经过几天的学习,本以为自己的进度跟得上,但是昨天老师问进度的时候才发现自己貌似走了岔路,但是学多不亏这句话激励着我,使我不至于沮丧,遇到的问题是,老师认为我没必要一直看tensorflow这么底层的东西。但初用python的我实际上已经对tensorflow的“高级”程度已经够震惊了,我觉得用tensorflow搭建一个神经网络已经够简单了,没想到还有Keras这样封装更加完善的,以下是对前几天学习的使用tensorflow实现的神经网络的Keras实现,可以发现简单不少。
当时参考的博文:深度学习(08)_RNN-LSTM循环神经网络-03-Tensorflow进阶实现
推荐大家看看Keras中文手册:官方的中文文档
实现代码与注释:
#如果有疑惑,建议使用jupyter notebook边实现边观察输出,这样有助于理解和掌握
#打开文件,请保证文件在当前路径之下,文件下载地址:https://raw.githubusercontent.com/jcjohnson/torch-rnn/master/data/tiny-shakespeare.txt
file_name = 'tinyshakespeare.txt'
with open(file_name,'r') as f:
raw_data = f.read()
#除去文本中的重复字符,得到字符集大小
vocab = set(raw_data)
vocab_size = len(vocab)
#将字符序列转换为数字序列,并删除原数据
idx_to_vocab = dict(enumerate(vocab))
vocab_to_idx = dict(zip(idx_to_vocab.values(),idx_to_vocab.keys()))
data = [vocab_to_idx[c] for c in raw_data]
del raw_data
#处理得到输入和标签集,大小均为1000000,因为是对下一个字符进行预测,所以每一行标签对应于下一行的输入
label = data[1:1000001]
data = data[:1000000]
import keras
from keras.models import Sequential
from keras.layers import LSTM,Dense
import numpy as np
#对于超参数的解释,因为使用当前字符预测下一个字符,故输出维度data_dim=1,即只有一个特征值
data_dim = 1
#timesteps决定了LSTM神经网络中记忆的时间长短,简单的来说,尽管文本长达1000000,但每次只从最近的200个字符中学习
timesteps = 200
#输出的one_hot的维度
num_classes = vocab_size
#batch的大小数据被划分为1000000//timesteps组,使用mini-batch来训练提高训练速度,需被组数整除
batch_size = 500
#定义神经网络图
model = Sequential()
#第一层采用LSTM网络,其神经元数为32,相当于能提取32个中间特征作为全连接层的输入
#stateful=True则上一step的状态可以用来初始化下一step
model.add(LSTM(32,return_sequences=True,stateful=True,batch_input_shape=(batch_size,
timesteps,data_dim)))
#第二层则使用全连接层,输出为one_hot张量,最后与标签y进行比较得到准确率
model.add(Dense(num_classes,activation='softmax'))
#loss和optimizer是两个必须参数,用于指定优化方向,具体请参考本文前面给的文档
model.compile(loss='categorical_crossentropy',optimizer='rmsprop',
metrics=['accuracy','categorical_crossentropy'])
#给定输入和epochs数,进行运算,validation_split指定了测试集占全数据的比例,shuffle为False则不打乱数据
history = model.fit(x,y,epochs=100,batch_size=batch_size,validation_split=0.1,verbose=2,shuffle=False)
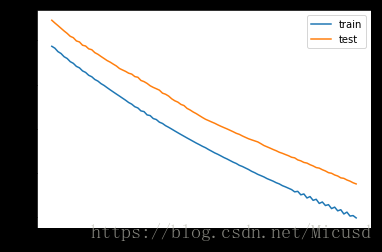
#图形化
import matplotlib.pyplot as pyplot
pyplot.plot(history.history['loss'],label='train')
pyplot.plot(history.history['val_loss'],label='test')
pyplot.legend()
pyplot.show()运行结果如下(已经循环了200次了):

图形化的loss,还有待进一步训练: