简单来说,标准化是依照特征矩阵的列处理数据,其通过求Z-score的方法,将样本的特征值转换到同一量纲下。
归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点成运算或其他和函数计算相似性时,拥有同一的标准。也就是说都转化为“单位向量”
--------------------------
对比一下代码的输出,即可明白StandardScaler()对列进行标准化
from sklearn import preprocessing
X = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
scaler = preprocessing.StandardScaler().fit(X)
print(X)
print(scaler)
print(scaler.mean_)
print(scaler.scale_)
x1=scaler.transform(X)
print(x1)输出如下:
[[ 1. -1. 2.]
[ 2. 0. 0.]
[ 0. 1. -1.]]
StandardScaler(copy=True, with_mean=True, with_std=True)
[ 1. 0. 0.33333333]
[ 0.81649658 0.81649658 1.24721913]
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]--------------------------
from sklearn import preprocessing
import numpy as np
X = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
X_scaled = preprocessing.scale(X)
print(X_scaled)
print(X_scaled.mean(axis=0))
print(X_scaled.std(axis=0))
print(X_scaled.mean(axis=1))
print(X_scaled.std(axis=1))输出:
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]
[ 0. 0. 0.]
[ 1. 1. 1.]
[ 0.03718711 0.31916121 -0.35634832]
[ 1.04587533 0.64957343 1.11980724]--------------------
把数变为(0,1)之间的小数
例1:{2.5 3.5 0.5 1.5}归一化后变成了{0.3125 0.4375 0.0625 0.1875}
解:2.5+3.5+0.5+1.5=8,
2.5/8=0.3125,
3.5/8=0.4375,
0.5/8=0.0625,
1.5/8=0.1875.
这个归一化就是将括号里面的总和变成1.然后写出每个数的比例
--------------------------
参考:R + python︱数据规范化、归一化、Z-Score :https://blog.csdn.net/sinat_26917383/article/details/51228217
----------------------------
在机器学习和数据挖掘中,经常会听到两个名词:归一化(Normalization)与标准化(Standardization)。它们具体是什么?带来什么益处?具体怎么用?本文来具体讨论这些问题。
一、是什么
1. 归一化
常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换函数为:
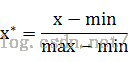
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
2. 标准化
常用的方法是z-score标准化,经过处理后的数据均值为0,标准差为1,处理方法是:
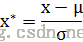
其中,其中μ是样本的均值, σ是样本的标准差,。该种归一化方式要求原始数据的分布可以近似为高斯分布,否标准化的效果会变得很糟糕。它们可以通过现有样本进行估计。在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
二、带来什么
归一化的依据非常简单,不同变量往往量纲不同,归一化可以消除量纲对最终结果的影响,使不同变量具有可比性。比如两个人体重差10KG,身高差0.02M,在衡量两个人的差别时体重的差距会把身高的差距完全掩盖,归一化之后就不会有这样的问题。
标准化的原理比较复杂,它表示的是原始值与均值之间差多少个标准差,是一个相对值,所以也有去除量纲的功效。同时,它还带来两个附加的好处:均值为0,标准差为1。
均值为0有什么好处呢?它可以使数据以0为中心左右分布(这不是废话嘛),而数据以0为中心左右分布会带来很多便利。比如在去中心化的数据上做SVD分解等价于在原始数据上做PCA;机器学习中很多函数如Sigmoid、Tanh、Softmax等都以0为中心左右分布(不一定对称)。
以上为两种比较普通但是常用的归一化技术,那这两种归一化的应用场景是怎么样的呢?什么时候第一种方法比较好、什么时候第二种方法比较好呢?下面做一个简要的分析概括:
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。