三种激活函数以及它们的优缺点
导数:
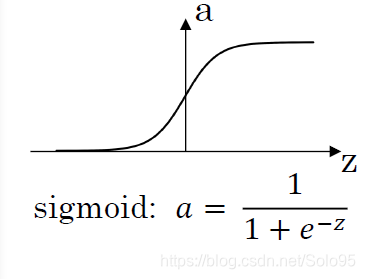
最基本的激活函数,logistics regression以及讲解深度神经网络的时候作为简单例子,但实际上很少使用。
原因如下:
当z非常大或者非常小的时候,a的斜率变得越来越接近0,这会使得梯度下降算法变得极为缓慢。
但 非常适合作为二元分类网络输出层的激活函数,因为在该应用场景下你需要 ,而不是 的
导数:
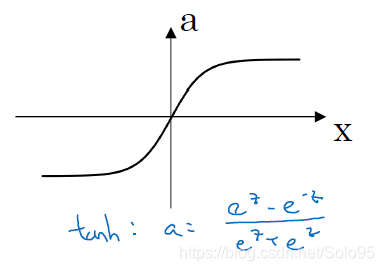
其实相当于把 平移到以原点为中心,然后再缩放到 的范围。
使用 作为激活函数在绝大多数情况下都比sigmoid要好得多,仅有上面提及的二元分类输出层为例外。
而且使用tan(h)能够中心化你的数据,中心化的含义是数据的均值接近0而不是像0.5这样的值。这会使得下一层的学习变得简单一点。
但是 和 一样,在当z非常大或者非常小的时候,a的斜率变得越来越接近0,使得深度下降算法变得极为缓慢。
ReLU(Rectified Linear Unit)
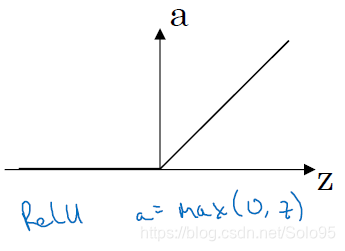
最最最常用的激活函数。
导数:
它的唯一缺点可能就是有一半的范围(图左),a都是0。但实际使用中,足够多的神经网络层数会使得a维持在 的范围内,所以该缺点影响不大。

另外因为斜率在 时恒等于1,摆脱了前两种激活函数使得学习速率下降的问题,可以始终维持比较快的学习速度。一般来说,ReLU都比其他激活函数学习得快一点。
这也是为什么CNN干脆把某些层命名为ReLU层,即线性整流层,博主会在CNN的博文里提及除了加快学习速度的其他原因。
leaky ReLU
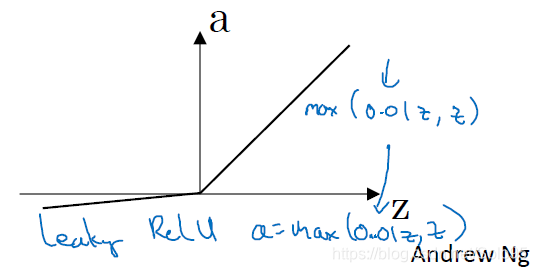
ReLU的一种变种,将ReLU中斜率为0的部分,变成了
,你可以调整0.01为其他值,看能否取得更好的效果。
导数:
一般来说。leaky ReLU能比ReLU取得更好的结果,但实际很少有人使用。
Summary
三种激活函数都有一定的使用场景,ReLU的流行只是在大部分的场景下都适用,具体要选择哪种激活函数,要根据你自己的实际应用来作决策。如果你不确定你要用什么,ReLU不会让你失望。
在使用ReLU时,ReLU和leaky ReLU任取一个即可,也可以都尝试一下,哪一个能取得最佳结果。