Hibernate面试题经典汇总
Hibernate作为java技术大家族中举足轻重的数据处理层的框架所在,在前几年的深受java软件工程师的喜爱,虽然在现在新的java项目中被新框架所取代应用已经没有之前的那么多了,但是谁也不能否认Hibernate的强大。
虽然用的少了但是Hibernate作为经典框架所在包含了很多java所应用技术的精华所在,因此在日常的java面试中总能够见到几个关于Hibernate方面的题目。
下面就为大家在Hibernate面试题中常出现的题目最一个简单的总结。
1.Hibernate是如何延迟加载?
. Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)
. Hibernate3 提供了属性的延迟加载功能
当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而
提高了服务器的性能。
2.Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都市对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、
one-to-many、many-to-many、
3. 说下Hibernate的缓存机制
. 内部缓存存在Hibernate中又叫一级缓存,属于应用事物级缓存
. 二级缓存:

a) 应用及缓存
b) 分布式缓存
条件:数据不会被第三方修改、数据大小在可接受范围、数据更新频率低、同一数据被系统频繁使用、非关键数据
c) 第三方缓存的实现
4. Hibernate的查询方式
Session.get Session.load
Sql、Criteria,object comptosition
Hql:
1、 属性查询
2、 参数查询、命名参数查询
3、 关联查询
4、 分页查询
5、 统计函数
5. 如何优化Hibernate?
.使用双向一对多关联,不使用单向一对多
.灵活使用单向一对多关联
.不用一对一,用多对一取代
.配置对象缓存,不使用集合缓存
.一对多集合使用Bag,多对多集合使用Set
.继承类使用显式多态
.表字段要少,表关联不要怕多,有二级缓存撑腰
6. get和load区别;
1)get如果没有找到会返回null, load如果没有找到会抛出异常。
2)get会先查一级缓存, 再查二级缓存,然后查数据库;load会先查一级缓存,如果没有找到,就创建代理对象,等需要的时候去查询二级缓存和数据库。
7. N+1问题。
Hibernate中常会用到set,bag等集合表示1对多的关系, 在获取实体的时候就能根据关系将关联的对象或者对象集取出。
解决方法一个是延迟加载, 即lazy=true;
一个是预先抓取, 即fetch=join;
8. inverse的好处。
在关联关系中用inverse在控制由哪一端来控制关联关系。这样做有什么好处呢?举customer和order的例子来说。他们是一对多的关系,如果只单向关联,且由customer控制关联关系,则如果我想添加一个order,则先取customer, 然后getOrders得到所有的order集合,然后往集合里面多加入一个order,然后save(customer), 这样开销太大。 如果改双向关联且由order主控关系,则如果想为customer增加一个order, 则new一个order,然后给order设置customer,然后save(order)即可。
9 ,merge的含义:
http://cp3.iteye.com/blog/786019 这里写的好;
如果session中存在相同持久化标识(identifier)的实例,用用户给出的对象的状态覆盖旧有的持久实例
如果session没有相应的持久实例,则尝试从数据库中加载,或创建新的持久化实例
最后返回该持久实例
用户给出的这个对象没有被关联到session上,它依旧是脱管的
10, persist和save的区别
persist不保证立即执行,可能要等到flush;persist不更新缓存;
11, cascade,用来指示在主对象和它包含的集合对象的级联操作行为,即对住对象的更新怎么影响到子对象;
save-update: 级联保存(load以后如果子对象发生了更新,也会级联更新). 但它不会级联删除
delete: 级联删除, 但不具备级联保存和更新
all-delete-orphan: 在解除父子关系时,自动删除不属于父对象的子对象, 也支持级联删除和级联保存更新.
all: 级联删除, 级联更新,但解除父子关系时不会自动删除子对象.
delete-orphan:删除所有和当前对象解除关联关系的对象
12.怎么配置Hibernate?
A.Configuration类使用配置hibernate.cfg.xml(或者hibernate.properties)以及映射文件*.hbm.xml来创建(例如,配置和引导hibernate)SessionFactory,然后SessionFactory创建Session的实例。Session的实例是持久层服务对外提供的主要接口。
hibernate.cfg.xml(或者你也可以使用hibernate.properties):这两个文件都是用来配置hibernate服务(数据库连接的驱动类,连接URL,用户名,密码,方言等)。如果这两个文件同时存在于classpath里的话,那么hibernate.cfg.xml会覆盖hibernate.properties文件里的配置。
映射文件(*.hbm.xml):这些文件都是用来对持久层对象和关系数据库进行映射的。最好的方式是对每个对象都使用单独的映射文件(例如一个类一个文件),因为如果在一个文件里存放大量的持久层对象,那么这个文件就变得非常难管理和维护。约定的命名方式是映射文件名和持久层类名(POJO)保持一致。例如,Account.class的映射文件名为Account.hbm.xml。或者,你也可以在类文件的代码里加上hibernate的注解,从而不需要使用配置文件。
13.解释hibernate对象的状态?解释hibernate对象的生命周期?
A.持久层(persistent )对象和集合都是存活时间短暂的单线程对象,它们保存持久层的状态。这些对象的状态会根据你的刷新规则(例如,一旦有setXXX()方法被调用了就自动刷新,或者有数据项从集合、列表等删除时就刷新,你也可以通过session.flush()和transaction.commit()这两个函数调用来定义你自己的同步策略)来与数据库保持同步。如果你从一个持久层的集合(例如Set)里删除一项,那么它要么被立即从数据库里删除,或者当flush()或则commit()方法被调用时删除,具体的表现取决于你的刷新策略。它们都是普通的Java对象(POJO,Plain Old Java Object),只不过当前关联了一个session。一旦关联的session被关闭,持久层对象就成为了游离对象(detached object),这时候你就可以在随便使用它们了,就像是用在业务层,持久层等其他应用层面的数据传输对象一样。
游离(detached )对象和集合都是和session相关联的持久层对象的实例,只不过它们现在没有和session进行关联。这种对象可以被随便使用,它不会对你的数据库有任何影响。游离对象后面也可以通过调用类似session.update(),session.saveOrUpdate()等方法来依附到其他的session上,然后再次成为持久层对象。
瞬态(transient)对象和集合是从来没有和session相关联的持久层对象的实例。这些对象可以自由使用,并且不会对你的数据库造成任何影响。当通过session.save(),session.persist()方法来使得瞬态对象和一个session进行关联时,瞬态对象就成为了持久层对象。
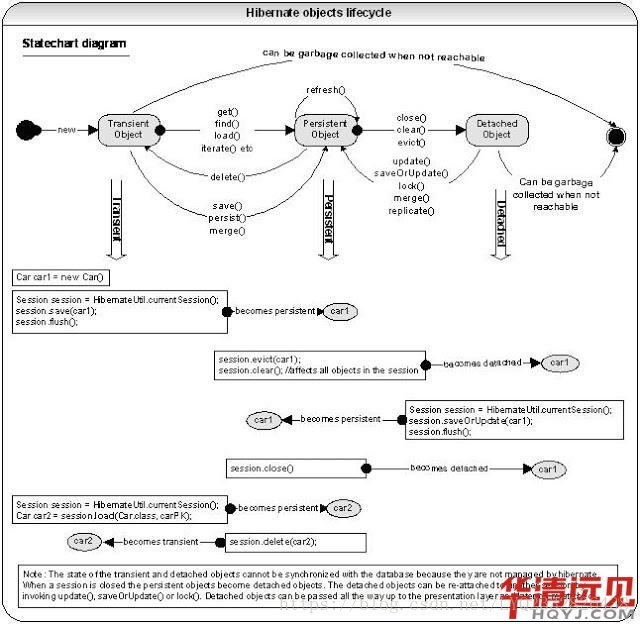
14,Hibernate中save、persist和saveOrUpdate这三个方法的不同之处?
除了get和load,这又是另外一个经常出现的Hibernate面试问题。 所有这三个方法,也就是save()、saveOrUpdate()和persist()都是用于将对象保存到数据库中的方法,但其中有些细微的差别。例如,save()只能INSERT记录,但是saveOrUpdate()可以进行记录的INSERT和UPDATE。还有,save()的返回值是一个Serializable对象,而persist()方法返回值为void。你还可以访问 save、persist以及saveOrUpdate,找到它们所有的不同之处。,
15,Hibernate中的命名SQL查询指的是什么?
Hibernate的这个面试问题同Hibernate提供的查询功能相关。命名查询指的是用标签在影射文档中定义的SQL查询,可以通过使用Session.getNamedQuery()方法对它进行调用。命名查询使你可以使用你所指定的一个名字拿到某个特定的查询。 Hibernate中的命名查询可以使用注解来定义,也可以使用我前面提到的xml影射问句来定义。在Hibernate中,@NameQuery用来定义单个的命名查询,@NameQueries用来定义多个命名查询。
16,Hibernate中的SessionFactory有什么作用? SessionFactory是线程安全的吗?
这也是Hibernate框架的常见面试问题。顾名思义,SessionFactory就是一个用于创建Hibernate的Session对象的工厂。SessionFactory通常是在应用启动时创建好的,应用程序中的代码用它来获得Session对象。作为一个单个的数据存储,它也是 线程安全的,所以多个线程可同时使用同一个SessionFactory。Java JEE应用一般只有一个SessionFactory,服务于客户请求的各线程都通过这个工厂来获得Hibernate的Session实例,这也是为什么SessionFactory接口的实现必须是线程安全的原因。还有,SessionFactory的内部状态包含着同对象关系影射有关的所有元数据,它是 不可变的,一旦创建好后就不能对其进行修改了。
17.选择题区
1. 级联删除时,cascade属性是( c )。
A. all
B. save
C. delete
D. save-update
2. 以下不属于Cascade的属性取值的有( b )。
A. all
B. save
C. delete
D. save-update
3. 关于HQL查询,下列说法中错误的是( A )。
A. HQL查询的select子句中必须区分大小写
B. HQL支持统计函数
C. HQL支持仅查询对象的某几个属性,并将查询结果保存在Object数组中
D. HQL语句可以实现类似于PreparedStatement的效果
4. 由持久化状态向游离状态转变的方法不包括( C)。
A. 临时状态
B. 无引用状态
C. 持久化状态
D. 游离状态
5. 关于HQL与SQL,以下哪些说法正确?(B)。
A. HQL与SQL没什么差别
B. HQL面向对象,而SQL操纵关系数据库
C. 在HQL与SQL中,都包含select,insert,update,delete语句
D. HQL仅用于查询和删除数据,不支持insert,update语句
6. 下面关于Hibernate说法正确的是(BD)。(选择两项)
A. Hibernate是ORM的一种实现方式
B. Hibernate不要JDBC的支持
C. 属于控制层
D. 属于数据持久层
7. 下面关于Hibernate中load和get方法说法正确的是(D)。
A. 这两个方法是一样的,没有任何的区别
B. 这两个方法不一样,laod先找缓存,再找数据库
C. 这两个方法不一样,get先找缓存,再找数据库
D. 以上说法都不对
8. 关于Hibernate中关系的说话正确的是(A)。
A. 一对多必须用Set来映射
B. 多对一必须用Set来映射
C. 一对多可以用Set来映射,也可以用List、Map来映射
D. 多对一可以用Set来映射,也可以用List、Map来映射
9. 以下关于SessionFactory的说法哪些正确?( C)。
A. 对于每个数据库事务,应该创建一个SessionFactory对象
B. 一个SessionFactory对象对应多个数据库存储源
C. SessionFactory是重量级的对象,不应该随意创建。如果系统中只有一个数据库存储源,只需要创建一个
D. SessionFactory的load()方法用于加载持久化对象
10. 在使用了Hibernate的系统中,要想在删除某个客户数据的同时删除该客户对应的所有订单数据,下面方法可行的是(A)。
A. 配置客户和订单关联的cascade属性为save-update
B. 配置客户和订单关联的cascade属性为all
C. 设置多对一关联的inverse属性为true
D. 设置多对一关联的inverse属性为false
11在三层结构中,数据访问层承担的责任是()
a)定义实体类
b)数据的增删改查操作
c)业务逻辑的描述
d)页面展示和控制转发
12下面关于数据持久化概念的描述,错误的是()〔选择一项〕
a)保存在内存中数据的状态是瞬时状态
b)持久状态的数据在关机后数据依然存在
c)数据可以由持久状态转换为瞬时状态
d)将数据转换为持久状态的机制称为数据持久化
13.下面( ab)不是Hibernate 映射文件中包含的内容。(选两项)
A.数据库连接信息
B.Hibernate 属性参数
C.主键生成策略
D.属性数据类型
14. Hibernate对象从临时状态到持久状态转换的方式有?( A)。
A. 调用session的save方法
B. 调用session的close方法
C. 调用session的clear方法
D. 调用session的evict方法
15下面关于Hibernate的说法,错误的是()〔选择一项〕
a) Hibernate是一个”对象-关系映射”的实现
b) Hibernate是一种数据持久化技术
c) Hibernate是JDBC的替代技术
d) 使用Hibernate可以简化持久化层的编码
16Hibernate配置文件中,不包含下面的()〔选择二项〕
a) “对象-关系映射”信息
b) 实体间关联的配置
c) show_sql等参数的配置
d) 数据库连接信息
17下面不是Hibernate映射文件中包含的内容。(选两项)
a) 数据库连接信息
b) Hibernate属性参数
c) 主键生成策略·
d) 属性数据类型
18在使用了Hibernate的系统中,要想在删除某个客户数据的同时删除该客户对应的所有订单数据,下面方法可行的是()。〔选择一项〕
a) 配置客户和订单关联的cascade属性为save-update
b) 配置客户和订单关联的cascade属性为all
c) 设置多对一关联的inverse属性为true
d) 设置多对一关联的inverse属性为false
19以下程序的打印结果是什么?
tx = session.beginTransaction();
Customer c1=(Customer)session.load(Customer.class,new Long(1));
Customer c2=(Customer)session.load(Customer.class,new Long(1));
System.out.println(c1==c2);
tx.commit();
session.close();
a) 运行出错,抛出异常
b) 打印false
c) 打印true
d) 编译出错
了解
在Java J2EE方面进行面试时,常被问起的Hibernate面试问题,大多都是针对基于Web的企业级应用开发者的角色的。Hibernate框架在Java界的成功和高度的可接受性使得它成为了Java技术栈中最受欢迎的对象关系影射(ORM)解决方案。Hibernate将你从数据库相关的编码中解脱了出来,使你可以更加专注地利用强大的面向对象的设计原则来实现核心的业务逻辑。采用Hibernate后,你就能够相当容易地在不同的数据库间进行切换,而且你还可以利用Hibernate提供的开箱即用的二级缓存以及查询缓存功能。你也知道,大部分Java面试中所提的问题不仅仅会涉及Java的核心部分,而且还会涉及其它的Java框架,比如,根据项目的要求也有可能会问到Spring 框架方面的问题或者Struts方面的问题。如果你要参加的项目使用了Hibernate作为ORM解决方案,你就应该同时准备好回答Spring和Hibernate这两个框架方面的问题。好好看看JD或者职位说明,如果其中的任何地方出现了Hibernate这个词,就要准备好怎样来面对Hibernate方面的问题。
本文给出了一个Hibernate面试问题列表,这些都是我从朋友以及同事那里搜集来的。Hibernate 是一个非常流行的对象关系影射框架,熟捻Hibernate的优势所在以及Hibernate的Sesion API是搞定Hibernate面试之关键所在。
18.Hibernate中get和load有什么不同之处?
把get和load放到一起进行对比是Hibernate面试时最常问到的问题,这是因为只有正确理解get()和load()这二者后才有可能高效地使用Hibernate。get和load的最大区别是,如果在缓存中没有找到相应的对象,get将会直接访问数据库并返回一个完全初始化好的对象,而这个过程有可能会涉及到多个数据库调用;而load方法在缓存中没有发现对象的情况下,只会返回一个代理对象,只有在对象getId()之外的其它方法被调用时才会真正去访问数据库,这样就能在某些情况下大幅度提高性能。你也可以参考 Hibernate中get和load的不同之处, 此链接给出了更多的不同之处并对该问题进行了更细致的讨论。
19Hibernate中save、persist和saveOrUpdate这三个方法的不同之处?
除了get和load,这又是另外一个经常出现的Hibernate面试问题。 所有这三个方法,也就是save()、saveOrUpdate()和persist()都是用于将对象保存到数据库中的方法,但其中有些细微的差别。例如,save()只能INSERT记录,但是saveOrUpdate()可以进行 记录的INSERT和UPDATE。还有,save()的返回值是一个Serializable对象,而persist()方法返回值为void。你还可以访问 save、persist以及saveOrUpdate,找到它们所有的不同之处。
20Hibernate中的命名SQL查询指的是什么?
Hibernate的这个面试问题同Hibernate提供的查询功能相关。命名查询指的是用<sql-query>标签在影射文档中定义的SQL查询,可以通过使用Session.getNamedQuery()方法对它进行调用。命名查询使你可以使用你所指定的一个名字拿到某个特定的查询。 Hibernate中的命名查询可以使用注解来定义,也可以使用我前面提到的xml影射问句来定义。在Hibernate中,@NameQuery用来定义单个的命名查询,@NameQueries用来定义多个命名查询。
21Hibernate中的SessionFactory有什么作用? SessionFactory是线程安全的吗?
这也是Hibernate框架的常见面试问题。顾名思义,SessionFactory就是一个用于创建Hibernate的Session对象的工厂。SessionFactory通常是在应用启动时创建好的,应用程序中的代码用它来获得Session对象。作为一个单个的数据存储,它也是 线程安全的,所以多个线程可同时使用同一个SessionFactory。Java JEE应用一般只有一个SessionFactory,服务于客户请求的各线程都通过这个工厂来获得Hibernate的Session实例,这也是为什么SessionFactory接口的实现必须是线程安全的原因。还有,SessionFactory的内部状态包含着同对象关系影射有关的所有元数据,它是 不可变的,一旦创建好后就不能对其进行修改了。
22.Hibernate中的Session指的是什么? 可否将单个的Session在多个线程间进行共享?
前面的问题问完之后,通常就会接着再问这两个问题。问完SessionFactory的问题后就该轮到Session了。Session代表着Hibernate所做的一小部分工作,它负责维护者同数据库的链接而且 不是线程安全的,也就是说,Hibernage中的Session不能在多个线程间进行共享。虽然Session会以主动滞后的方式获得数据库连接,但是Session最好还是在用完之后立即将其关闭。
23.hibernate中sorted collection和ordered collection有什么不同?
这个是你会碰到的所有Hibernate面试问题中比较容易的问题。sorted collection是通过使用 Java的Comparator在内存中进行排序的,ordered collection中的排序用的是数据库的order by子句。对于比较大的数据集,为了避免在内存中对它们进行排序而出现 Java中的OutOfMemoryError,最好使用ordered collection。
24Hibernate中transient、persistent、detached对象三者之间有什么区别?
在Hibernate中,对象具有三种状态:transient、persistent和detached。同Hibernate的session有关联的对象是persistent对象。对这种对象进行的所有修改都会按照事先设定的刷新策略,反映到数据库之中,也即,可以在对象的任何一个属性发生改变时自动刷新,也可以通过调用Session.flush()方法显式地进行刷新。如果一个对象原来同Session有关联关系,但当下却没有关联关系了,这样的对象就是detached的对象。你可以通过调用任意一个session的update()或者saveOrUpdate()方法,重新将该detached对象同相应的seesion建立关联关系。Transient对象指的是新建的持久化类的实例,它还从未同Hibernate的任何Session有过关联关系。同样的,你可以调用persist()或者save()方法,将transient对象变成persistent对象。可要记住,这里所说的transient指的可不是 Java中的transient关键字,二者风马牛不相及。
25.Hibernate中Session的lock()方法有什么作用?
这是一个比较棘手的Hibernate面试问题,因为Session的lock()方法重建了关联关系却并没有同数据库进行同步和更新。因此,你在使用lock()方法时一定要多加小心。顺便说一下,在进行关联关系重建时,你可以随时使用Session的update()方法同数据库进行同步。有时这个问题也可以这么来问:Session的lock()方法和update()方法之间有什么区别?。这个小节中的关键点也可以拿来回答这个问题。
26.Hibernate中二级缓存指的是什么?
这是同Hibernate的缓存机制相关的第一个面试问题,不出意外后面还会有更多这方面的问题。二级缓存是在SessionFactory这个级别维护的缓存,它能够通过节省几番数据库调用往返来提高性能。还有一点值得注意,二级缓存是针对整个应用而不是某个特定的session的。
27.Hibernate中的查询缓存指的是什么?
这个问题有时是作为上个Hibernate面试问题的后继问题提出的。查询缓存实际上保存的是sql查询的结果,这样再进行相同的sql查询就可以之间从缓存中拿到结果了。为了改善性能,查询缓存可以同二级缓存一起来使用。Hibernate支持用多种不同的开源缓存方案,比如EhCache,来实现查询缓存。
28.为什么在Hibernate的实体类中要提供一个无参数的构造器这一点非常重要?
每个Hibernate实体类必须包含一个 无参数的构造器, 这是因为Hibernate框架要使用Reflection API,通过调用Class.newInstance()来创建这些实体类的实例。如果在实体类中找不到无参数的构造器,这个方法就会抛出一个InstantiationException异常。
29.可不可以将Hibernate的实体类定义为final类?
是的,你可以将Hibernate的实体类定义为final类,但这种做法并不好。因为Hibernate会使用代理模式在延迟关联的情况下提高性能,如果你把实体类定义成final类之后,因为 Java不允许对final类进行扩展,所以Hibernate就无法再使用代理了,如此一来就限制了使用可以提升性能的手段。不过,如果你的持久化类实现了一个接口而且在该接口中声明了所有定义于实体类中的所有public的方法轮到话,你就能够避免出现前面所说的不利后果。
Java开发者的Hibernate面试问答列表就到此为止了。没人会对Hibernate作为ORM解决方案的受欢迎程度产生怀疑,如果你要申请的是Java J2EE方面的职位,你就等着人来问你Hibernate方面的面试问题吧。在JEE界,Spring和Hibernate是两个最流行的Java框架。要是你被问到了其它也值得分享的Hibernate方面的面试问题, 别忘了在Java社区中同大家分享一下。
无论多复杂,hibernate终究是一个和数据库打交道的框架,与jdbc功能一样。所以没有理由畏惧hibernate. hibernate的难点我觉得有两方面:一是性能优化,二是session管理。性能优化是个经验活; 关于session管理,单纯的hibernate可以使用ThreadLocal来解决, 如果和spring结合,使用spring提供的session管理方案很不错。
hibernate常见面试题:
---------------------------------------------------
http://topic.csdn.net/u/20081207/22/6d6b75f8-3988-484c-ab4f-f388869b2f00.html
http://lpcjrflsa.javaeye.com/blog/325932
30.Hibernate工作原理及为什么要用?
原理:
1.读取并解析配置文件
2.读取并解析映射信息,创建SessionFactory
3.打开Sesssion
4.创建事务Transation
5.持久化操作
6.提交事务
7.关闭Session
8.关闭SesstionFactory
为什么要用:
.对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
.Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
.hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
.hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
31.Hibernate是如何延迟加载?
. Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)
. Hibernate3 提供了属性的延迟加载功能
当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而
提高了服务器的性能。
32.Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都市对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、
one-to-many、many-to-many、
33. 说下Hibernate的缓存机制
. 内部缓存存在Hibernate中又叫一级缓存,属于应用事物级缓存
. 二级缓存:
a) 应用及缓存
b) 分布式缓存
条件:数据不会被第三方修改、数据大小在可接受范围、数据更新频率低、同一数据被系统频繁使用、非关键数据
c) 第三方缓存的实现
34. Hibernate的查询方式
Session.get Session.load
Sql、Criteria,object comptosition
Hql:
1、 属性查询
2、 参数查询、命名参数查询
3、 关联查询
4、 分页查询
5、 统计函数
6. 如何优化Hibernate?
.使用双向一对多关联,不使用单向一对多
.灵活使用单向一对多关联
.不用一对一,用多对一取代
.配置对象缓存,不使用集合缓存
.一对多集合使用Bag,多对多集合使用Set
.继承类使用显式多态
.表字段要少,表关联不要怕多,有二级缓存撑腰
7. get和load区别;
1)get如果没有找到会返回null, load如果没有找到会抛出异常。
2)get会先查一级缓存, 再查二级缓存,然后查数据库;load会先查一级缓存,如果没有找到,就创建代理对象, 等需要的时候去查询二级缓存和数据库。
8. N+1问题。
Hibernate中常会用到set,bag等集合表示1对多的关系, 在获取实体的时候就能根据关系将关联的对象或者对象集取出。
解决方法一个是延迟加载, 即lazy=true;
一个是预先抓取, 即fetch=join;
9. inverse的好处。
在关联关系中用inverse在控制由哪一端来控制关联关系。这样做有什么好处呢?举customer和order的例子来说。他们是一对多的关系,如果只单向关联,且由customer控制关联关系,则如果我想添加一个order,则先取customer, 然后getOrders得到所有的order集合,然后往集合里面多加入一个order,然后save(customer), 这样开销太大。 如果改双向关联且由order主控关系,则如果想为customer增加一个order, 则new一个order,然后给order设置customer,然后save(order)即可。
10 merge的含义:
http://cp3.iteye.com/blog/786019 这里写的好;
如果session中存在相同持久化标识(identifier)的实例,用用户给出的对象的状态覆盖旧有的持久实例
如果session没有相应的持久实例,则尝试从数据库中加载,或创建新的持久化实例
最后返回该持久实例
用户给出的这个对象没有被关联到session上,它依旧是脱管的
11 persist和save的区别
persist不保证立即执行,可能要等到flush;persist不更新缓存;
12 cascade,用来指示在主对象和它包含的集合对象的级联操作行为,即对住对象的更新怎么影响到子对象;
save-update: 级联保存(load以后如果子对象发生了更新,也会级联更新). 但它不会级联删除
delete: 级联删除, 但不具备级联保存和更新
all-delete-orphan: 在解除父子关系时,自动删除不属于父对象的子对象, 也支持级联删除和级联保存更新.
all: 级联删除, 级联更新,但解除父子关系时不会自动删除子对象.
delete-orphan:删除所有和当前对象解除关联关系的对象
13 session.commit 和flush区别, commit会先调用flash执行session清理,然后提交事物; flash执行session,但不一定提交事物(因为事物可能被委托给外围的aop代理来做);
14 session清理的顺序: insert -> update -> delete -> 对集合进行delete -〉对集合的insert;
15 检索策略: 立即检索,lazy=false;延迟加载:lazy=true;预先抓取: fetch=“join”;
16 主键生成 策略有哪些?identity,increment, sequence, assigned, uuid.hex, foreign; foreign是一对一主键关联的情况下使用。