深度学习面试题汇总(一)
文章目录
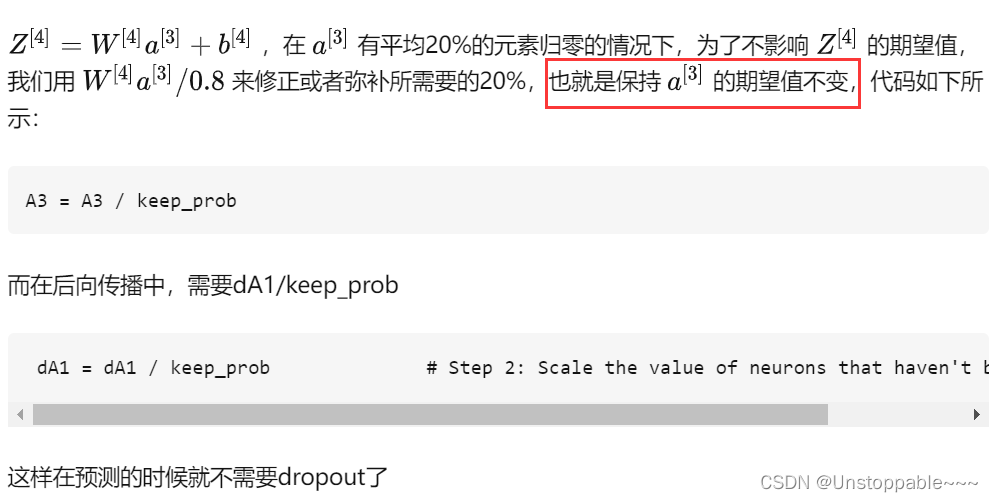
1.Dropout
1.1Dropout在训练的过程中会随机去掉神经元,那么在编码过程中是怎么处理的呢?

1.2dropout的训练过程需要做rescale,这个过程是什么样子的呢?
2.激活函数
2.1Relu
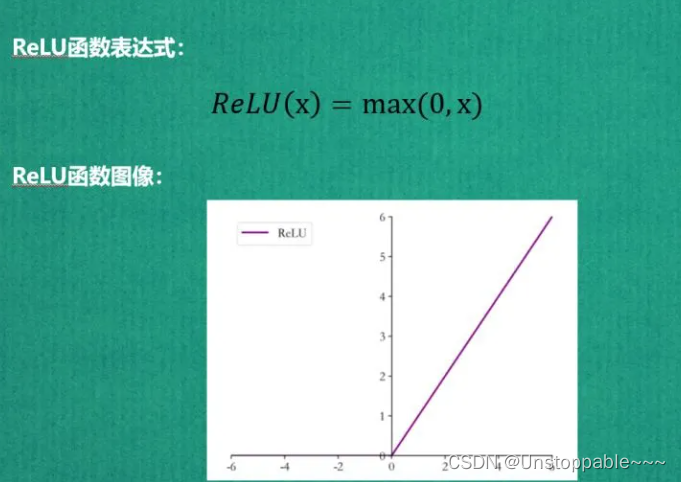
2.1.1Relu零点不可导问题

2.1.2Relu优缺点
优点包括:
- 解决了梯度消失、爆炸的问题
- 计算方便,计算速度快,求导方便
- 加速网络训练
缺点包括:
- 由于负数部分恒为0,会导致一些神经元无法激活
- 输出不是以0为中心
2.2Sigmoid
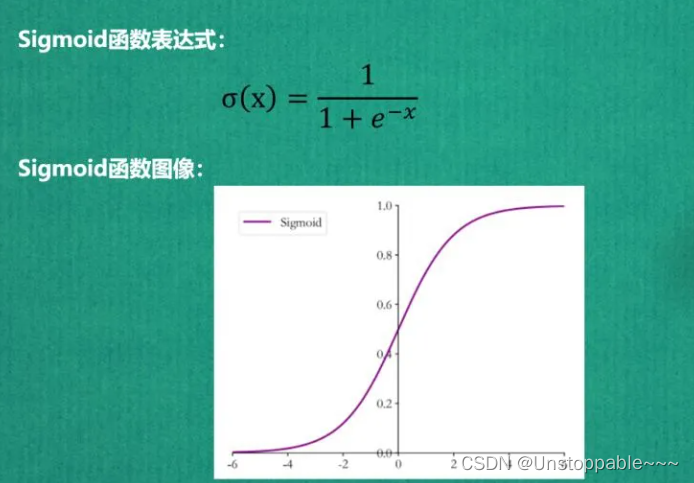
特点:
- Sigmoid函数优良的特性能够把X ∈ R的输出压缩到X ∈ (0, 1)区间。可以利用Sigmoid函数将输出转译为概率值的输出。
- 在LSTM中,当Sigmoid输出1的时候代表当前门控全部开放(允许全部记忆通过),当Sigmoid输出0的时候代表门控关闭(不允许任何记忆通过)。
缺点:
- 经过Sigmoid激活函数输出的均值为0.5,即输出为非0均值。反向传播时候更新方向要不往正向更新,要不往负向更新,会导致捆绑效果,使得收敛速度减慢。
- 梯度消失和梯度爆炸
3.如何处理神经网络中的过拟合问题?
4.梯度消失和梯度爆炸的问题是如何产生的?如何解决?
由于反向传播过程中,前面网络权重的偏导数的计算是逐渐从后往前累乘的,如果使用 、σ、tanh 激活函数的话,由于导数小于一,因此累乘会逐渐变小,导致梯度消失,前面的网络层权重更新变慢;如果权重本身比较大,累乘会导致前面网络的参数偏导数变大,产生数值上溢。
因为 sigmoid 导数最大为1/4,故只有当abs(w)>4时才可能出现梯度爆炸,因此最普遍发生的是梯度消失问题。
解决方法通常包括
- 使用ReLU等激活函数,梯度只会为0或者1,每层的网络都可以得到相同的更新速度
- 采用LSTM
- 进行梯度裁剪(clip), 如果梯度值大于某个阈值,我们就进行梯度裁剪,限制在一个范围内
- 使用正则化,这样会限制参数 w的大小,从而防止梯度爆炸
- 设计网络层数更少的网络进行模型训练
- batch normalization
精彩博客:https://kexue.fm/archives/7888
5.交叉熵损失与KL散度的区别?

6.什么是数据规范化(Normalization),我们为什么需要它?
规范化将越来越偏的分布拉回到标准化的分布,使得激活函数的输入值落在激活函数对输入比较敏感的区域,从而使梯度变大,加快学习收敛速度,避免梯度消失的问题。
- 第L层每个神经元的激活值进行Normalization操作,比如BatchNorm/ LayerNorm/ InstanceNorm/ GroupNorm等方法都属于这一类;
- 对神经网络中连接相邻隐层神经元之间的边上的权重进行规范化操作,比如Weight Norm就属于这一类。