1.比较顺序表和链表的优缺点,说说它们分别在什么场景下使用?
顺序表:内存中地址连续,优点是随机访问比较便捷快速,创建也比较简单,随机查找比较方便,可以直接给出下标,排序也方便 简单。
缺点: 不够灵活,删除增加的工作量叫大,比较麻烦,长度不能实时变化
适用场景:适用于需要大量访问元素的 而少量增添/删除元素的程序
单链表:内存中地址不是连续的,优点是插入删除比较方便,长度可以实时变化。
缺点: 不支持随机查找,查找元素需要遍历。
适用场景 : 适用于需要进行大量增添/删除元素操作 而对访问元素无要求的程序
2.从尾到头打印单链表
void PrintTailToHead(Node* pHead) //递归实现从尾到头打印单链表
{
if (pHead == NULL)
{
return;
}
PrintTailToHead(pHead->next); //递归时,下一次的pHead其实是上一个pHead的next
printf("%d ", pHead->data);
}
3.删
除一个无头单链表的非尾节点
void EraseNonTail(Node* pos) //删除一个无头链表的非尾节点 { Node* next; assert(pos&&pos->next); //pos不能为空也不能为尾 next = pos->next; pos->data = next->data; //先让后面的值覆盖掉前面的值 pos->next = next->next; //再让前面的节点指向后面节点的后面 即1 2 3 4 5变为1 2 4 4 5,再变为1 2 4 5 free(next); //把下一个节点释放掉 }
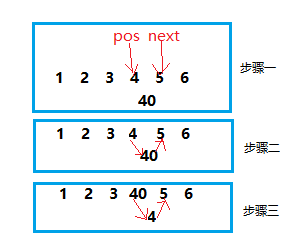
4.在无头单链表的一个节点前插入一个节点
思路一:
先链上,再交换其值。但此方法需要额外编写一个Swap函数,略微复杂。
思路二:
先交换其值,再链接。
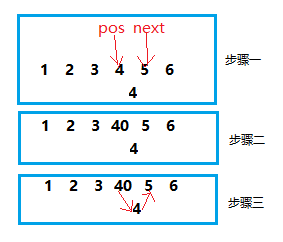
思路二的代码如下:
void InsertFront(Node* pos, DataType x) //在无头单链表的一个节点前插入一个节点
{
Node* next, *tmp;
assert(pos);
next = pos->next; //记录插入点之后的节点
tmp = BuyNode(pos->data); //增容一个节点,其值为插入位置节点的值
pos->data = x; //将要插入节点值赋给插入位置节点
pos->next = tmp; //将其链起来
tmp->next = next;
}
5.单链表实现约瑟夫环
Node* Josephus(Node* hus, size_t k) //单链表实现约瑟夫环
{
Node* man, *next;
assert(hus); //环不为空
man = hus; //记录环的头
while (man->next != man) //当最后只剩一个节点时结束
{
int count = k; //记录步数
while (--count) //走k-1步
{
man = man->next;
}
next = man->next; //为了删除第k个节点,记录其下一个节点
man->data = next->data; //将下一节点的值赋给第k个节点
man->next = next->next; //使值已经改变的第k个节点指向下一节点的下一节点
free(next); //释放下一节点。即原1 2 3 4 5走3步时,变为1 2 4 4 5,再变为1 2 4 5
}
return man; //返回最后只剩一个节点的man(幸存者)
}
6.逆置/反转单链表(重中之重)
思路一:
将指针逆置,本来1->2->3->4,改为1<-2<-3<-4。
void ReverseList(Node** ppNode) //逆置反转
{
Node* n0, *n1, *n2 ;
if (*ppNode == NULL)
{
return;
}
n0 = NULL;
n1 = *ppNode;
n2 = n1->next;
while (n1) //n1为空时结束
{
//逆置
n1->next = n0;
//后移
n0 = n1;
n1 = n2;
if (n2 != NULL) //if(n1==NULL) { break; }
{
n2 = n2->next;
}
}
*ppNode = n0;
}
思路二:
利用逐个头插到另一个空节点的方法。
void ReverseList(Node** ppNode) //逆置反转
{
Node* newHead = NULL;
Node* cur = *ppNode;
while (cur != NULL)
{
Node* next = cur->next; //记录下一个节点
cur->next = newHead; //头插
newHead = cur; //cur变为头结点
cur = next;
}
*ppNode = newHead;
}
7.单链表排序(冒泡排序&快速排序)
冒泡排序:
void SortList(Node* pHead) //冒泡排序(不需要头,所以不传二级指针)
{
//此处不能用断言,只有一定不为空时才能用断言
if (pHead == NULL || pHead->next == NULL)
{
return;
}
Node* tail = NULL;
while (tail != pHead)
{
int exchange = 0; //标记变量,如果链表本身已经有序,一趟比较之后不用再做比较
Node* cur = pHead, *next = cur->next; //为什么这条语句不可以放在全部while外定义?
while (next != tail)
{
if (cur->data > next->data)
{
exchange = 1;
DataType t = cur->data;
cur->data = next->data;
next->data = t;
}
cur = cur->next;
next = next->next;
}
if (exchange == 0)
{
break;
}
tail = cur;
}
}
8.合并两个有序链表,合并后依然有序 (重中之重)
Node* MergeList(Node* list1, Node* list2) //两个有序链表合并后仍为有序链表
{
Node* list,*tail;
if (list1 == NULL)
{
return list2;
}
if (list2 == NULL)
{
return list1;
} //两者都为空时反正返回为空
if (list1->data < list2->data) //先确定list
{
list = list1;
list1 = list1->next;
}
else
{
list = list2;
list2 = list2->next;
}
tail = list;
while (list1&&list2)
{
if (list1->data < list2->data)
{
tail->next = list1;
list1 = list1->next;
}
else
{
tail->next = list2;
list2 = list2->next;
}
tail = tail->next; //因为此时新链表已经链上了元素,tail后有元素
}
if (list1) //如果全部比较后,list1还有元素,直接链到tail后
{
tail->next = list1;
}
if (list2) //如果全部比较后,list2还有元素,直接链到tail后
{
tail->next = list2;
}
return list; //list不能动,因为它标识了新链表的头
}
9.查找单链表的中间节点,要求只能遍历一次链表
利用快慢指针。
Node* FindMidNode(Node* pHead) //找单链表的中间节点
{
Node* slow = pHead, *fast = pHead;
while (fast && fast->next && fast->next->next) //预防fast为空,奇数时预防fast的next为空,偶数时保证输出前一个元素
{
slow = slow->next; //slow每次走一步,fast每次走两步,当fast到尾时,slow在中间
fast = fast->next->next;
}
return slow;
}
10.查找单链表的倒数第k个节点,要求只能遍历一次链表
利用快慢指针。先考虑不足K个节点时,再考虑相差k步和k-1步的差异,差k步在fast为空时结束,差k-1步在fast为尾时结束。
Node* FindKNode(Node* pHead,size_t k)
{
Node* slow = pHead, *fast = pHead;
while (--k) // --k走k-1步,k--走k步(上去就减去了1)
{
if (fast == NULL);
{
return NULL;
}
fast = fast->next;
}
while (fast->next) //快慢指针差k-1步时,fast到尾即可结束
{
slow = slow->next;
fast = fast->next;
}
return slow;
}