原文在这里 https://www.cnblogs.com/malecrab/p/5300503.html
Unicode编码点分为17个平面(plane),每个平面包含216(即65536)个码位(code point)。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从0016到1016,共计17个平面。
2. UTF-32与UCS-4
在Unicode与ISO 10646合并之前,ISO 10646标准为“通用字符集”(UCS)定义了一种31位的编码形式(即UCS-4),其编码固定占用4个字节,编码空间为0x00000000~0x7FFFFFFF(可以编码20多亿个字符)。
UCS-4有20多亿个编码空间,但实际使用范围并不超过0x10FFFF,并且为了兼容Unicode标准,ISO也承诺将不会为超出0x10FFFF的UCS-4编码赋值。由此UTF-32编码被提出来了,它的编码值与UCS-4相同,只不过其编码空间被限定在了0~0x10FFFF之间。因此也可以说:UTF-32是UCS-4的一个子集。
3. UTF-16与UCS-2
除了UCS-4,ISO 10646标准为“通用字符集”(UCS)定义了一种16位的编码形式(即UCS-2),其编码固定占用2个字节,它包含65536个编码空间(可以为全世界最常用的63K字符编码,为了兼容Unicode,0xD800-0xDFFF之间的码位未使用)。例:“汉”的UCS-2编码为6C49。
但俩个字节并不足以正真地“一统江湖”(a fixed-width 2-byte encoding could not encode enough characters to be truly universal),于是UTF-16诞生了,与UCS-2一样,它使用2个字节为全世界最常用的63K字符编码,不同的是,它使用4个字节对不常用的字符进行编码。UTF-16属于变长编码,UTF-16 (16-bit Unicode Transformation Format)是UCS-2的拓展。
注:即使是ASCII字符,utf-16 一样使用两个字节来编码。
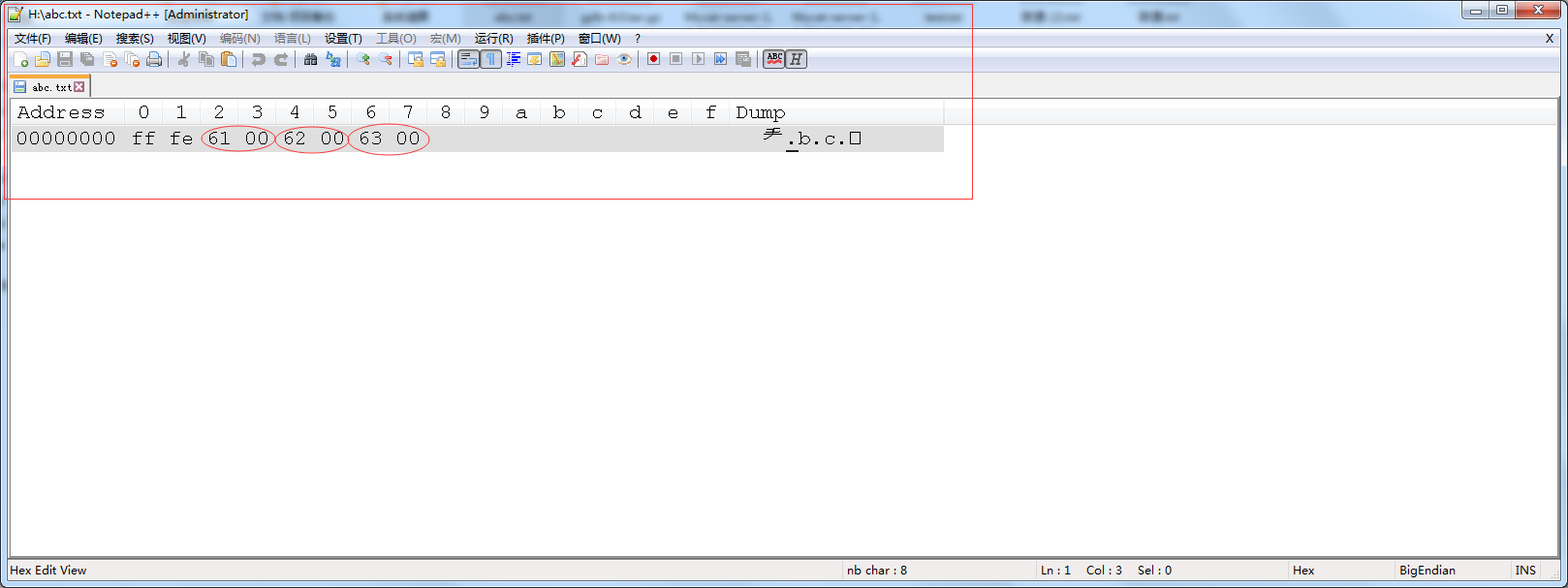
使用 notepad++ 的十六进制插件查看文本内容为 abc 的文件,前边的ff fe为小端的BOM. 大端的BOM为fe ff. Windows上的 utf 编码默认的就是 utf-16 带小端BOM的。
前面提到过:Unicode编码点分为17个平面(plane),每个平面包含216(即65536)个码位(code point),而第一个平面称为“基本多语言平面”(Basic Multilingual Plane,简称BMP),其余平面称为“辅助平面”(Supplementary Planes)。其中“基本多语言平面”(0~0xFFFF)中0xD800~0xDFFF之间的码位作为保留,未使用。UCS-2只能编码“基本多语言平面”中的字符,此时UTF-16与UCS-2的编码一样(都直接使用Unicode的码位作为编码值),例:“汉”在Unicode中的码位为6C49,而在UTF-16编码也为6C49。另外,UTF-16还可以利用保留下来的0xD800-0xDFFF区段的码位来对“辅助平面”的字符的码位进行编码,因此UTF-16可以为Unicode中所有的字符编码。
UTF-8的编码规则:
(1) 对于ASCII码中的符号,使用单字节编码,其编码值与ASCII值相同(详见:U0000.pdf)。其中ASCII值的范围为0~0x7F,所有编码的二进制值中第一位为0(这个正好可以用来区分单字节编码和多字节编码)。
(2) 其它字符用多个字节来编码(假设用N个字节),多字节编码需满足:第一个字节的前N位都为1,第N+1位为0,后面N-1个字节的前两位都为10,这N个字节中其余位全部用来存储Unicode中的码位值。
| 字节数 | Unicode | UTF-8编码 |
|---|---|---|
| 1 | 000000-00007F | 0xxxxxxx |
| 2 | 000080-0007FF | 110xxxxx 10xxxxxx |
| 3 | 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
注:utf-8 的编码规则使 utf-8并不需要BOM,不过 windows 上存在加了 BOM 的 utf-8,标志是 ef bb bf.
将上边的文件,菜单选中中选中 utf-8 编码,再用十六进制插件查看,内容如下:

python3 中的字符串都是 unicode 编码了,使用python qtconsole,方便查看字符串的各种编码之后的十六进制:


f = open("中国.txt", mode="r", encoding="utf-16")
这样指定文件的编码打开文本文件,读取时,文本内容自动从 utf-16 编码转换为 utf-8 编码读取到python当中。
5. 总结
(1) 简单地说:Unicode属于字符集,不属于编码,UTF-8、UTF-16等是针对Unicode字符集的编码。
(2) UTF-8、UTF-16、UTF-32、UCS-2、UCS-4对比:
| 对比 | UTF-8 | UTF-16 | UTF-32 | UCS-2 | UCS-4 |
|---|---|---|---|---|---|
| 编码空间 | 0-10FFFF | 0-10FFFF | 0-10FFFF | 0-FFFF | 0-7FFFFFFF |
| 最少编码字节数 | 1 | 2 | 4 | 2 | 4 |
| 最多编码字节数 | 4 | 4 | 4 | 2 | 4 |
| 是否依赖字节序 | 否 | 是 | 是 | 是 | 是 |
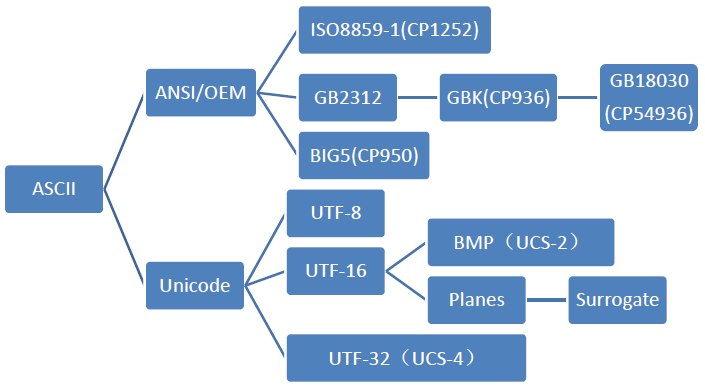
注:关系图