题记: 有时候 统一与规范可以解决很多问题。
曾经使用C++进行文件操作一直困惑我,为什么中文就乱码了呢?为什么在NotePad++上能够正常显示,然而在NotePad上显示行号就乱了呢?
解决上述问题,和题记相呼应,统一编码格式就能够解决所有的困惑。NotePad++支持多种编码,NotePad作为小弟自然比不上,现在让我一一介绍实现小弟支持的编码格式 ANSI, Unicode, Unicode big endian, UTF-8。
保存为ANSI编码文件
ANSI 的”Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。
#include <iostream>
#include <fstream>
#include <locale>
using namespace std;
int main()
{
// setlocale(LC_ALL, "zh_CN.UTF-8");
// std::locale::global(std::locale("chs"));
wstring content = L"[我是中国人! I'm a Chinese!我是中国人!";
wofstream ofs("save_as_ansi.txt", ios::ate);
ofs.write(content.c_str(), content.size());
ofs.close();
return 0;
}OK,运行上面代码,你兴高彩烈打开“save_as_ansi.txt”,What!怎么只有一个 [ 可见,其实别慌,只需要反注释内容就正常显示了。
setlocale:
头文件:locale.h
char* setlocale(int category, const char* locale)
设置所有C语言与本地环境相关的C函数的locale。当你傻傻分不清或不愿意去查到底哪些函数,在C++代码里加上它,就能解决潜在的问题。
std::locale::global:
头文件:locale
声 明:static locale global( const locale& loc );
替换全局 C++ 与本地环境相关的函数的locale, 返回系统原先的locale。
保存为UTF-8编码文件
实际上utf-8编码文件还可以分为包含BOM和无BOM两种文件,区分就在文件头。
实现它很麻烦,自从有了C11之后就很简单了,但是请不要在MAC OS7及其以下使用,因为系统根本不支持C11。你只能采用平台object-c的API实现了。
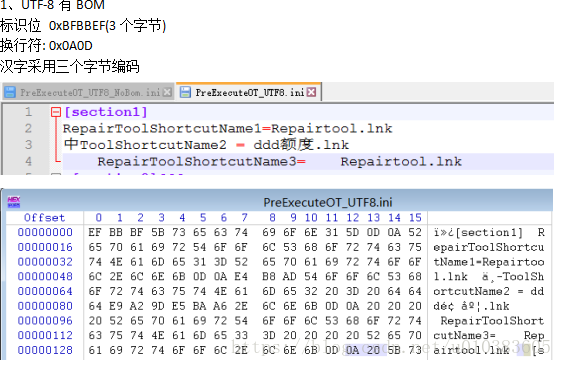
UTF-8 With Bom
#include <iostream>
#include <fstream>
#include <codecvt>
#include <locale>
using namespace std;
int main()
{
wstring content = L"[我是中国人! I'm a Chinese!我是中国人!";
wofstream ofs("save_as_utf_8_bom.txt", ios::ate);
ofs.imbue(std::locale(ofs.getloc(), new std::codecvt_utf8<wchar_t, 0x10ffff, std::generate_header>));
ofs << content;
ofs.close();
return 0;
}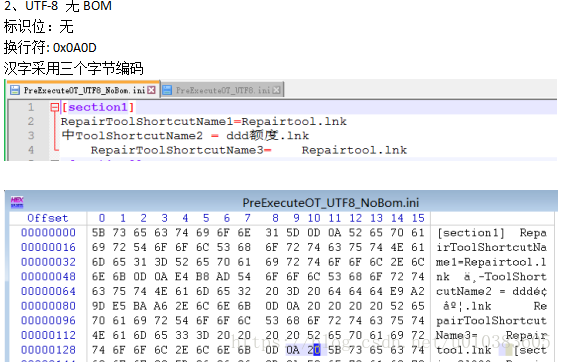
UTF-8 Without Bom
#include <iostream>
#include <fstream>
#include <codecvt>
#include <locale>
using namespace std;
int main()
{
wstring content = L"[我是中国人! I'm a Chinese!我是中国人!";
wofstream ofs("save_as_utf_8_no_bom.txt", ios::ate);
ofs.imbue(std::locale(ofs.getloc(), new std::codecvt_utf8<wchar_t, 0x10ffff, std::little_endian>));
ofs << content;
ofs.close();
return 0;
}区别仅在codecvt_utf8模板参数最后一位。
保存为Unicode编码文件
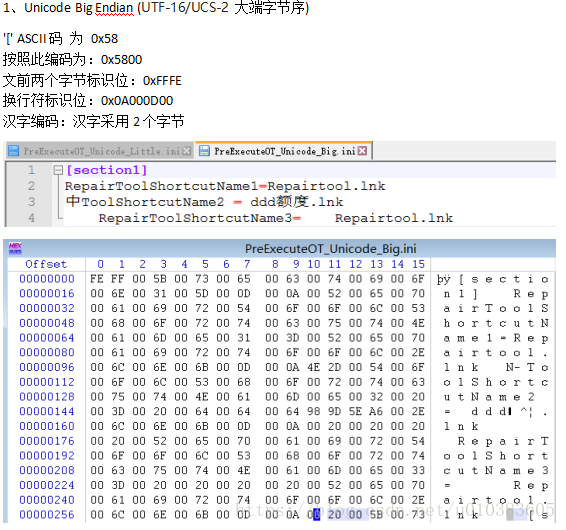
UCS-2 大端
#include <iostream>
#include <fstream>
#include <codecvt>
#include <locale>
using namespace std;
int main()
{
wstring content = L"[我是中国人! I'm a Chinese!我是中国人!";
wofstream ofs("save_as_ucs2_big.txt", ios::ate);
ofs.imbue(std::locale(ofs.getloc(), new std::codecvt_utf16<wchar_t, 0x10ffff, std::generate_header>));
ofs << content;
ofs.close();
return 0;
}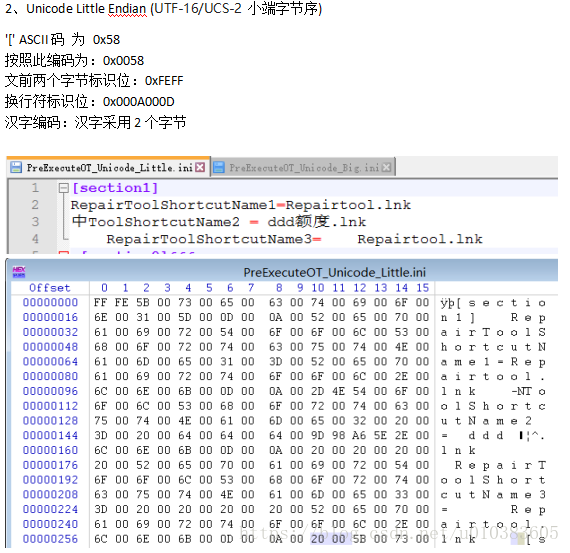
按照前面的思路,实现就很简单了,C11为你做好了,请看 std::codecvt_utf16
UCS-2 小端
#include <iostream>
#include <fstream>
#include <codecvt>
#include <locale>
using namespace std;
int main()
{
wstring content = L"[我是中国人! I'm a Chinese!我是中国人!";
wofstream ofs("save_as_ucs2_little.txt", ios::ate);
ofs.imbue(std::locale(ofs.getloc(), new std::codecvt_utf16<wchar_t, 0x10ffff, (std::codecvt_mode)3>));
ofs << content;
ofs.close();
return 0;
}注意小端的模式掩码变为1|2,即:
enum codecvt_mode {
consume_header = 4,
generate_header = 2,
little_endian = 1
};尾语:我对C++的技能要求是能够熟练运用就好了。如果你要做语言编码库,或者更加底层的开发,那么请尽量阅读官方文档。以前是做C++开发,现在Python是我的主战场,做一名优秀的Pyhton开发者,朝着高级系统架构师发展。
加好友一起学习
如果你和我一样热爱开发,请加为好友,一起学习吧。如果你是单身女性开发者,加好友认识呗!。