如下主要介绍4种:Sigmoid, Tanh, Relu, Leaky Relu
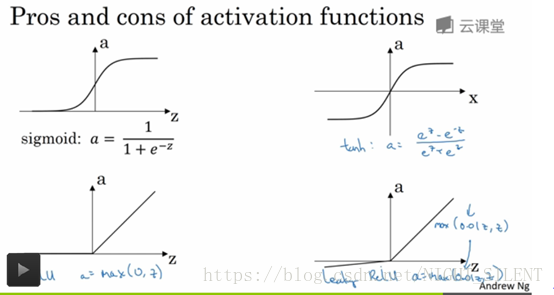



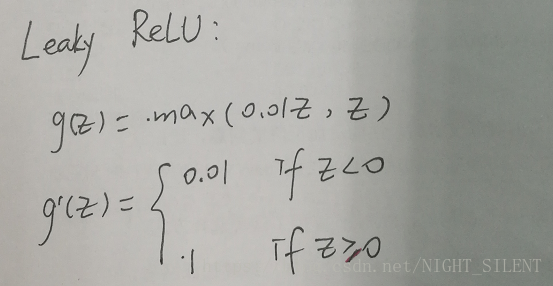
各种非线性激活函数的优缺点:
Sigmoid:
现在吴恩达几乎从来不用sigmoid激活函数了,但是吴恩达会用sigmoid的一个例外场合是进行二元分类时。
缺点:
1、Sigmoid容易饱和,并且当输入非常大或者非常小的时候,神经元的梯度就接近于0了,从图中可以看出梯度的趋势。这就使得我们在反向传播算法中反向传播接近于0的梯度,导致最终权重基本没什么更新,我们就无法递归地学习到输入数据了。另外,你需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradient kill掉,这会导致网络变的很难学习。容易饱和这个问题叫做 “梯度饱和” ,也可以叫 “梯度弥散” 。
2、Sigmoid 的输出不是0均值的,这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in
),那么在反向传播的过程中对w求梯度要么都为正,要么都为负(取决于整个表达式 f 的梯度)。这可能会在权重的梯度更新中引入不受欢迎的zig-zagging动态。导致有一种捆绑的效果,使得收敛缓慢。当然了,如果你是按batch去训练,那么每个batch可能得到不同的符号(正或负),那么相加一下这个问题还是可以缓解。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
Tanh:
tanh:有数据中心化的效果,让均值接近于0,而不是0.5,这实际让下一层的学习更方便点。tanh几乎在所有场合都更优越,一个例外是输出层,因为y如果真实值为0或1,那么我们希望y帽介于0和1之间,而不是-1和1之间,这时sigmoid更适合。
Tanh和sigmoid的一个共同缺点:当z很大或很小时,那么这个函数的斜率会很小,很接近于0,这样会拖慢梯度下降法。
Relu:
Relu:a = max(0,z),但是当z = 0时,导数是没有定义的,但如果编程实现,你得到的z刚好等于0.000000000000的概率很低,所以不必担心。
Relu已经变成激活函数的默认选择了,当你不知道因隐层到底该用哪个激活函数时,就可以用relu。虽然有人也会用tanh。Relu的一个缺点:当z为负时,导数等于0。但在实际中却没有什么问题。虽然对于z的一半范围来说,relu的斜率为0,但在实践中,有足够多的隐藏单元令z大于0,所以对于大多数训练样本来说还是很快的。
Leaky Relu:
Relu的另一个版本:leaky ReLu(a = 0.01*z,z),实际上比relu要好,但是实际中使用的频率却没有那么高。