原文链接 https://blog.csdn.net/qq_38688564/article/details/79369118 在这里感谢作者
-
神经网络相关操作
1.1 tf.nn.conv2(input,filter,strides,padding,use_cudnn_gpu=None,name=None)input:指需要做卷积的输入图像,它要求是一个Tensor, 具有[batch,in_height,in_width,in_channels] 这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数], 注意这是一个4维的Tensor,要求类型为float32和 float64其中之一 filter:相当于CNN中的卷积核,它要求是一个Tensor, 具有[filter_height, filter_width,in_channels, out_channels]这样的shape, 具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷 积核个数], 要求类型与参数input相同,filter的通道数要求与input的 in_channels一致, 有一个地方需要注意,第三维in_channels,就是参数 input的第四维 strides:卷积时在图像每一维的步长,这是一个一维的向 量,长度4,strides[0]=strides[3]=1 padding:string类型的量,只能是"SAME","VALID"其中 之一,这个值决定了不同的卷积方式 第五个参数:use_cudnn_on_gpu:bool类型,是否使用 cudnn加速,默认为true 结果返回一个Tensor,这个输出,就是我们常说的featuremap
input=tf.Variable(tf.random_normal([1,3,3,5]))
filter=tf.Variable(tf.random_normal([1,1,5,1]))
op=tf.nn.conv2d(input=input,filter=filter,strides=
[1,1,1,1],padding='VALID')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
res=(sess.run(op))
print(res.shape)#(1, 3, 3, 1)
print(res)1.2
tf.nn.max_pool(value,ksize,strides,padding,name=None)
第一个参数value:需要池化的输入,一般池化层接在卷积层后面,
所以输入通常是feature map,依然是[batch, height,
width,channels]这样的shape
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是
[1, height, width, 1],因为我们不想在batch和channels
上做池化,所以这两个维度设为了1
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步
长,一般也是[1, stride,stride, 1]
第四个参数padding:和卷积类似,可以取'VALID'或者'SAME'
返回一个Tensor,类型不变,shape仍然是[batch, height,
width, channels]这种形式
a=tf.constant([#(2, 4, 4)
[[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0],
[8.0,7.0,6.0,5.0],
[4.0,3.0,2.0,1.0]],
[[4.0,3.0,2.0,1.0],
[8.0,7.0,6.0,5.0],
[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0]]
])
print(a.shape)
a=tf.reshape(a,[1,4,4,2])
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,1,1,1],padding='VALID')
with tf.Session() as sess:
print('image:')
image=sess.run(a)
print(image)
print("result:")
result=sess.run(pooling)
print(result)
print(result.shape)#(1, 3, 3, 2)
1.3
tf.nn.dropout(x, keep_prob, noise_shape=None,seed=None, name=None)
#按概率来将x中的一些元素值置零,并将其他的值放大。用于进行dropout操作,一定程度上可以防止过拟合
x是一个张量,而keep_prob是一个(0,1]之间的值。
x中的各个元素清零的概率互相独立,为1-keep_prob,而没有清
零的元素,则会统一乘以1/keep_prob, 目的是为了保持x的整体
期望值不变。
1.4
tf.nn.softmax()
#softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)
区间内,可以看成概率来理解,从而来进行多分类!假设我们有一个数
组,V,Vi表示V中的第i个元素,那么这个元素的softmax值如下图
y_conv=tf.nn.softmax(tf.matmul(h_fc1,w_fc2)+b_fc2)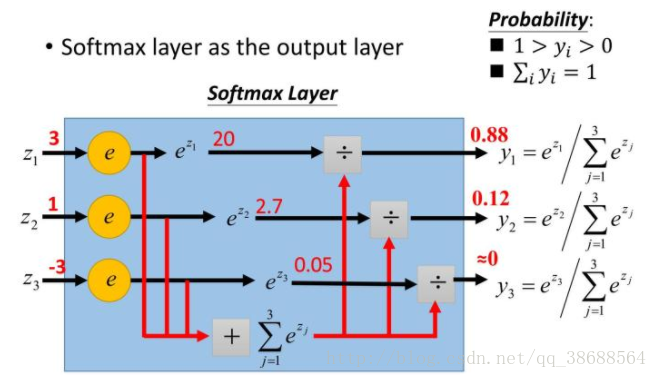
1.5
tf.gradients(ys,xs, grad_ys=None,name="gradients",colocate_gradients_with_ops=False,
gate_gradients=False,aggregation_method=None):
虽然可选参数很多,但是最常使用的还是ys和xs。根据说明得知,
ys和xs都可以是一个tensor或者tensor列表。
# 而计算完成以后,该函数会返回一个长为len(xs)的tensor列表,
# 列表中的每个tensor是ys中每个值对xs[i]求导之和。如果用
数学公式表示的话,那么 g = tf.gradients(y,x)可以表示
1.6
tf.clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None)
修正梯度值,用于控制梯度爆炸的问题。梯度爆炸和梯度弥散的原因一样,
都是因为链式法则求导的关系,导致梯度的指数级衰减。
为了避免梯度爆炸,需要对梯度进行修剪。 先来看这个函数的定义:
函数返回2个参数: list_clipped,修剪后的张量,以及global_norm,一个中间计算量。
当然如果你之前已经计算出了global_norm值,你可以在use_norm选项直接指定global_norm的值。
那么具体如何计算呢?根据源码中的说明,可以得到
list_clipped[i]=t_list[i] * clip_norm / max(global_norm, clip_norm),其中
global_norm = sqrt(sum([l2norm(t)**2 for t in t_list])) l2norm:L2范数 也就是说,当t_list的L2模大于指定的Nc时,就会对t_list做等比例缩放
1.7tf.trainable_variables 返回所有可训练的变量
在创造变量(tf.Variable, tf.get_variable 等操作)时,都会有一个trainable的选项,表示该变量是否可训练。
这个函数会返回图中所有trainable=True的变量。
1.8
tf.nn.embedding_lookup(params, ids,partition_strategy=”mod”, name=None, validate_indices=True)
简单讲就是将一个数字序列ids转换为embedding序列表示
那么这个有什么用呢?如果你了解word2vec的话,就知道我们可以根据文档来对每个单词生成向量。
单词向量可以进一步用来测量单词的相似度等等。那么假设我们现在已经获得了每个单词的向量,都存在param中。
那么根据单词id序列ids,就可以通过embedding_lookup来获得embedding表示的序列。
2.Tensorflow中的激活函数
2. 2.1
tf.nn.relu()
tf.nn.sigmoid()
tf.nn.tanh()
tf.nn.elu()
f.nn.bias_add()
tf.nn.crelu()
tf.nn.relu6()
tf.nn.softplus()
tf.nn.softsign()
tf.nn.dropout()
tf.nn.relu_layer(x, weights, biases,name=None)
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1)+b_fc1)3.矩阵操作
3. 3.1矩阵操作
1.生成随机数的函数
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
tf.truncated_normal截断正态分布随机数,均值mean,标准差stddev,不过只保留[mean-2*stddev,mean+2*stddev]范围内的随机数
tf.random_uniform(shape,minval=0,maxval=None,dtype=tf.float32,seed=None,name=None)均匀分布随机数,[minval,maxval]2.矩阵变换
#1)tf.shape(Tensor)返回张量的形状,返回值也是张量
labels=[1,2,3,4]
shape=tf.shape(labels)
print(shape)#Tensor("Shape:0", shape=(1,), dtype=int32)
print('---')
print(sess.run(shape))#[4]列
#2)tf.expand_dims(tensor,dim)为张量+1维,2维矩阵变3维的意思
x=tf.expand_dims(labels,1)
print(sess.run(x))
#3)tf.pack(values,axis=0,name='pack')将一个R维张量列表沿着axis轴组合成一个R+1维的张量。被取代了
# 'x' is [1, 4]
# 'y'is [2, 5]
# 'z'is [3, 6]
#pack([x, y, z]) = > [[1, 4], [2, 5], [3, 6]] # Pack along first dim.
#pack([x, y, z], axis=1) = > [[1, 2, 3], [4, 5, 6]]
#4)tf.concat(concat_dim,values,name='concat')将张量沿着指定维数拼接起来。个人感觉跟前面的pack用法类似
x=[[1,2,3],[4,5,6]]
y=[[7,8,9],[10,11,12]]
z=tf.concat([x,y],1)#列 第二维相连
z2=tf.concat([x,y],0)#行 第一维相连
sess.run(tf.global_variables_initializer())
print(sess.run(z))#[[ 1 2 3 7 8 9]
# [ 4 5 6 10 11 12]]
print(sess.run(z2))
#[[ 1 2 3]
#[ 4 5 6]
# [ 7 8 9]
#[10 11 12]]
#沿着value的第一维进行随机重新排列
#5)tf.random_shuffle(value,seed=None,name=None)
a=[[1,2],[3,4],[5,6]]
x=tf.random_shuffle(a)
print(sess.run(x))
#6)tf.argmax(input=tensor,dimention=axis)找到给定的张量tensor中在指定轴axis上的最大值/最小值的位置。
a=tf.get_variable(name='a',shape=[3,4],dtype=tf.float32,initializer=tf.random_uniform_initializer(minval=-1.0,maxval=1.0))
b=tf.argmax(input=a,dimension=0)
c=tf.argmax(input=a,dimension=1)
sess.run(tf.global_variables_initializer())
print(sess.run(a))
print(sess.run(b))#[2 2 1 2]按照行来比,就是第一列所有行最大值所在的行
print(sess.run(c))#[3 2 3]按照第二维就是,所有列中最大值所在的列
#7)tf.equal(x,y,name=None)判断两个tensor是否每个元素都相等。返回一个格式为bool的tensor
#8)tf.reduce_mean(input_tensor,reduction_indices=None,keep_dims=False,name=None)求均值
#参数1--input_tensor:待求值的tensor。
#参数2--reduction_indices:在哪一维上求解。
#参数(3)(4)可忽略,没有第二参数,即求所有
x=[[2,2],[6,4]]
a=tf.reduce_mean(x)
b=tf.reduce_mean(x,0)
c=tf.reduce_mean(x,1)
print(sess.run(a))#3
print(sess.run(b))#[4 3]
print(sess.run(c))#[2 5]
#9)tf.reduce_max|tf.reduce_sum(input_tensor, reduction_indices=None,keep_dims=False, name=None)
#参数1--input_tensor:待求和的tensor。
#参数2--reduction_indices:在哪一维上求解。
import numpy as np
inputs=[[1,0,2],[3,2,4]]
print(type(inputs))#<class 'list'>
inputs=np.array(inputs)
print(type(inputs))#<class 'numpy.ndarray'>
A=tf.sign(inputs)#sign把转成0 1矩阵
print(type(A))#<class 'tensorflow.python.framework.ops.Tensor'>
B=tf.reduce_sum(A,reduction_indices=1)
with tf.Session() as sess:
print(sess.run(A))
print(sess.run(B))
#10)tf.cast(x,dtype,name=None)将x的数据格式转化成dtype.例如,原来x的数据格式是bool,那么将其转化成float以后,就能够将其转化成0和1的序列。反之也可以
a=tf.Variable([1,0,0,1,1])
b=tf.cast(a,dtype=tf.bool)
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
#11)tf.matmul
#用来做矩阵乘法。若a为l*m的矩阵,b为m*n的矩阵,那么通过tf.matmul(a,b) 结果就会得到一个l*n的矩阵
#不过这个函数还提供了很多额外的功能。我们来看下函数的定义:
#tf.matmul(a,b,transpose_a=False,transpose_b=False,a_is_sparse=False,b_is_sparse=False,name=None)
#可以看到还提供了transpose和is_sparse的选项。
#如果对应的transpose项为True,例如transpose_a=True,那么a在参与运算之前就会先转置一下。
#而如果a_is_sparse=True,那么a会被当做稀疏矩阵来参与运算。
#12)tf.reshape(tensor,shape,name=None)
#顾名思义,就是将tensor按照新的shape重新排列。一般来说,shape有三种用法:
#如果 shape=[-1], 表示要将tensor展开成一个list
#如果 shape=[a,b,c,…] 其中每个a,b,c,..均>0,那么就是常规用法
#如果 shape=[a,-1,c,…] 此时b=-1,a,c,..依然>0。这表示tf会根据tensor的原尺寸,自动计算b的值。
#13)
tf.get_variable(name,shape=None,
dtype=dtypes.float32, initializer=None,
regularizer=None, trainable=True,
collections=None,caching_device=None,
partitioner=None, validate_shape=True,
custom_getter=None)
#如果在该命名域中之前已经有名字=name的变量,则调用那个
变量;
如果没有,则根据输入的参数重新创建一个名字为name的变量。
在众多的输入参数中,有几个是我已经比较了解的,下面来
一一讲一下
#name: 这个不用说了,变量的名字
#shape: 变量的形状,[]表示一个数,[3]表示长为3的向量
,[2,3]表示矩阵或者张量(tensor)
#dtype: 变量的数据格式,主要有tf.int32, tf.float32,
tf.float64等等
#initializer: 初始化工具,有
tf.zero_initializer,tf.ones_initializer,
tf.constant_initializer,
#tf.random_uniform_initializer,tf.random_normal_initializer,
tf.truncated_normal_initializer等
a=tf.constant(1,shape=[1])
x=tf.get_variable(name='a',shape=[2,5],dtype=tf.int64,initializer=tf.random_uniform_initializer(minval=1,maxval=5,dtype=tf.int64))
sess.run(tf.global_variables_initializer())
print(sess.run(a))
print(sess.run(x))4.普通操作
4. 4.1
1)
tf.linspace(start,stop,num,name=None) |tf.range(start,limit=None,delta=1,name=’range’)
#这两个放到一起说,是因为他们都用于产生等差数列,不过具体用法不太一样。
#tf.linspace在[start,stop]范围内产生num个数的等差数列。不过注意,start和stop要用浮点数表示,不然会报错
#tf.range在[start,limit)范围内以步进值delta产生等差数列。注意是不包括limit在内的。
x=tf.linspace(start=1.0,stop=5.0,num=5,name=None)
y=tf.range(start=1,limit=5,delta=1)
sess=tf.Session()
print(sess.run(x))
2)
tf.assign(ref, value,validate_shape=None, use_locking=None, name=None)
#tf.assign是用来更新模型中变量的值的。ref是待赋值的变量,value是要更新的值。
#即效果等同于 ref = value
a=tf.Variable(0.0)
b=tf.placeholder(dtype=tf.float32,shape=[])
op=tf.assign(a,b)
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
print(sess.run(a))
sess.run(op,feed_dict={b:5.})
print(sess.run(a))