朋友们,如需转载请标明出处:http://blog.csdn.net/jiangjunshow
总目录(新手请点击总目录从序言看起,否则你可能看不懂本篇文章)
(在讲人工智能之前,第一段我先讲讲其它的,讲一些我想讲的,讲一些大家需要知道的,讲一些对大家的人生有帮助的!)说一下单身的问题吧。我们大部分程序员都是单身。是工作环境决定的。我刚出道时也是每晚都很孤独,后来慢慢才练就成了床长。我给大家分享一下我的心得吧。我们不像一些搞业务的,可以到处跑到处接触各种人,我们每天的接触对象就是电脑。当然,公司里也有其他部门的妹子,但是我给你的建议是,千万不要碰公司里的妹子。那怎么办呢?去哪里接触妹子呢。不少朋友选择去参加一些活动,什么桌游啊KTV呀,去过的应该就知道,其实没什么卵用。因为那种接触太短暂,而且那么短暂接触就能搞定的我也怕不安全。正确的方式是去参加一个长期的妹子又多又漂亮的技能俱乐部。就拿我在北京参加的钢琴俱乐部来说,它和培训班不同,培训班是枯燥的学习,而这个俱乐部一大特色就是休闲交友,想学的时候就学一下,不想学就和大家聊聊骚,喝喝茶泡下咖啡。也不需要基础,我之前一点都不会,现在可以随便弹,我记得当时体验课时30分钟就可以弹曲子了,我们程序员手指本来也很灵活。我每晚下班之后都会去,因为呆在房间里还不如呆在俱乐部里和妹子接触。而且学钢琴的妹子都挺漂亮。和她们学学琴聊聊天,自然而然就发生关系了。很多时候我们老是觉得单身是因为自己不会说话,不会交友,其实关键是在于你不会选择环境,如果把你天天扔到一个女人堆里,就算你一个屁都不放,都会有妹子主动找你。在北京的朋友可以过去看看,我在那里名气挺大的,点击链接可以免费预约,体验后如果决定学习报我床长的名可以打九折。

大家已经学过如何将待预测数据输入到神经网络中,也明白了神经网络是如何对这些数据进行预测的,还知道了神经网络是如何判断自己预测得是否准确的。那么如果结果预测得不准确,是不是要想办法让预测变得准确呢?这个努力让自己预测得更准确的过程就是学习。
在前面的文章中,我们已经知道,预测得是否准确是由w和b决定的,所以神经网络学习的目的就是要找到合适的w和b。通过一个叫做梯度下降(gradient descent)的算法可以达到这个目的。梯度下降算法会一步一步地改变w和b的值,新的w和b会使损失函数的输出结果更小,即一步一步让预测更加精准。
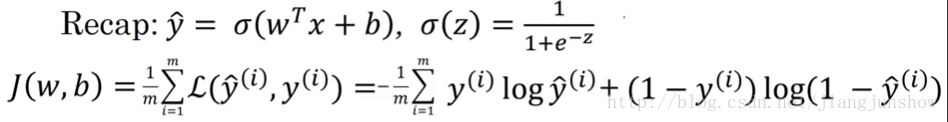
上面的公式是我们之前学到的逻辑回归算法(用于预测),以及损失函数(用于判断预测是否准确)。结合上面两个公式,输入x和实际结果y都是固定的,所以损失函数其实是一个关于w和b的函数(w和b是变量)。所谓“学习”或“训练神经网络”,就是找到一组w和b,使这个损失函数最小,即使预测结果更精准。
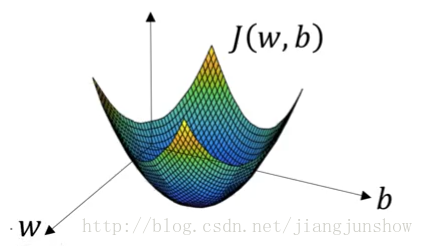
如上图所示,损失函数J的形状是一个漏斗状。我们训练的目的就是找到在漏斗底部的一组w和b。这种漏斗状的函数被称为凸函数(向下凸起的函数)。我们选择J为损失函数的原因正是因为J是一个凸函数。而我们之前遇到的平方差函数不是一个凸函数,那么就很难找到最小值,这就是为什么我们不采用平方差函数作为损失函数的原因。
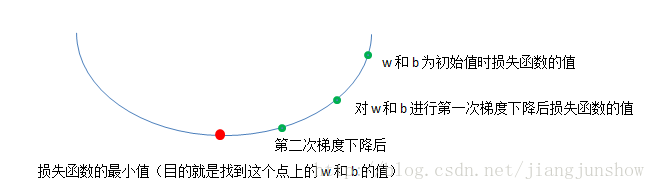
如上图所示,梯度下降算法会一步一步地更新w和b,使损失函数一步一步地变得更小,最终找到最小值或接近最小值的地方。
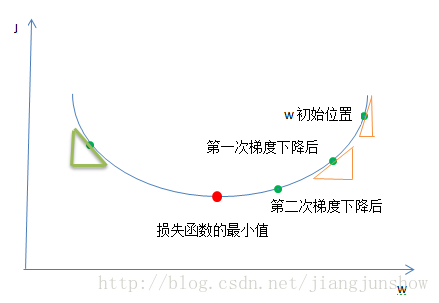
那么到底这个神秘的梯度下降算法是如何来更新w和b的呢?为了简化问题,让大家更容易理解其中的理论,我们先假设损失函数J只有一个参数w(实际上J是一个关于w和b的函数),并且假设w只是一个实数(实际上w是一个向量/一组实数)。如上图,梯度下降算法一步一步地在改变着w的值,在使损失函数的结果越来越小(将w的值一步一步的移到红点处)。我们是通过下面的公式来改变w的值的。
w’ = w – r * dw
梯度下降算法就是重复的执行上面的公式来不停的更新w的值。新的w的值(w’)等于旧的w减去学习率r与偏导数dw的乘积。不要怕,我一步一步地给你解释它们。r表示学习步进/学习率(learning rate),假设w是10,又假设dw为1,r为4时,那么在第一次梯度下降后,w’的值将变成6,而当r为2时,那么第一次下降后,w’将是8,从10变成了8比起从10变成6,变化得没有那么大,因为变化率r比较小。r是我们用来控制w的变化步进的参数。dw是参数w关于损失函数J的偏导数,偏导数是数学微积分里面的一个概念,不懂不用怕,我会慢慢让你懂。偏导数说白了就是斜率。斜率就是变化比例,即当w改变一点点后J会相应的改变多少。看上图中的黄色的小三角,在w的初始值(假设为6)的位置的偏导数/斜率/变化比例就是小三角的高除以低边(J的变化除以w的变化),也就是在当w为6时J函数的变化与w的变化之比,曲线越陡,那么三角形越陡,那么斜率越大,那么当w的值改变一丁点后(例如减1)那么J相应的改变就会越大(假设会减小3),在下面那个小三角的位置(假设那里的w是4),这个位置的曲线不是那么的陡,即斜率比较小,那么在那里w的值改变一点后(例如也减小1)但J相应的改变却没有那么大了(可能只减小1.5)。这个斜率dw就是J的变化与w的变化的比例,就是说,我们按照这个比例去使w越来越小那么它相应的J也会越来越小,最终达到我们的目的,找到J最小值时w的值是多少。损失函数J的值越小,表示预测越精准。神经网络就是通过这种方法来进行学习的,通过梯度下降算法来一步一步改变w和b的值,使损失函数越来越小,使预测越来越精准。其实原理还是很简单的!另外这里要说一下,w越来越小是一种相对的说法,例如看上面绿色的小三角的地方,这里的斜率是为负数的,所以w减去一个负数,等于w变大了,由于dw/斜率/变化比例是负数,所以w变大,那么J就变小,最终还是会移到J的最小值处。
有人会说,那我每次都使w改变很多,那么就会更快的到达J的最小值处。是可以。但是,要控制好“度”,因为如果你每次让w改变太多,那么可能会错过了J的最小值处,例如上图中你可能会从w的初始位置直接到了绿色小三角的位置(跳过了J的最小值处),之后你会左右来回跳,永远到不了J的最小值处。这就是r的用武之地,用它来控制w改变的步进,所以选择一个正确的学习率很重要。选错了,那么你的神经网络可能会永远找不到损失函数的最小值处,即你的神经网络预测得永远不会很准。后面后面的文章我会教大家如何来选择正确的学习率。一定要跟着床长走!跟着我走,面包会有的,牛奶会有的,钞票会有的,妹子也会有的!
新的文章将改为在公众号上发布,请大家加我的微信,之后会用微信向大家公布测试题答案和一些通知,以及统一回答大家遇到的常见问题,有项目也可以招集大家一起做。加我时请注明“人工智能”。
