线性回归以及使用梯度下降算法最小化代价函数
监督学习:
训练集——>学习算法——>得到一个函数h。自变量x——>函数h——>输出因变量y的值,h是x到y的函数映射
分类问题是预测离散的输出值,0/1离散输出问题
而回归一词指的是我们根据之前的数据预测出一个准确的输出值,线性回归中我们要解决的是一个最小化问题,我们要做的事是尽量减少假设的输出值与真实值之间差的平方(hθ(x) - y)^2,对每个样本数据求这个东西然后求和得到最终的平方误差代价函数(代价函数):
先了解下几种函数定义:
损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
目标函数(Object Function)定义为:最终需要优化的函数。等于经验风险+结构风险(也就是Cost Function + 正则化项)。
代价函数中的 i 表示样本索引,从1到m,m是样本容量,最小化代价函数时会求偏导,函数前面用1/2m可以消除平方项的2,对代价函数本身不产生影响(代价函数),我们需要的即是编写算法来找出最小化代价函数的θ0和θ1的值

这里简化算法来理解最小化代价函数,让函数只有一个参数θ1,hθ(x(i))变为θ1x(i),目标是将J(θ1)最小化,即最后一行的目标函数

任何一个θ1的取值(假设函数的瞬时斜率)对应着一个不同的假设函数,即对应着一条不同的拟合直线,可以算出一个不同的J(θ1)的取值,如右图θ1=1时完美拟合

梯度下降算法最小化函数J:

通过不停的一点点地改变θ0和θ1来试图通过这种改变使得J(θ0,θ1)变小,直到找到J的最小值(或许是局部最小值)

假设我们现在站在山上某一处,环视四周,找到一个下降最快的方向,并向那个方向迈一小步,然后再在新的位置找到新的下降最快的方向再迈一小步,以此类推,直到走到局部最低的点。
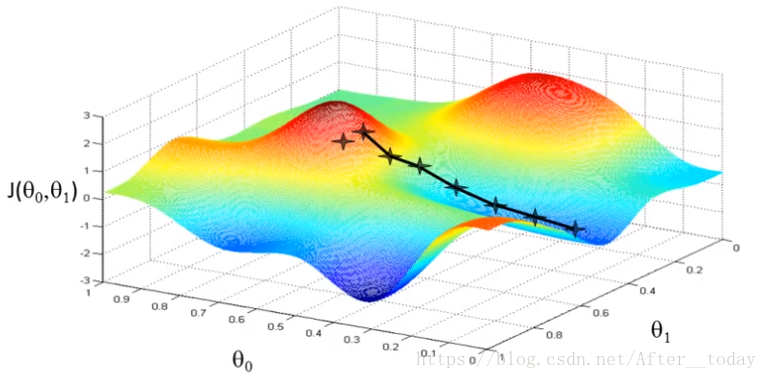
换个起始位置,重复刚才的操作,找到了一个新的局部最低点,这里就很直观的可以明白为什么说找的J值是局部最小值的意思。下面是梯度下降算法的定义:

注意的点:
1、:=是赋值运算符,意思是左边的值不管是什么,都取右边的值将其赋给左边(emmmm,课程中说的是=是判断为真的声明,:=是赋值,那和python里==是判断为真的声明,=是赋值应该是一个意思吧);
2、α控制我们下山迈多大的步伐(控制下降速率),术语称之为学习速率,以多大幅度更新θj,α过小会导致每一步很小,需要更多得收敛次数才能到最低点;α太大可能会越过最低点甚至无法收敛。;
3、for循环来同时更新J(θ0,θ1),使得temp0和temp1也同时更新,在梯度下降中真正实现同步更新。
4、公式中的导数为代价函数在当前位置上的切线得斜率,当选取的参数已经位于局部最低点,求导结果为0,那么算法将会什么都不做
线性回归算法
这里涉及到偏导数的计算(意识到高数学习的重要性),再次划重点:两者要同时更新
θ0的推导:
θ1的推导:
