1、临近性用距离度量:比如欧几里得距离,两个点或者元组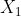 (
(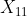 ,
,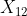 ,
,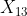 ,
,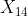 .......
.......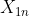 )和
)和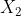 (
(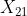 ,
,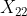 ,
,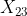 ,
,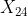 .......
.......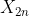 )d的距离是
)d的距离是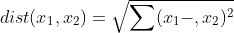 ,换而言之,对于每个数值属性,取元祖,
,换而言之,对于每个数值属性,取元祖,
该属性对应值的差,取差的平方并累计,并取累计距离技术的平方根,通常在使用上述公式之前,要将每个属性进行规范化,这样有助于防止具有较大初始值域的属性(收入)比具有较小初始值域(如二元属性)的属性的权重过大。可以通过如下公式进行规范化,使用最小——最大规范化将数值属性A的值v变换到[0,1]之间的,min和max分别代表属性A中的最大值和最小值。另外一种标准化的方式是中心化处理
2、但是如果属性不是数值而是分类的(比如颜色),如何计算他们之间的距离,上面计算距离的方法主要是属性A的值都是数值型的,对于分类属性,一种简单的方法,是比较元组,
对应属性的值。如果二者相同,例如二者都是蓝色(
的属性值是蓝色,
的属性值是蓝色),则二者的之间的差值是0.如果二者去不同的颜色,(
的属性值是红色,
的属性值是蓝色)一个是蓝色,一个是红色,则二者之间的差为1。其他方法可能采用更复杂的方案(例如,对蓝色和白色赋予比蓝色和黑色更大的差值)
3、遇到缺失值的解决办法。假设,
对应属性A的值,假定每个属性值都被映射到[0,1]之间。对于分类变量(属性),
,
中A属性对应的值如果一个或者两个缺失,就取差值为1。对于数值型,如果对应的
,
都缺失,其差值取1.如果一个值缺失,而另一个存在并且已经规范化,则取差1-
和-
的绝对值的最大者。
4、k值得取值方法为了避免欠拟合和过拟合的问题,一般取值是在3~10之间。一种常见的做法就是设置k等于训练集中案例数量的平方根。另一种是基于各种测试集来测试多个k值,并选择一个可以提供最好分类性能的k值。