张RGB图片进行压缩增高,得到一个很长的结果。
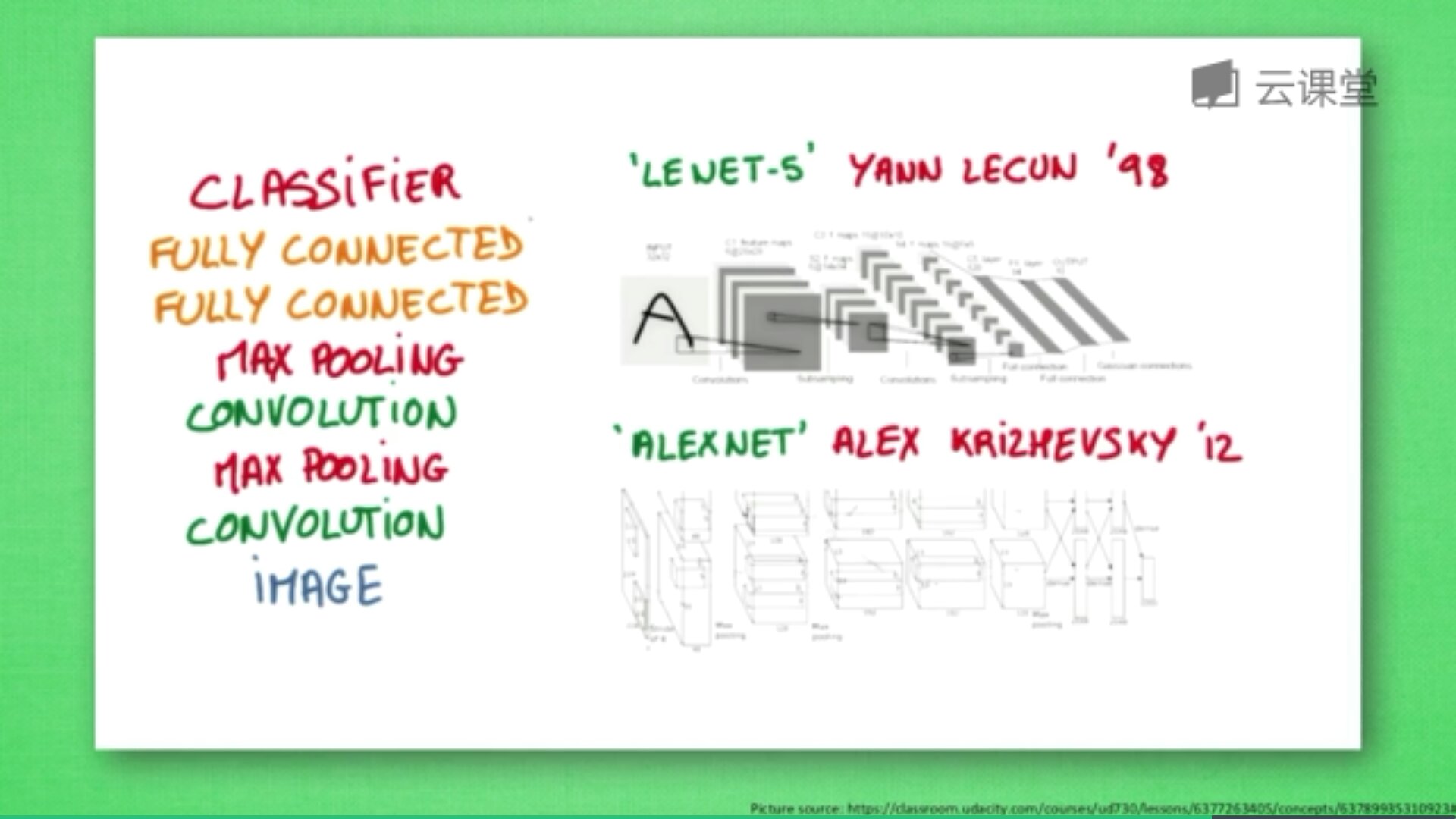
研究发现:卷积过程会丢失一些信息,POOLING(持化2)能解决这些问题,卷积时不压缩长宽,尽量保证更多信息,压缩工作交给持化。经过图片到卷积,持化处理卷积信息,再卷积再持化,将结果传入两层全连接神经层,最终通过分类器识别猫或狗。
如下图所示,从下往上依次经历“图片-卷积-持化(处理卷积信息)-卷积-持化-结果传入两层全连接神经层-分类器”的过程。
四. 循环神经网络
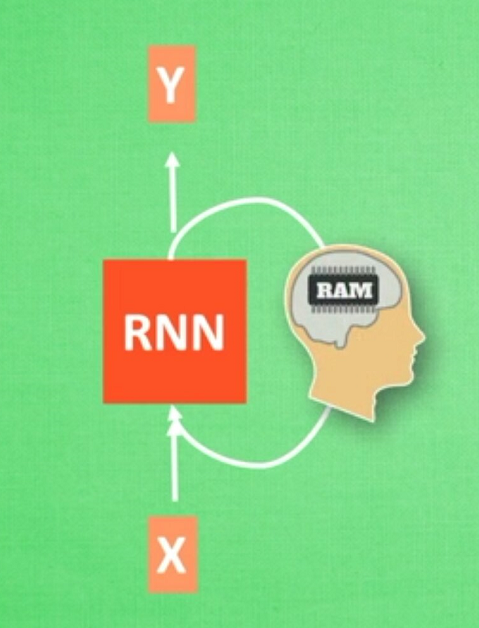
循环神经网络英文是Recurrent Neural Networks,简称RNN。假设有一组数据data0、data1、data2、data3,使用同一个NN(神经网络)预测他们,得到对应的结果。如果数据之间是有关系的,比如做菜下料的前后步骤,如何让数据之间的关联也被神经网络进行分析呢?这就要用到了RNN。
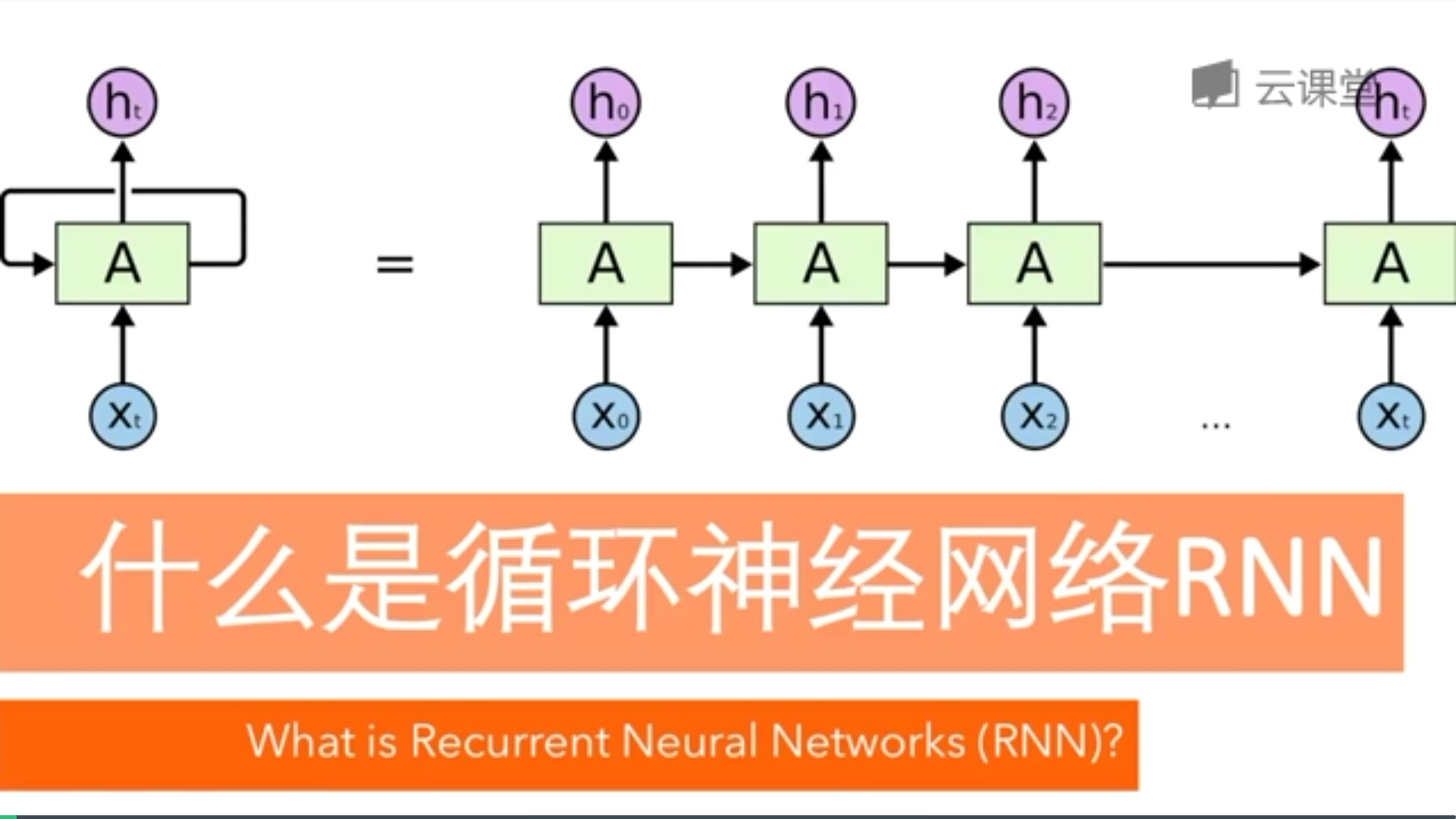
首先,想想人类是怎么分析事物之间的关联吧,人类通常记住之前发生的事情,从而帮助我们后续的行为判断,那么我们就让计算机也记住之前发生的事情吧。
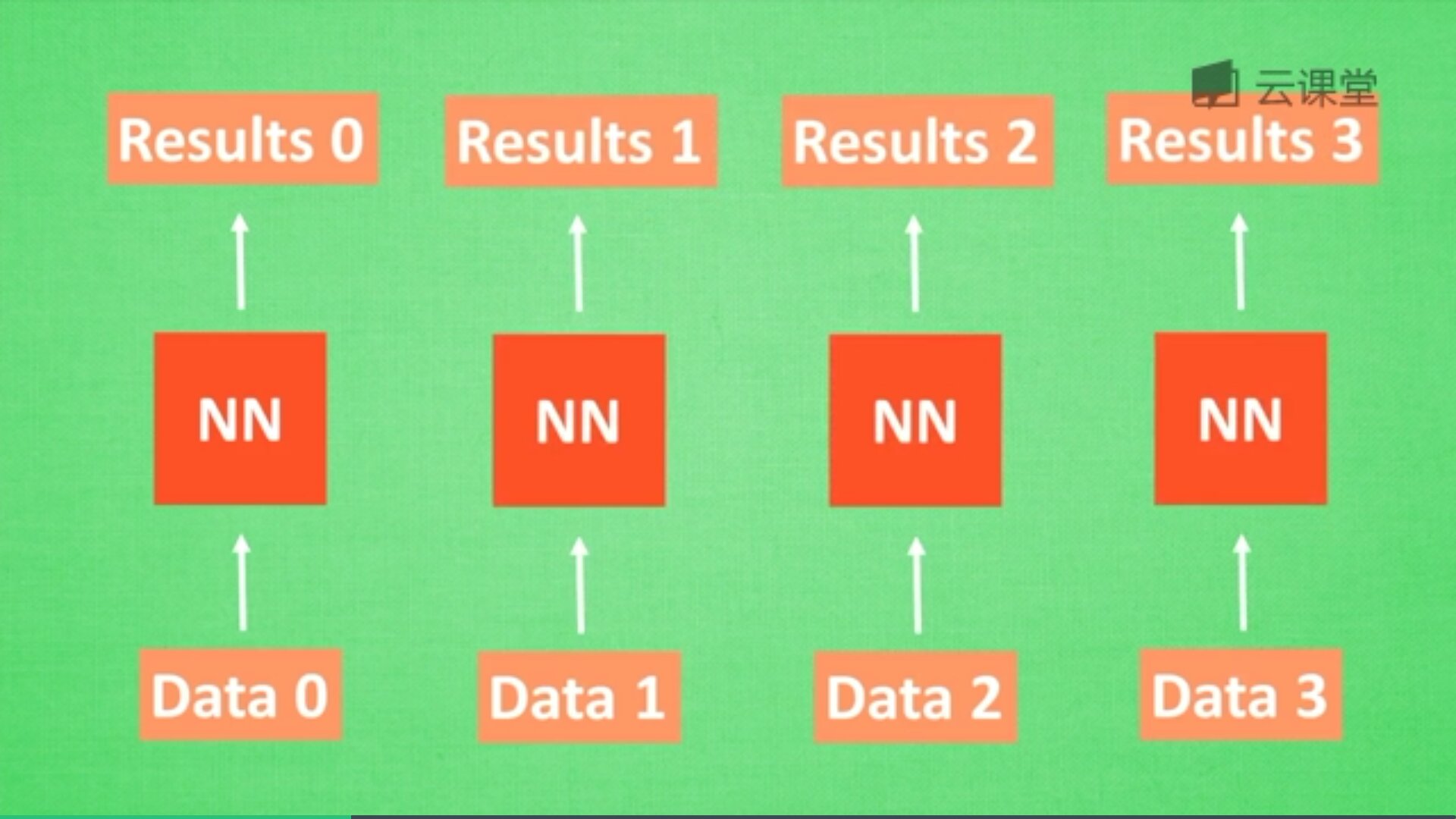
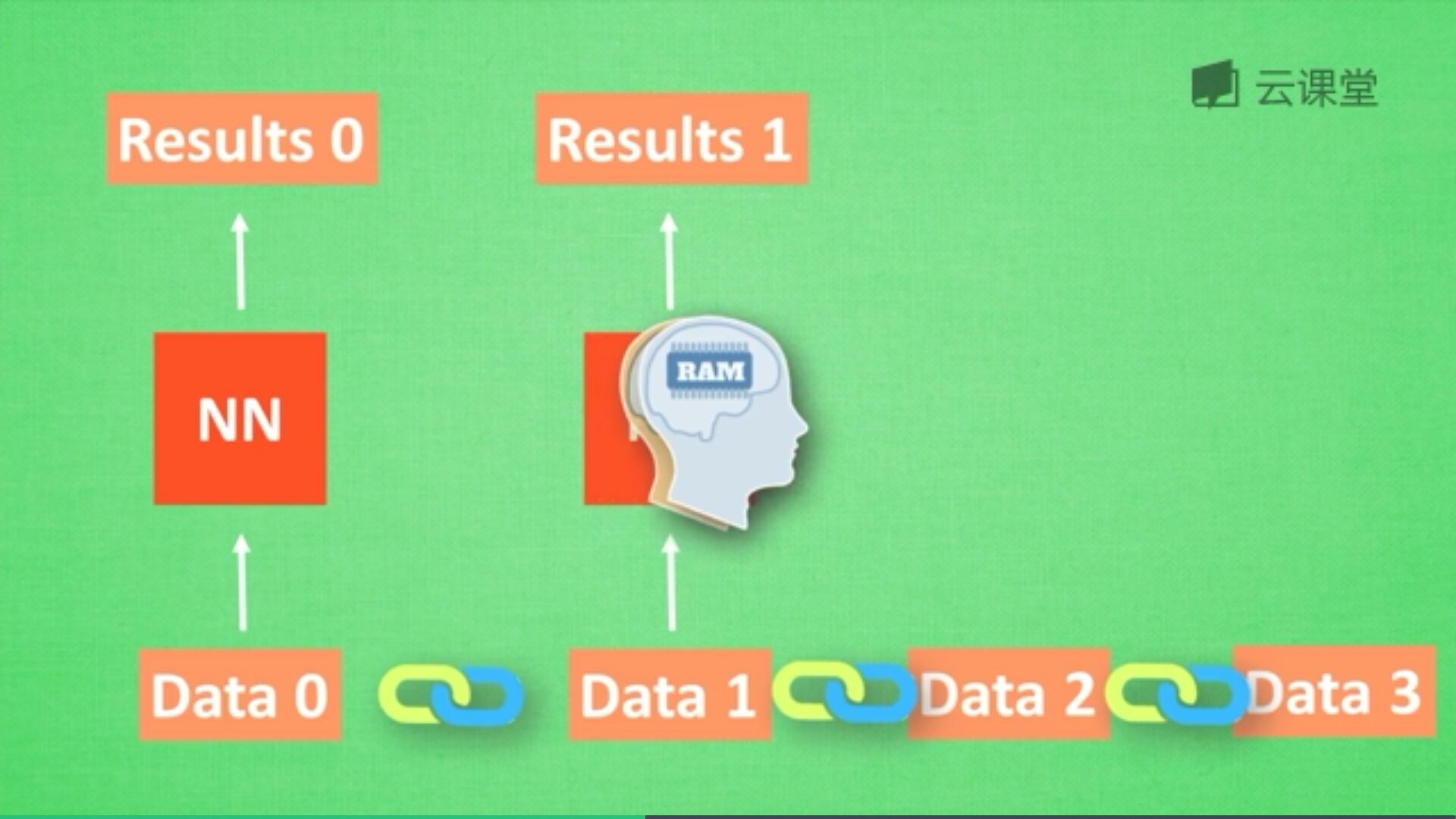
在分析data0时,我们把分析结果存入记忆,然后当分析data1时,NN会产生新的记忆,但是此时新的记忆和老的记忆没有关联,我们会简单的把老记忆调用过来分析新的记忆,如果继续分析更多的数据,NN就会把之前的记忆累积起来。
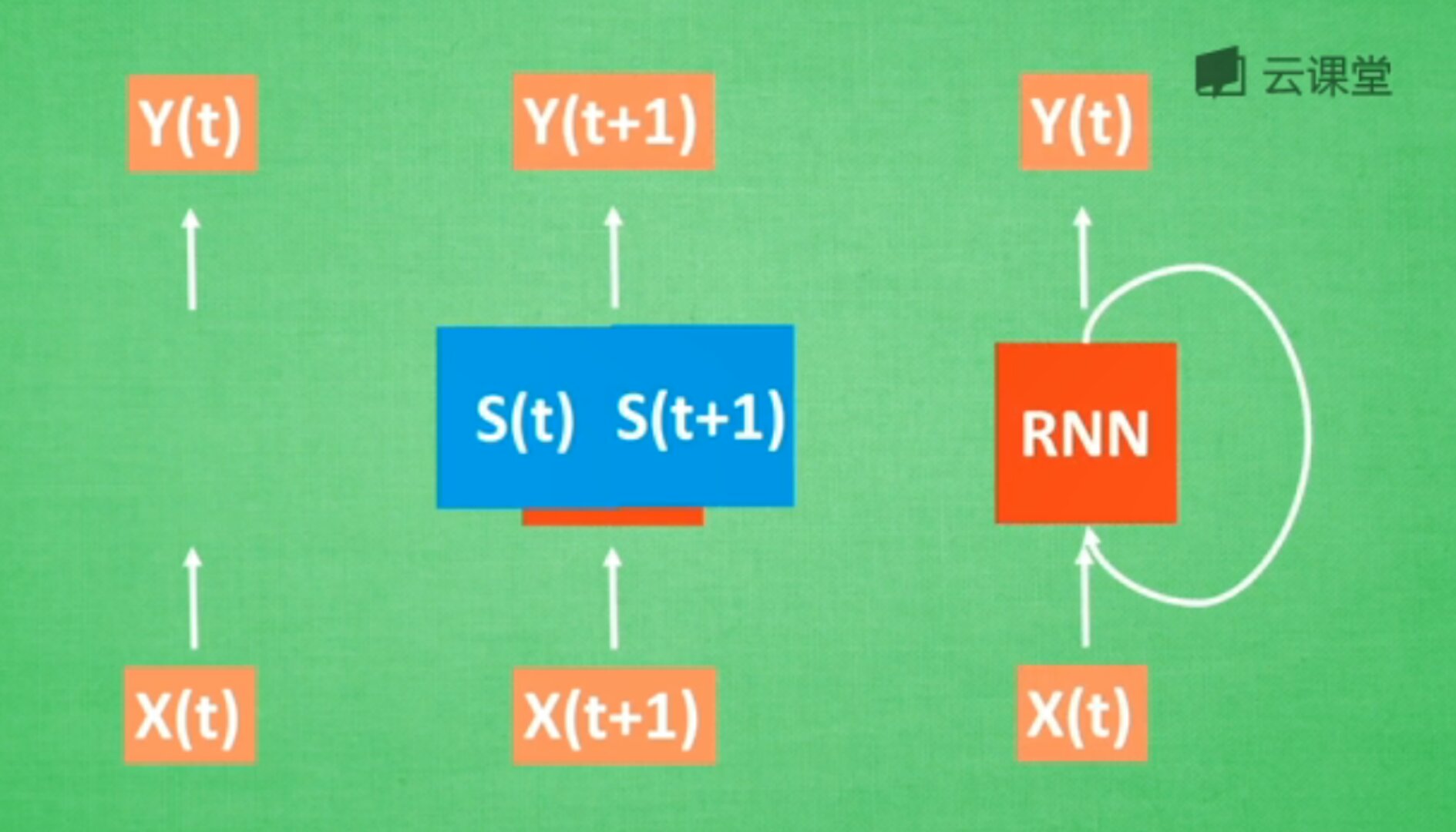
数学形式中,每次RNN运行完之后都会产生S(t),RNN分析X(t+1),而此时Y(t+1)是由S(t)和S(t+1)共同创造的,继续累加。多个NN的累积就转换为了循环神经网络,如下图的右边所示。
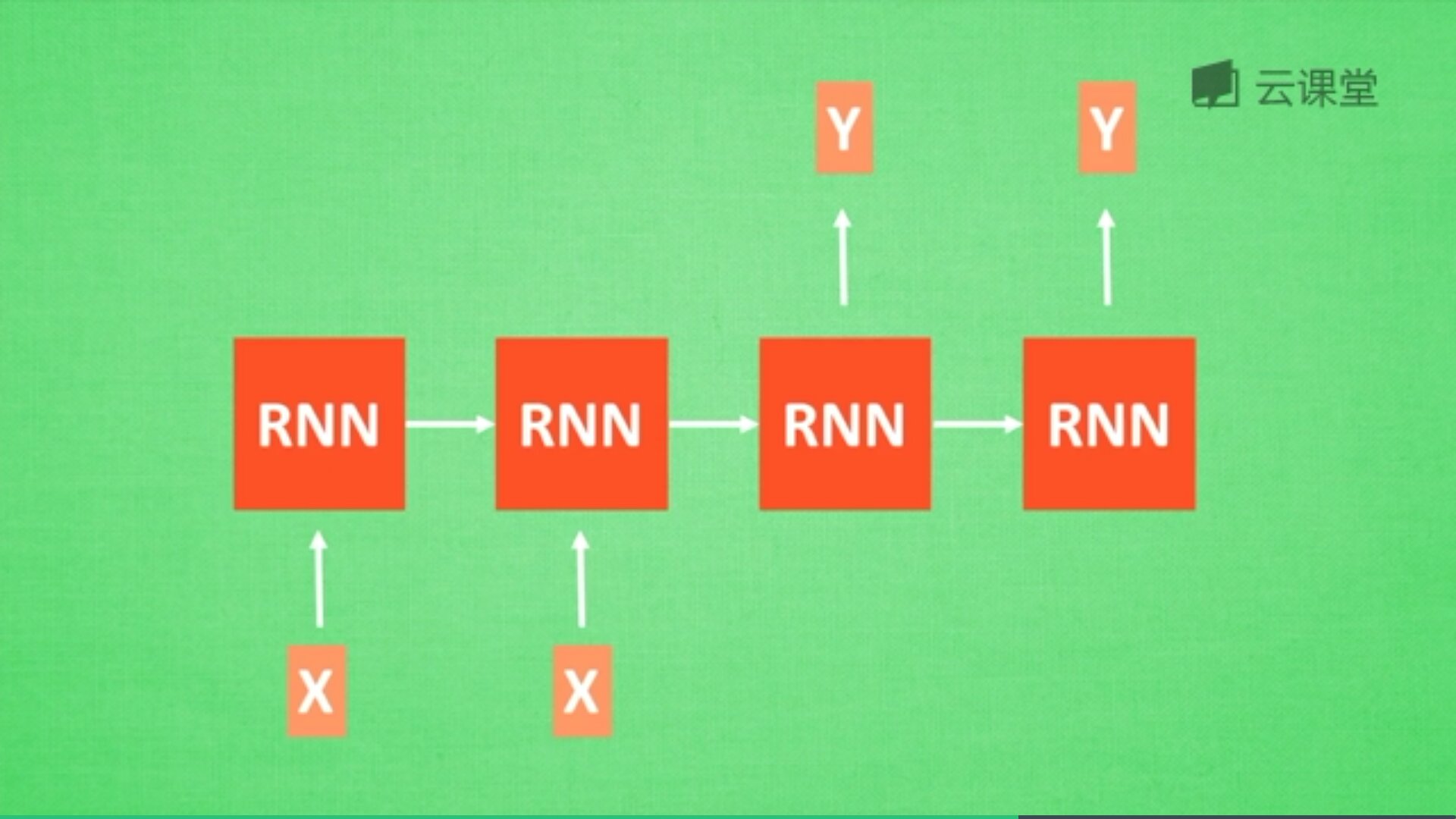
最后讲讲RNN的应用。分类,分析一个人说话情感是积极的还是消极的?它有N个输入,最后一个时间点代表输出结果的RNN。
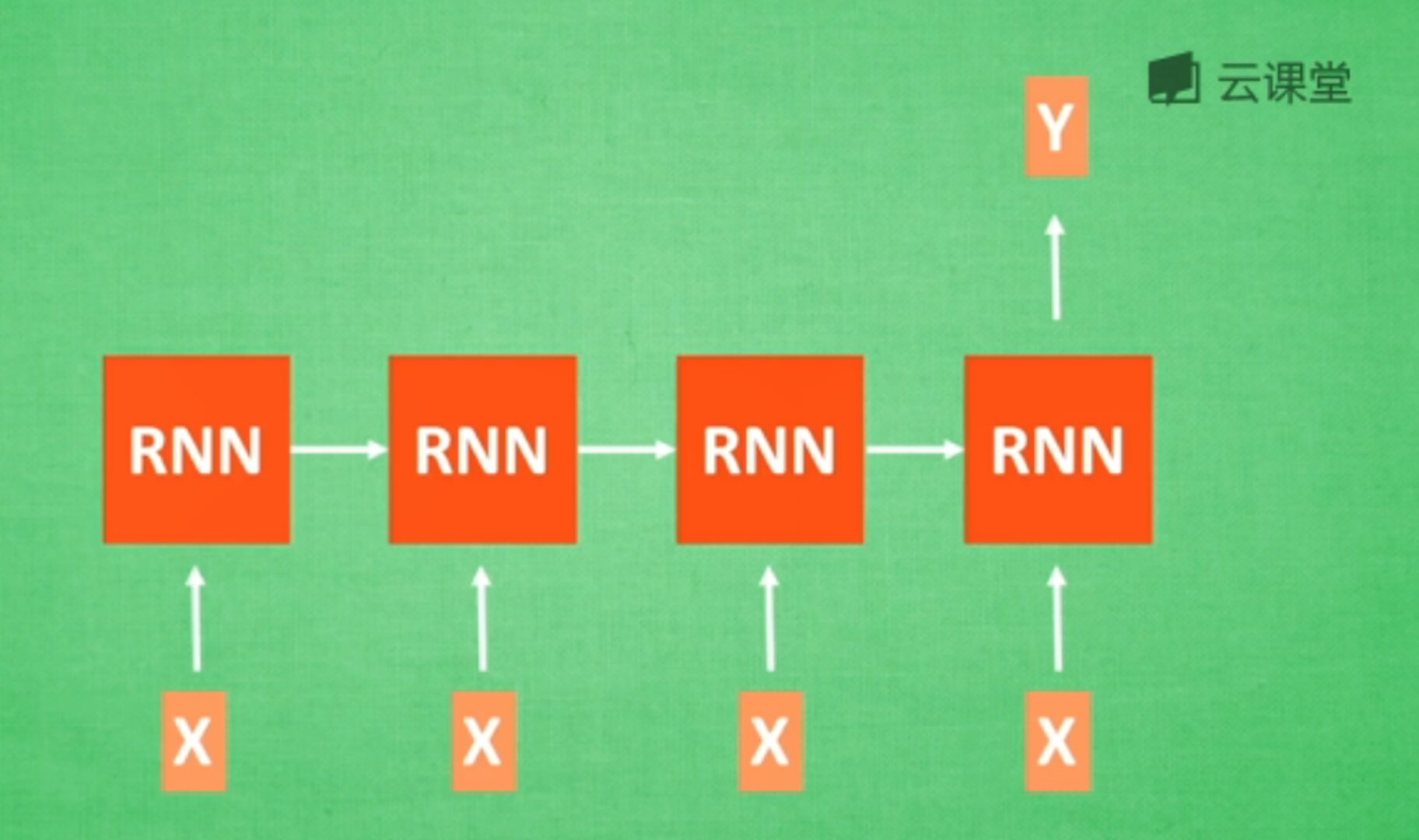
图像识别,此时有一张图片输入,N张对应的输出。
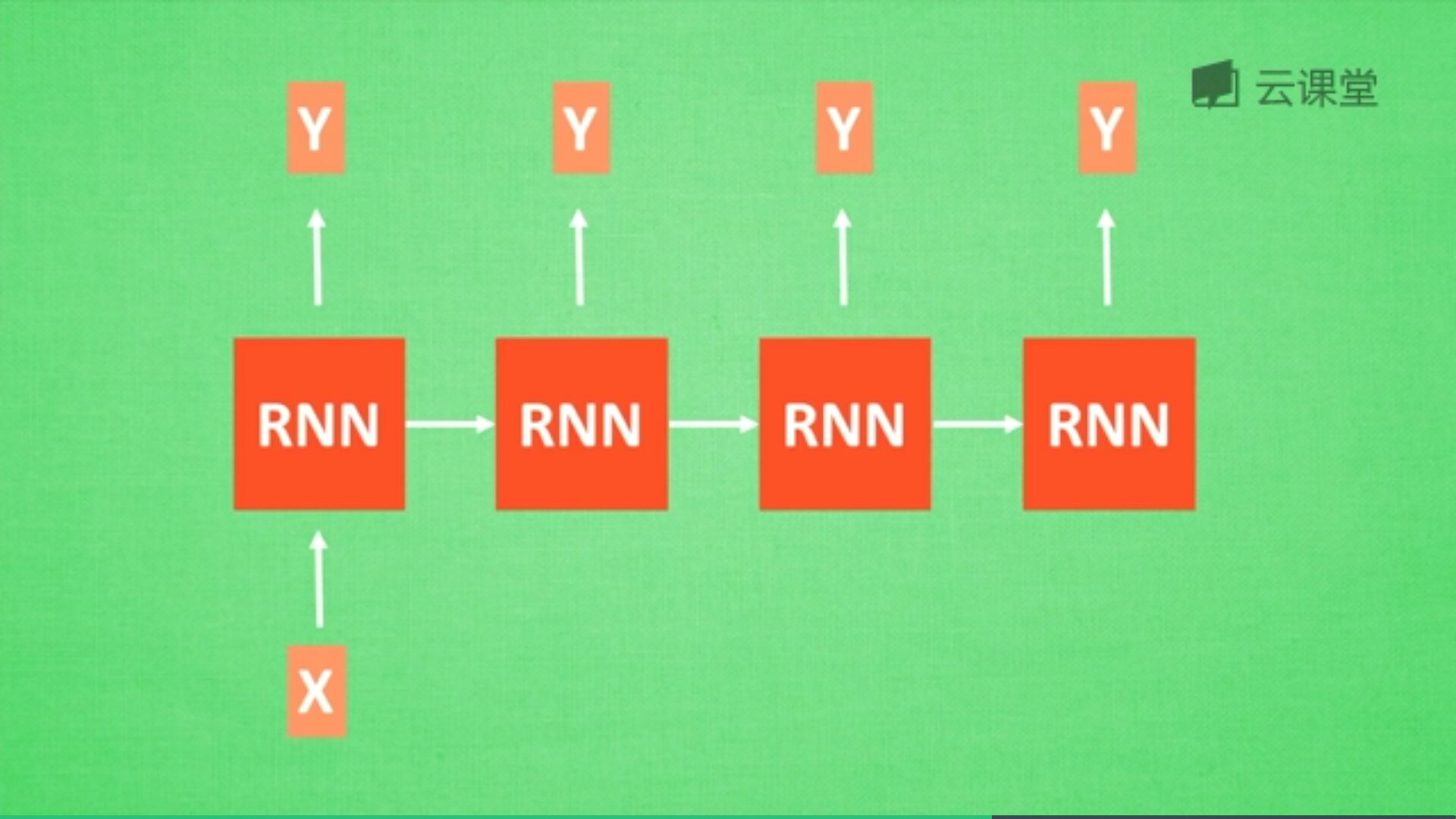
机器翻译,其中输入和输出分别两个,对应的是中文和英文,如下图所示:
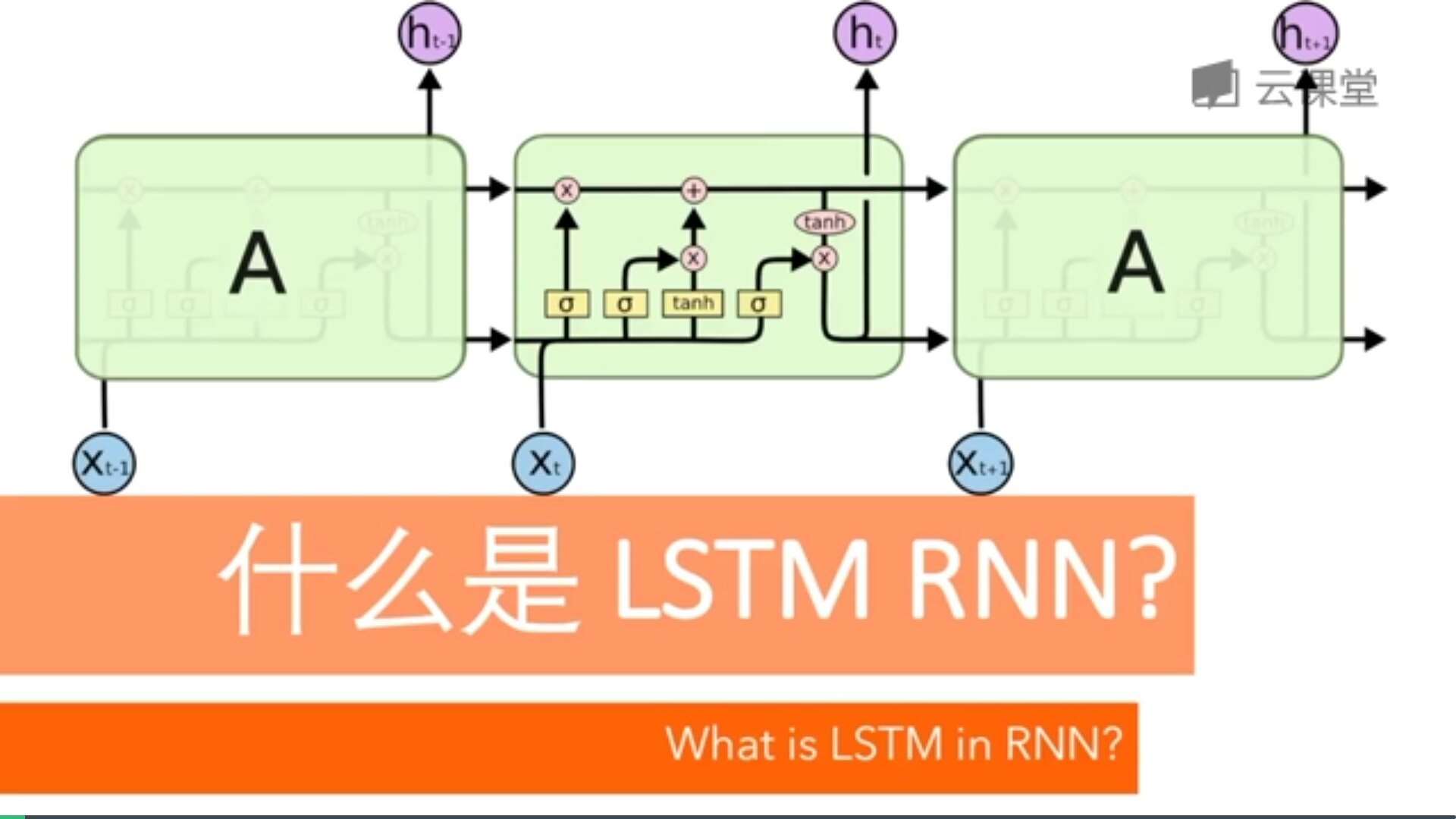
五.LSTM RNN
RNN是在有序的数据上进行学习的,RNN会像人一样对先前的数据发生记忆,但有时候也会像老爷爷一样忘记先前所说。为了解决RNN的这个弊端,提出了LTSM技术,它的英文全称是Long short-term memory,长短期记忆,也是当下最流行的RNN之一。
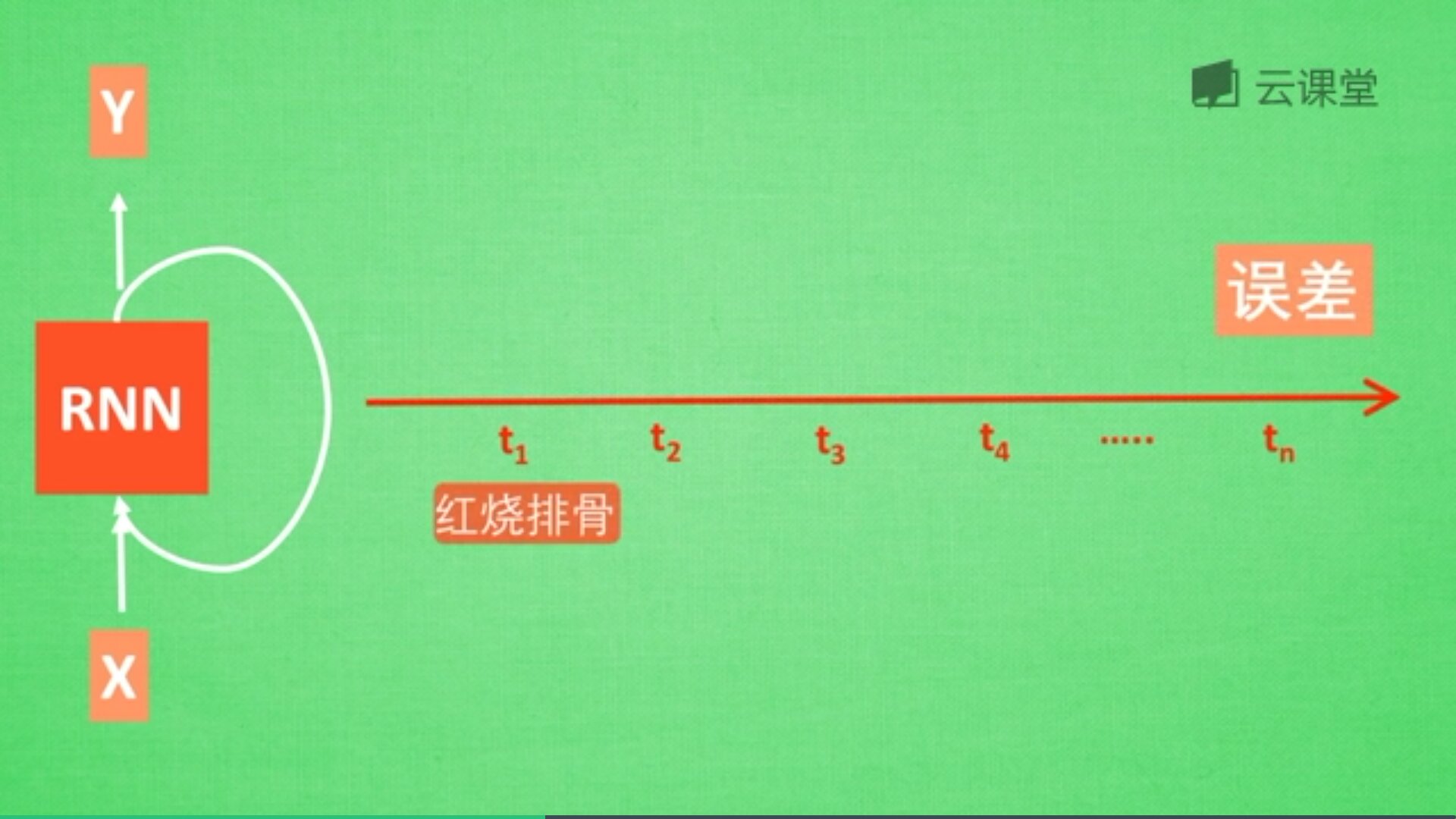
假设现在有一句话,如下图所示,RNN判断这句话是红烧排骨,这时需要学习,而“红烧排骨“在句子开头。

"红烧排骨"这个词需要经过长途跋涉才能抵达,要经过一系列得到误差,然后经过反向传递,它在每一步都会乘以一个权重w参数。如果乘以的权重是小于1的数,比如0.9,0.9会不断地乘以误差,最终这个值传递到初始值时,误差就消失了,这称为梯度消失或梯度离散。
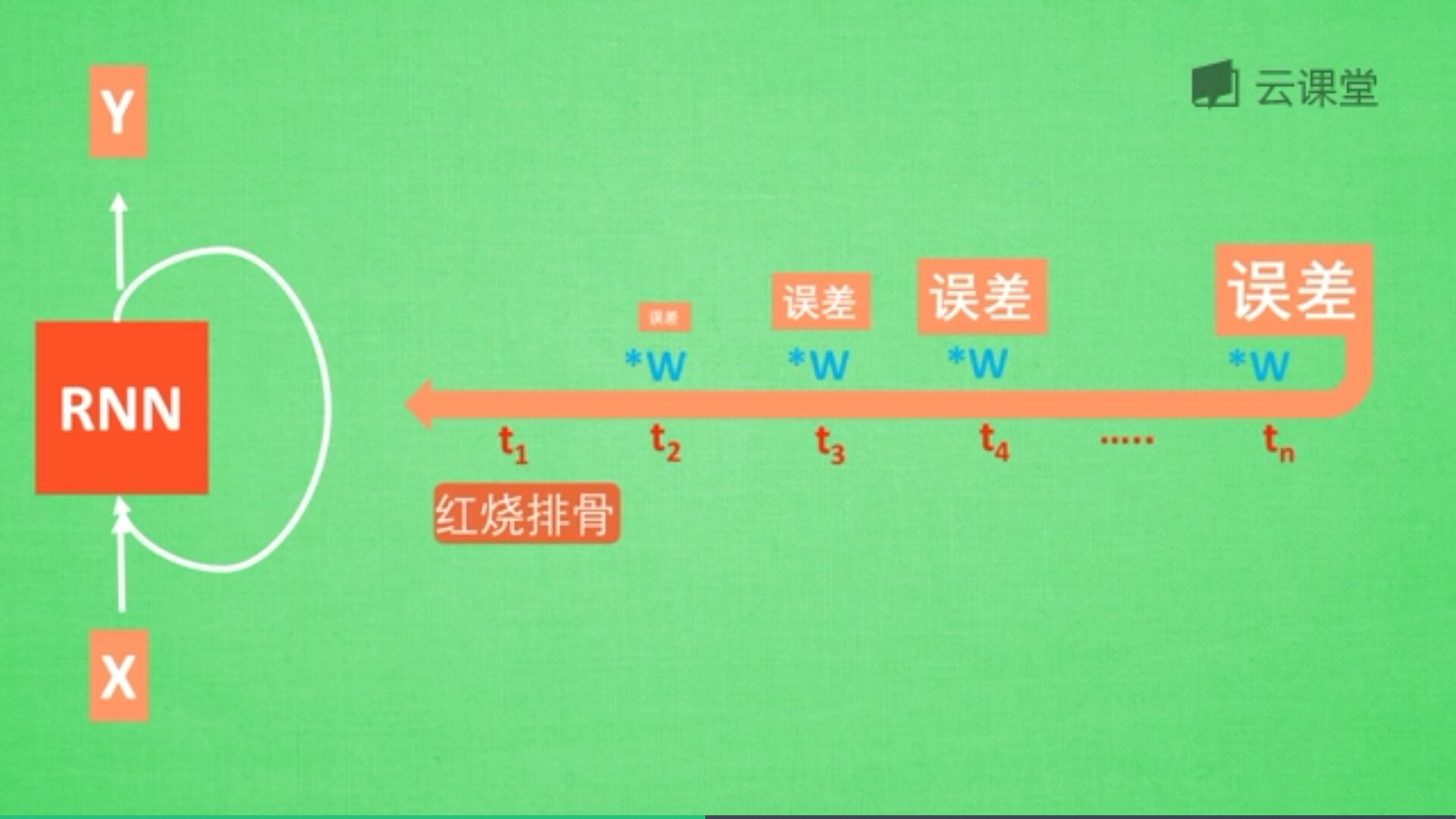
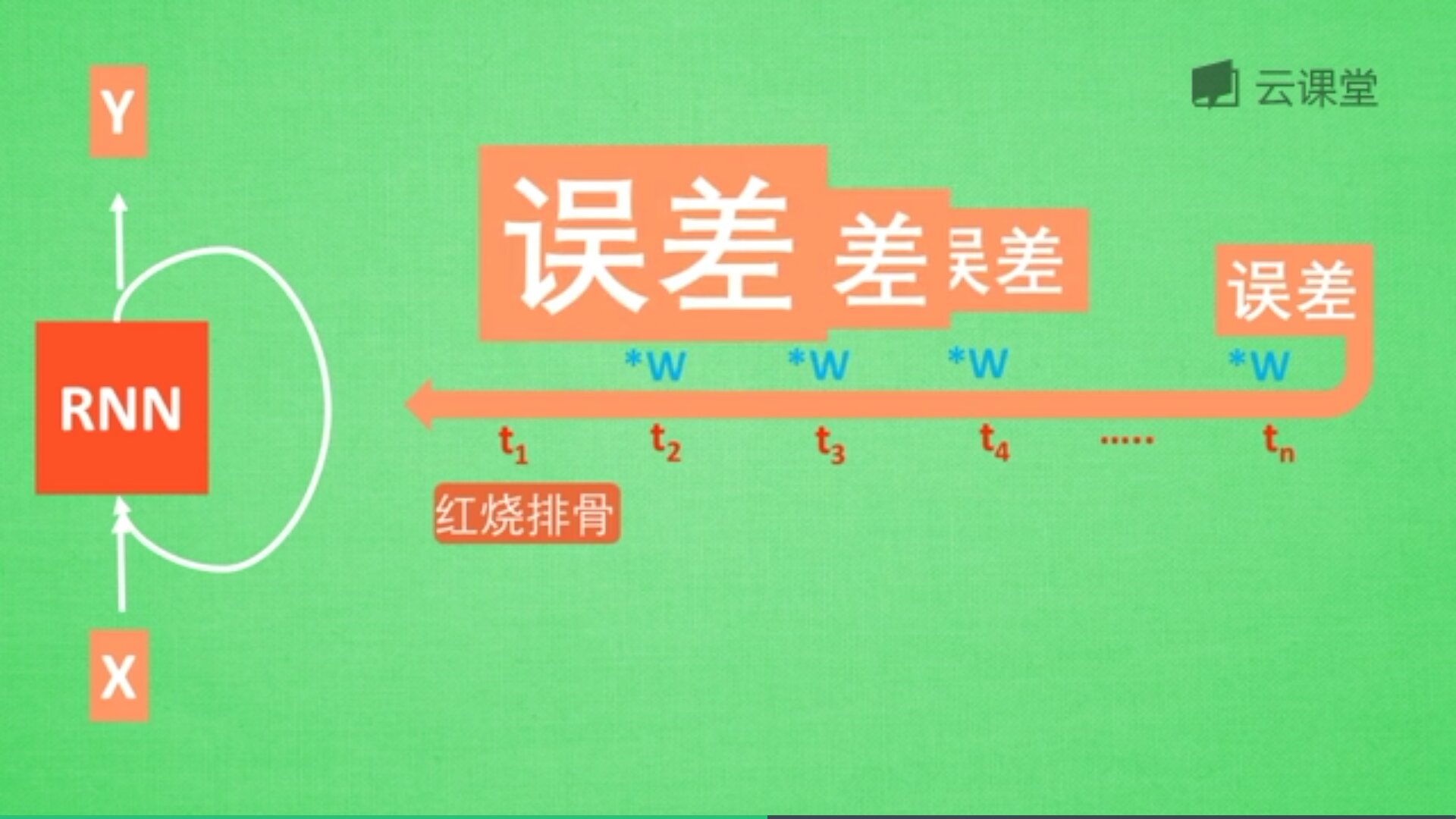
这也是RNN没有恢复记忆的原因,LSTM就是解决这个问题而产生的。如下图所示:
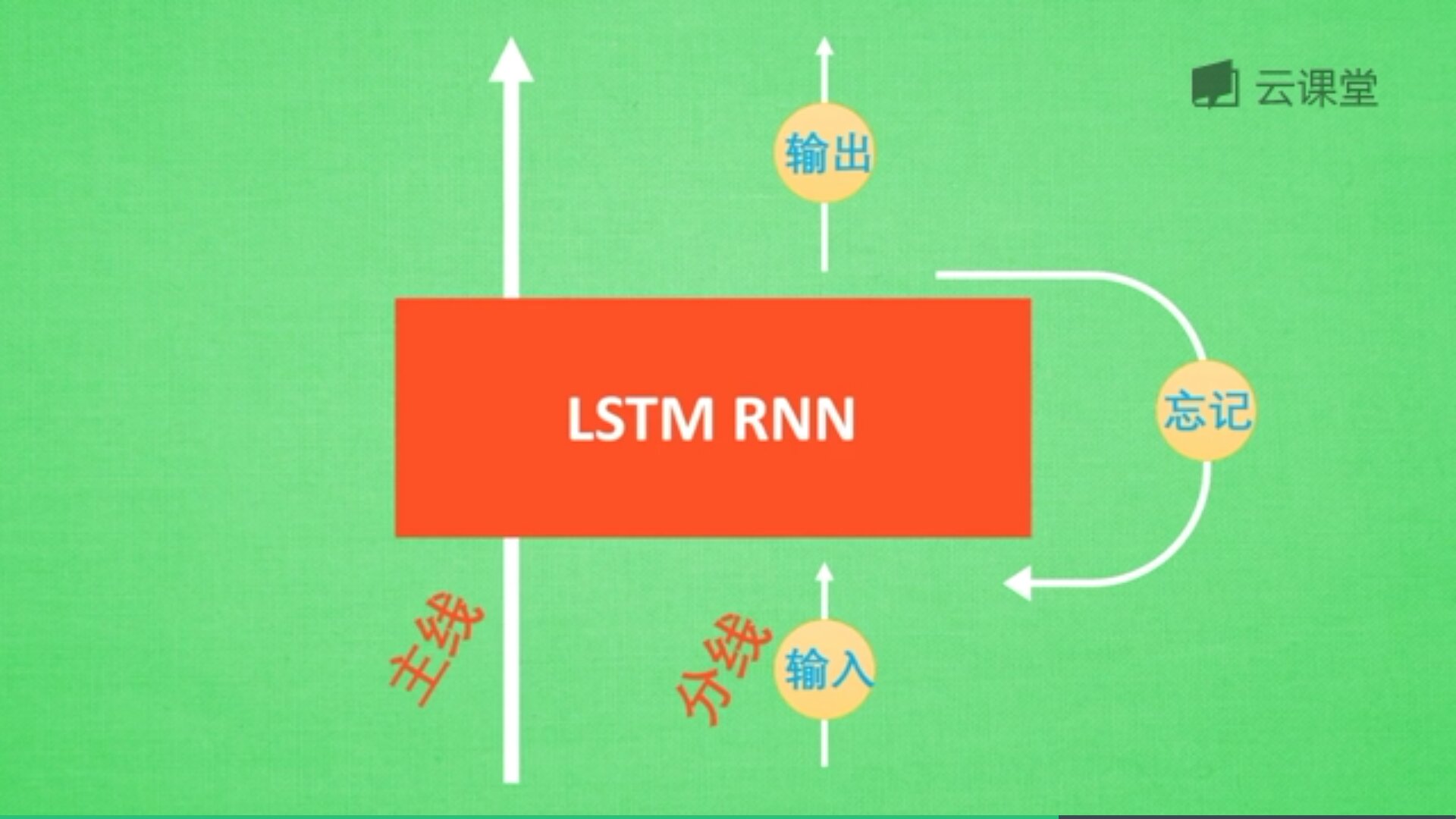
LSTM RNN多了三个控制器,即输入、输出、忘记控制器。左边多了个条主线,例如电影的主线剧情,而原本的RNN体系变成了分线剧情,并且三个控制器都在分线上。
如果分线剧情对于最终结果十分重要,输入控制器会将这个分线剧情按重要程度写入主线剧情,再进行分析;如果分线剧情改变了我们之前的想法,那么忘记控制器会将某些主线剧情忘记,然后按比例替换新剧情,所以主线剧情的更新就取决于输入和忘记控制;最后的输出会基于主线剧情和分线剧情。
基于这些控制的机制,LSTM是延缓记忆的良药,从而带来更好的结果。
六.自编码
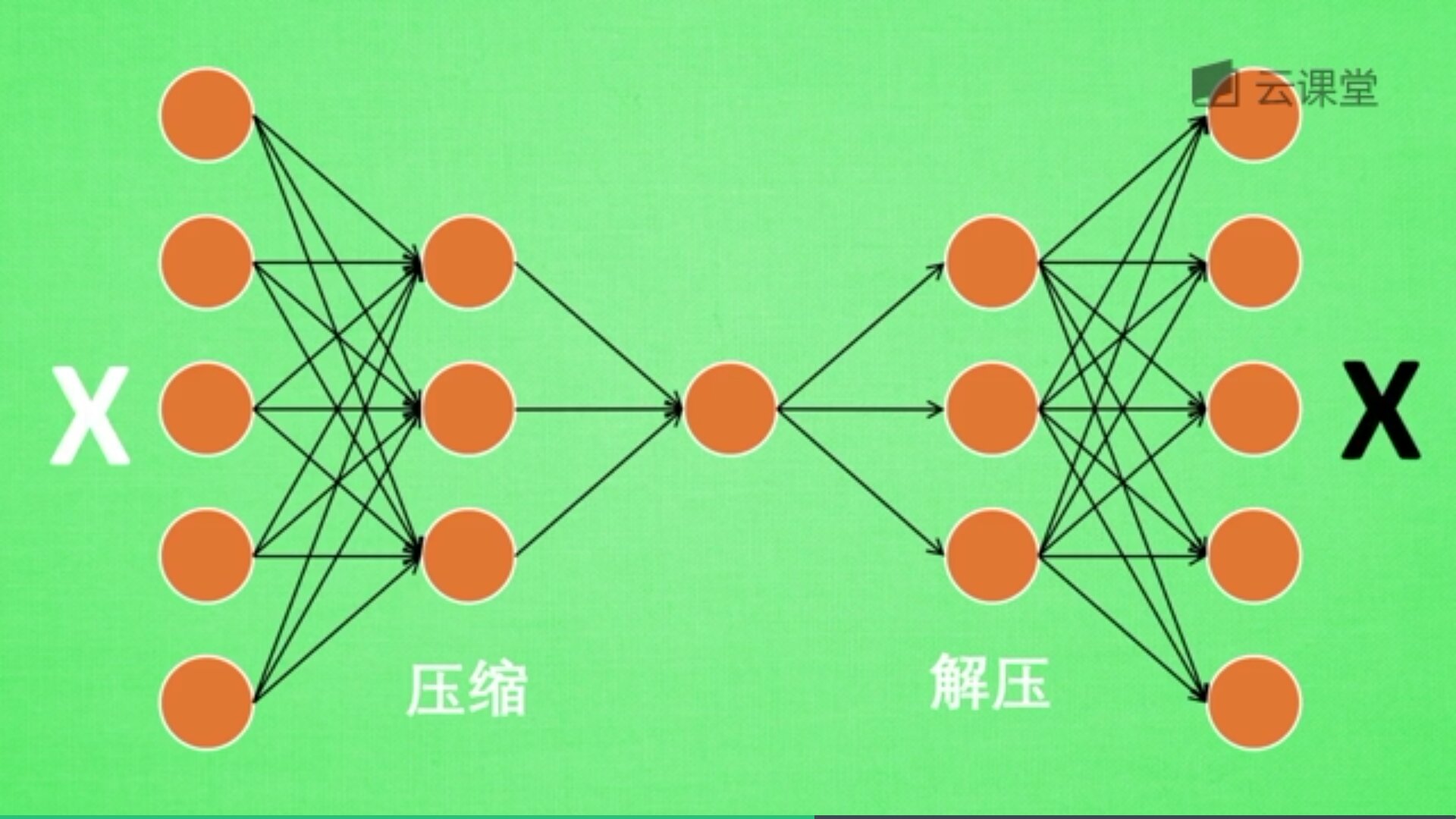
首先,什么是自编码(Autoencoder)?自编码是一种神经网络的形式,注意它是无监督学习算法。例如现在有一张图片,需要给它打码,然后又还原图片的过程,如下图所示:

一张图片经过压缩再解压的工序,当压缩时原有的图片质量被缩减,当解压时用信息量小却包含所有关键性文件恢复出原来的图片。为什么要这么做呢?有时神经网络需要输入大量的信息,比如分析高清图片时,输入量会上千万,神经网络向上千万中学习是非常难的一个工作,此时需要进行压缩,提取原图片中具有代表性的信息,压缩输入的信息量,再把压缩的信息放入神经网络中学习。这样学习就变得轻松了,所以自编码就在这个时候发挥作用。

如下图所示,将原数据白色的X压缩解压成黑色的X,然后通过对比两个X,求出误差,再进行反向的传递,逐步提升自编码的准确性。
训练好的自编码,中间那部分就是原数据的精髓,从头到尾我们只用到了输入变量X,并没有用到输入变量对应的标签,所以自编码是一种无监督学习算法。
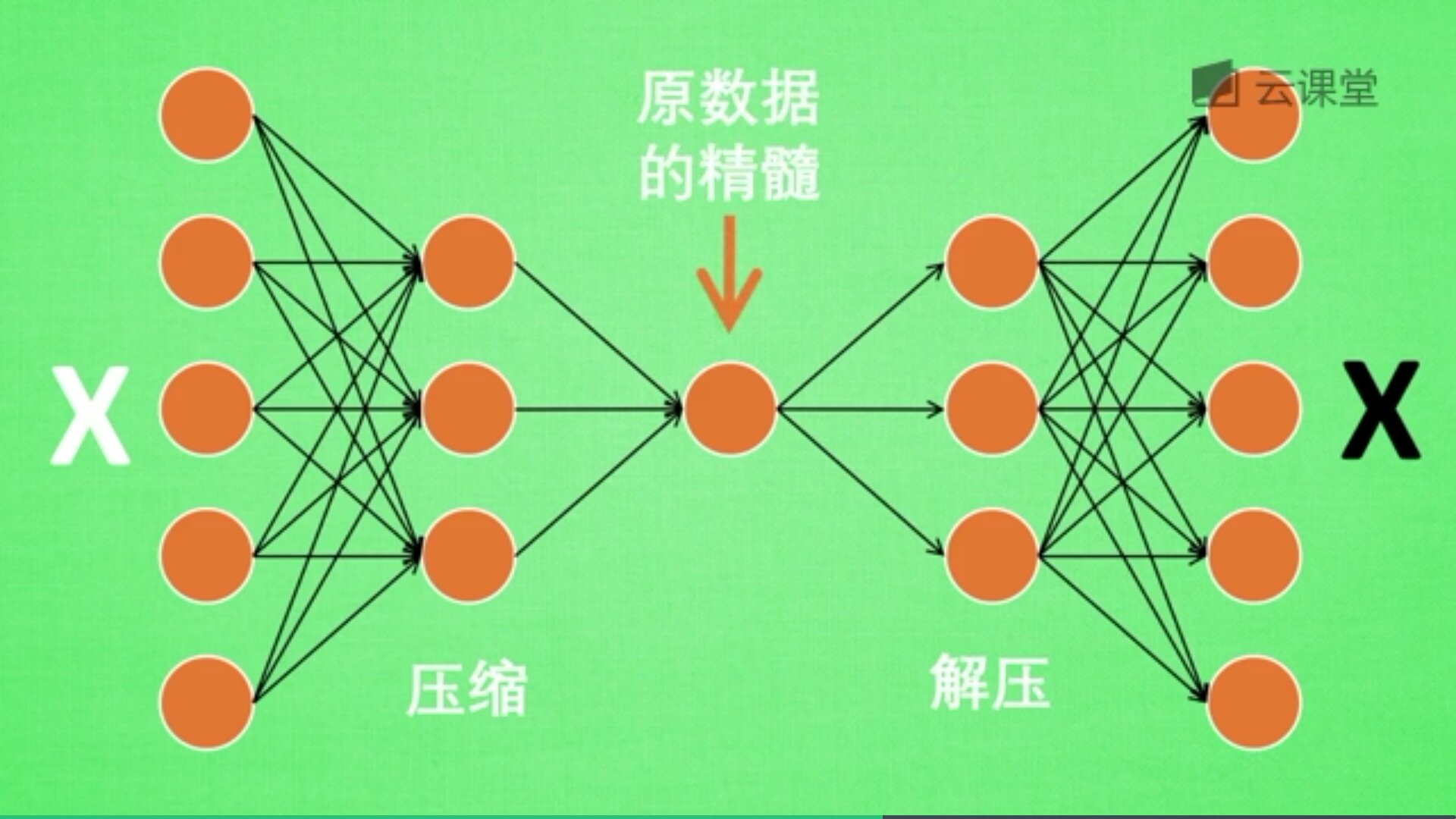
但是真正使用自编码时,通常只用到它的前半部分,叫做编码器,能得到原数据的精髓。然后只需要创建小的神经网络进行训练,不仅减小了神经网络的负担,而且同样能达到很好的效果。
下图是自编码整理出来的数据,它能总结出每类数据的特征,如果把这些数据放在一张二维图片上,每一种数据都能很好的用其精髓把原数据区分开来。自编码能类似于PCA(主成分分析)一样提取数据特征,也能用来降维,其降维效果甚至超越了PCA。

PS:强烈推荐大家去网易云学习莫烦大神的Python视频。
七.GAN生成对抗网络
神经网络分类很多,有普通的前向传播神经网络,有分析图片的CNN卷积神经网络,有分析序列化数据比如语音或文字的RNN循环神经网络,这些神经网络都是用来输入数据,得到想要的结果。我们看中的是这些神经网络通过某种关系输入和结果联系起来。
但还有一种神经网络,不是用来把数据对上结果的,而是用来凭空捏造结果,这就是我们要讲的生成网络,GAN(Generative Adversarial Nets)就是其中一种。

凭空并不是没有意义的盒子,而是有一些随机数,通过这些没有意义的随机数来生成最终有意义的作品,比如蒙娜丽莎画作。





再来屡屡步骤,如下:新手画家用随机灵感画画,新手鉴赏家会接收一些画作,但他不知道这是新手画家画的还是达芬奇画的,他说出了自己的判断,你来纠正他的判断。新手鉴赏家一边说出自己的判断,一边告诉新手画家要怎么修改才能画得像著名画家,新手画家从而学会如何从自己的灵感画更好的画作。
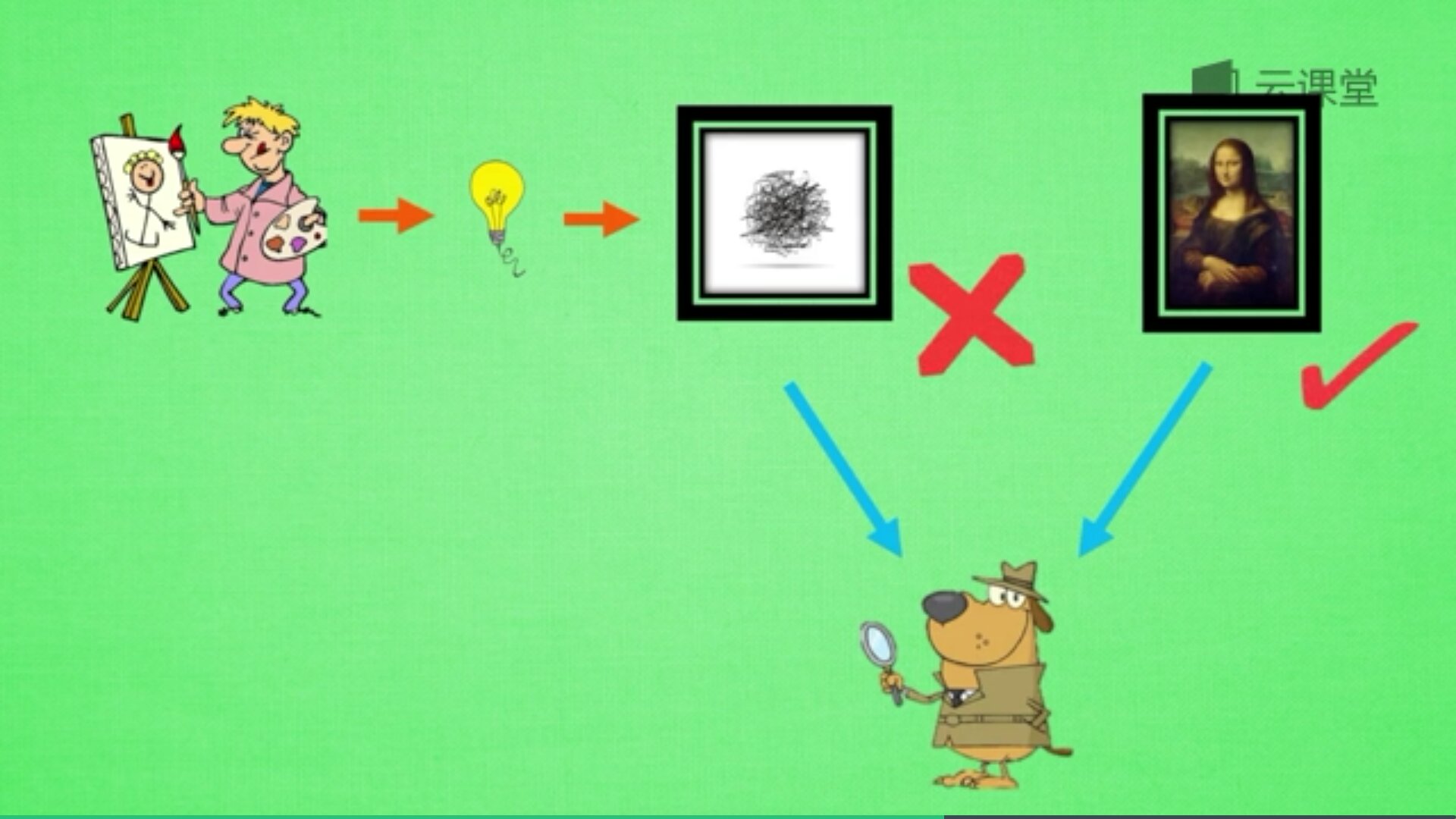
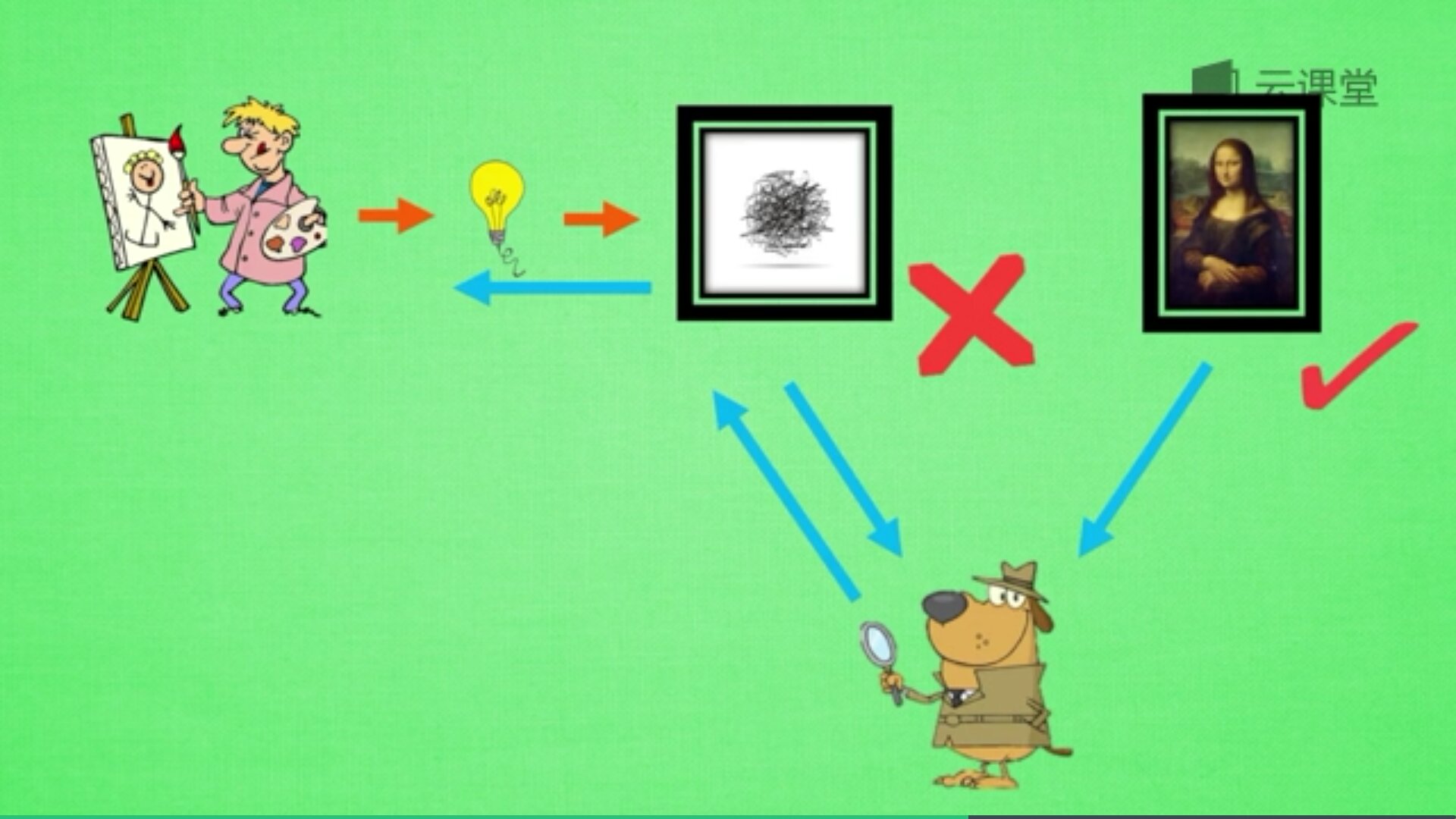

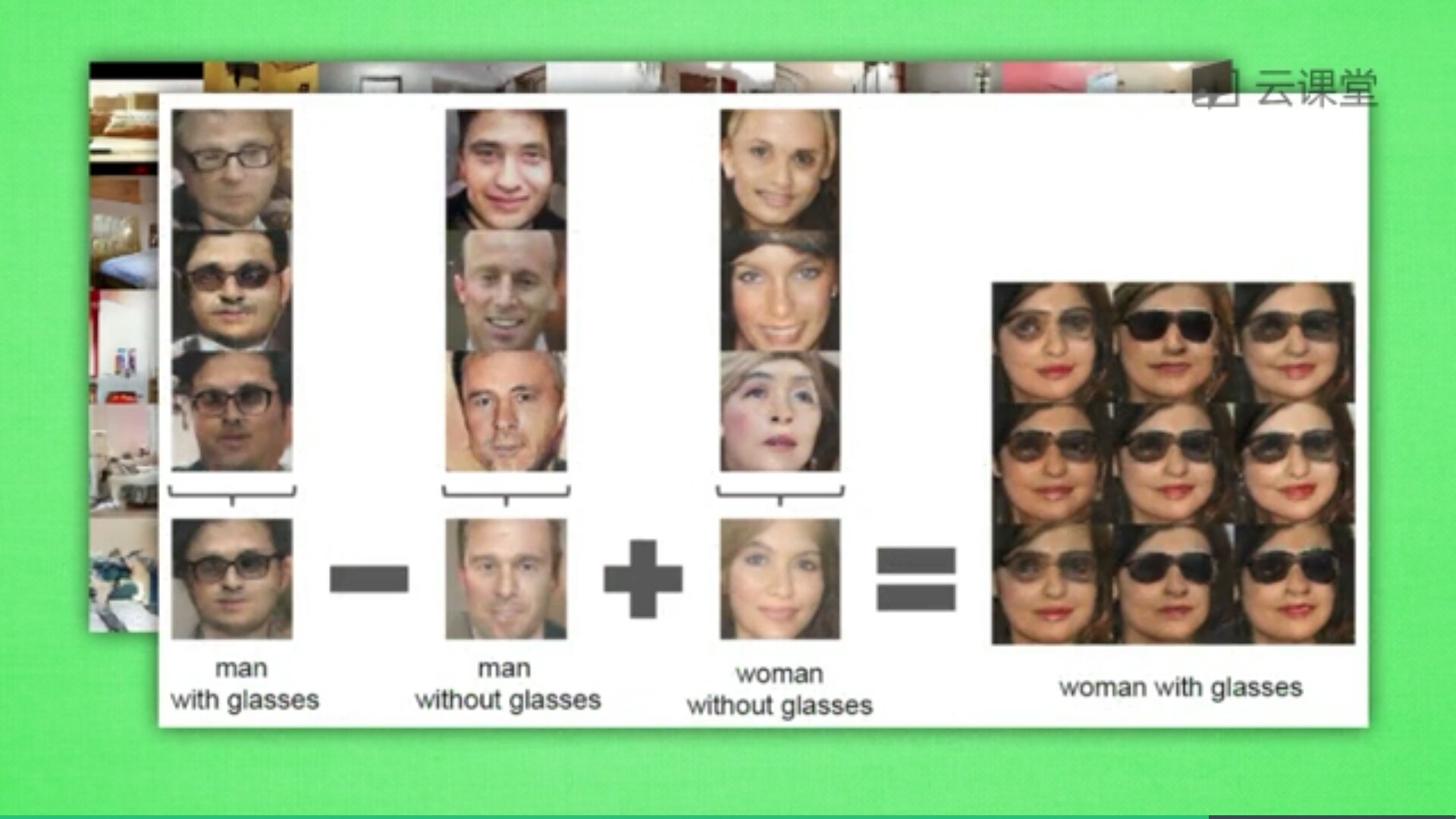
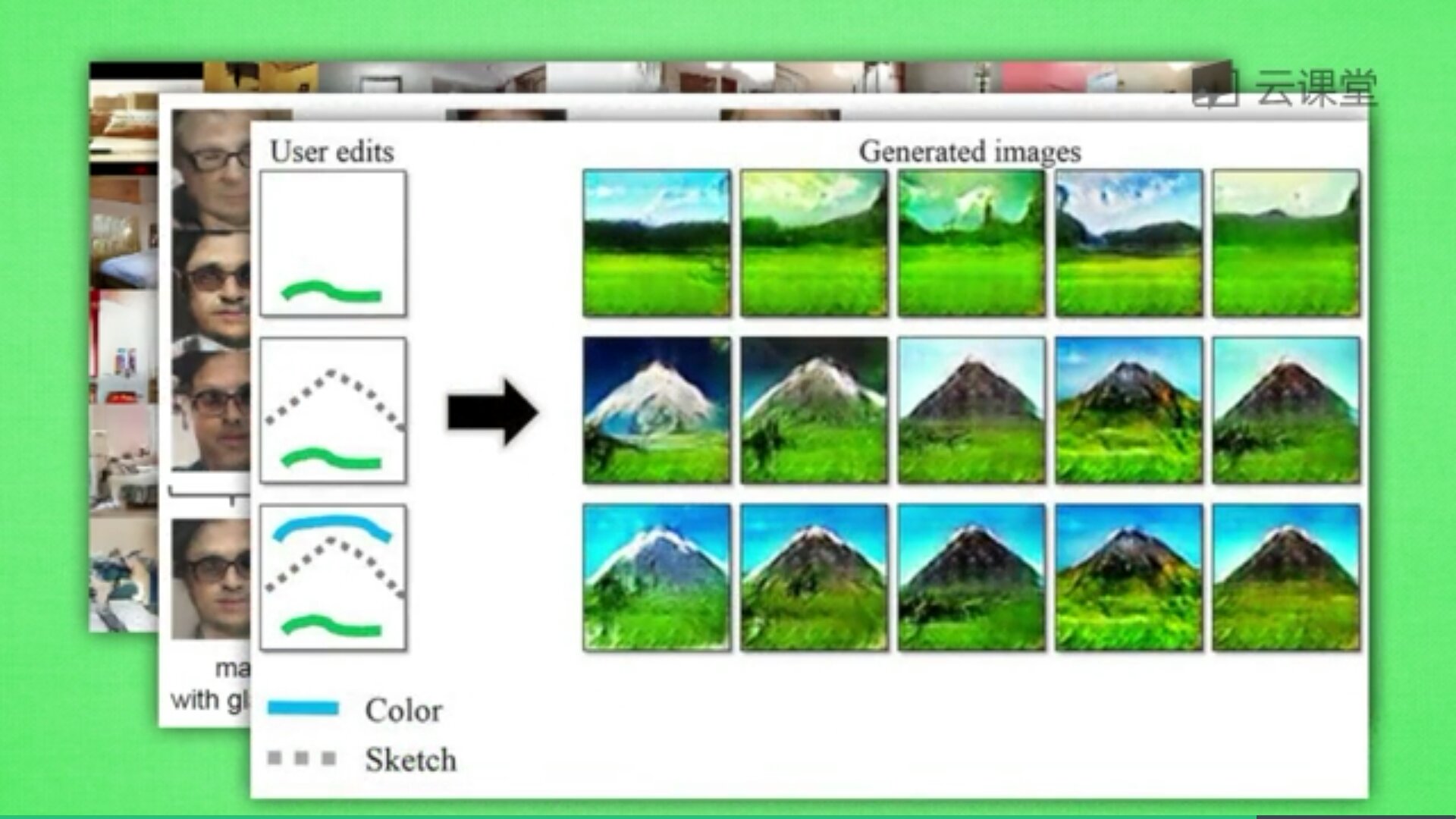
最后讲讲GAN的应用,训练的GAN可以用来随机生成卧室图片,甚至可以做图片加减法,修饰图片,也可以根据随机画的几笔草图生成对应的图片,如下图所示。
讲到这里,神经网络入门知识已经普及完了,后面作者将结合原理及代码实现对应的神经网络,详见博客。同时推荐大家学习莫烦大神的视频,最近自己在疯狂的学习新知识,做好相关笔记和撰写代码。

一个人如果总是自己说自己厉害,那么他就已经再走下坡路了,最近很浮躁,少发点朋友圈和说说吧,更需要不忘初心,砥砺前行。珍惜每一段学习时光,也享受公交车的视频学习之路,加油,最近兴起的傲娇和看重基金之心快离去吧,平常心才是更美,当然娜最美,早安。
(By:Eastmount 2018-05-31 早上10点 http://blog.csdn.net/eastmount/ )