本文以爬取第一战文章中获得的各个url为地址,爬取其中文章内容。
先小叙述下xpath的表达式意思
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
已知url地址和header属性,那让我们来查找节点位置。
以关于报送2018-2019学年第一学期实验、实习教学计划及安排的通知为例
图片:
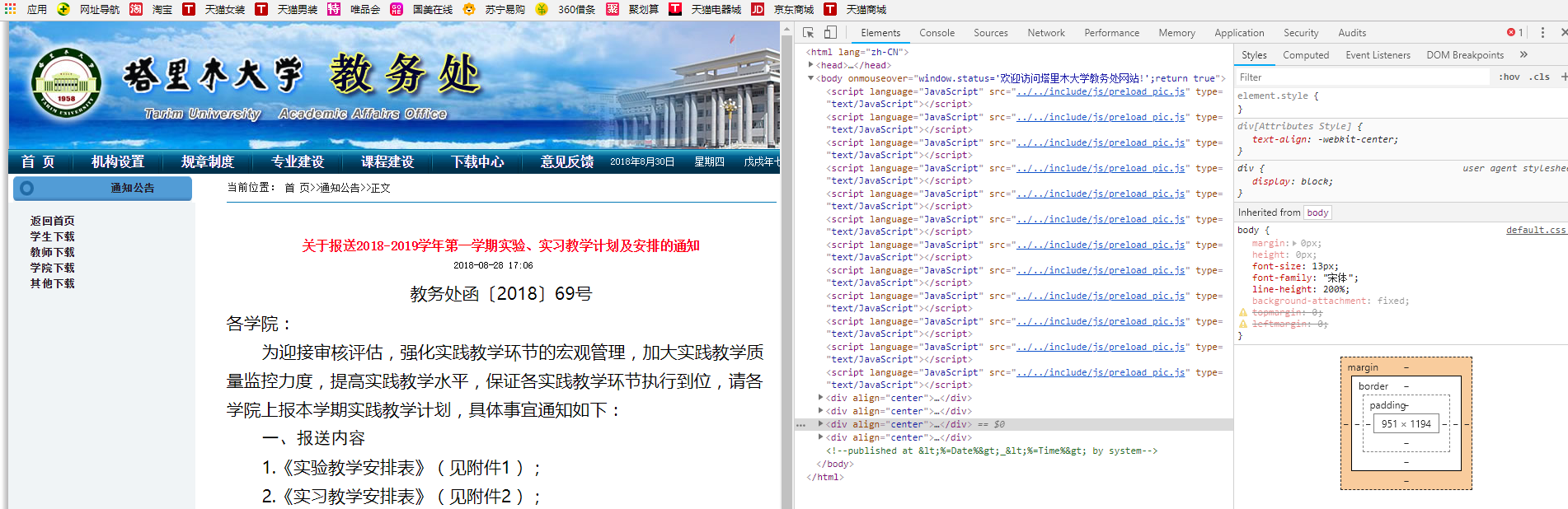
chrome浏览器网页界面打开检查即可。
并点击
在网页文章部分进行选取点击,即可在代码中到达原文位置。

因为这代码的文本信息非常散乱,我们使用正则表达式很难有效快速的将所需文字内容全部选取。则我们使用xpath。
找到其节点位置,并精确定位。这里大伙可以自己去找找看,我直接给出我的xpath路径和代码了。
xpath路径 //div[@align="center"]//div[contains(@class,"c11807_content")]//span/text()
import requests from lxml import etree link = "http://jwc.taru.edu.cn/info/10610/271846.htm" headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", "Host":"jwc.taru.edu.cn" } r = requests.get(link,headers= headers) r.encoding='utf-8' text = r.text html = etree.HTML(text) result = html.xpath('//div[@align="center"]//div[contains(@class,"c11807_content")]//span/text()') str = ''; for eachone in result : str = str + eachone print(str)
这样我们就将文章全部给爬下来了。