感觉回到了统计学多元回归的课堂,融入了使用线代中的矩阵运算
在多元情况下梯度下降算法(右边):
下标 j 表示第 j 个参数,上标 (i) 表示第 j 个参数的第 i 条数据,本质上和上一节讲的一元下的梯度下降算法(左边)是一回事

优化梯度下降算法的效率
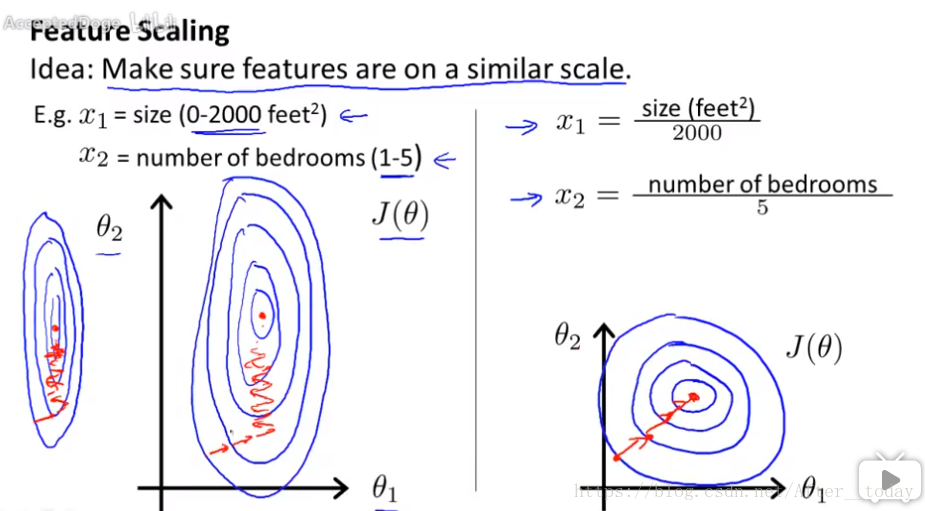
一、特征缩放
还是房价的例子:当有房屋面积和卧室数量两个参数时,x1的范围很大而x2的范围很小,反映到代价函数上导致很狭长的椭圆形状,梯度下降会花很长时间并有可能会来回波动,最终才能收敛到全局最小值,所以通过特征缩放,“消耗掉”这些值的范围(对两个参数都除以各自的范围),将特征的取值约束到近似在 [ -1, 1] ([ -3, 3] 或者 [ -1/3, 1/3] 这种都可以接受),这样的得到的代价函数会变得平滑,更容易下降
二、均值归一化
简单来说就是变量标准化(概率论与数理统计有讲),使得数据更为平滑,范围近似就好,不必苛求,目的与特征缩放一样,让梯度下降收敛所需要的循环次数更少

三、α的选择
在之前一元的时候也讲过这个问题,如果学习率α太大,J(θ) 可能会冲过最小值,甚至来回震荡,甚至最终无法收敛;而如果学习率太小的话会导致收敛速度过慢(右图横坐标我认为应该是θ),尝试不同的α的值观察效果,得到一个合适的学习率
