在使用机器学习算法的过程中,我们需要对建立的模型进行评估来辨别模型的优劣,下文中主要介绍我在学习中经常遇见的几种评估指标。以下指标都是对分类问题的评估指标。
将标有正负例的数据集喂给模型后,一般能够得到下面四种情况:
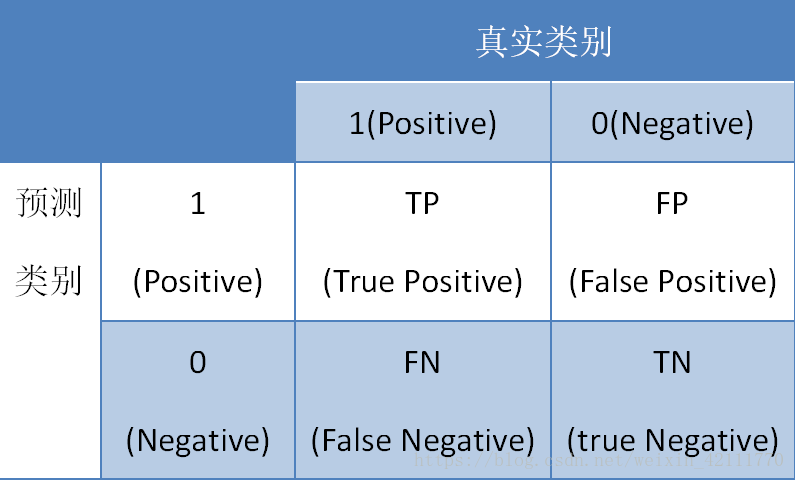
- True Positive(TP),模型将正实例判定为正类
- False Negative(FN),模型将正实例判定为负类
- False Positive(FP), 模型将负实例判定位正类
- True Negative(TN),模型将负实例判定位负类
精度(Precision):精度是针对判定结果而言,预测为正类的样本(TP+FP)中真正是正实例(TP)的比率
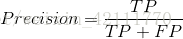
召回率(Recall):召回率是针对样本而言,被正确判定的正实例(TP)在总的正实例中(TP+FN)的比率
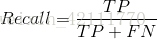
精度和召回率虽然没有必然的关系,然而在大规模数据集合中,这两个指标却是相互制约的。一般情况下,召回率高时,精度低;精度高时,召回率低。
F-measure是精度(Precision)和召回率(Recall)的加权调和平均

当
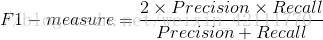
准确率(Accuracy):模型正确分类的样本数(正实例被判定为正类,负实例被判定为负例)在总样本中的比重

ROC曲线(受试者工作特征曲线 receiver operating characteristic curve),是以假正性率(False positive rate,FPR)为横轴,真正类率(True positive rate,TPR)为纵轴所组成的坐标图,和受试者在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线。ROC曲线在测试集中的正负样本的分布变化时,能够保持不变。
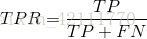
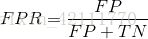
ROC曲线上的每个点对是在某个阈值threshold下得到的(FPR, TPR)。设定一个阈值,大于这个阈值的实例被划分为正实例,小于这个值的实例则被划分为负实例,运行模型,得出结果,计算FPR和TPR值,更换阈值,循环操作,就得到不同阈值下的(FPR, TPR)对,即能绘制成ROC曲线。
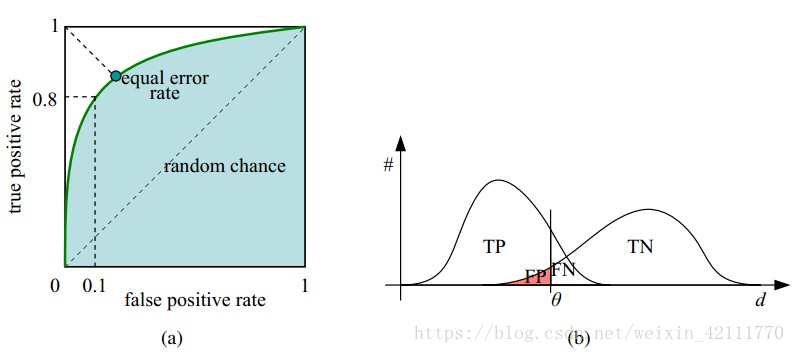
AUC(Area Under Curve)是ROC曲线下的面积值,在0.5到1.0区间内。之所以使用AUC值作为评价标准是因为很多时候并不能从ROC曲线中判别模型的好坏,AUC值能量化模型的性能效果。AUC值越接近于1,说明模型性能越好,模型预测的准确率越高;如果多个模型进行性能比较,一般以AUC值大的模型比AUC值小的模型的性能好。