1.路径压缩
普通的并查集中我们仅仅是用一个函数找到了节点的根结点并用一个变量r记录下来返回,之后直接与另一个节点比较看是否是在同一个连通分量上,
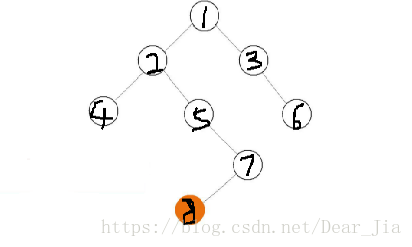
如图,这样的话查找的效率就很低,所以这个时候如果路径压缩的话就会明显降低节点的深度,这在后续查找根节点的过程中会大大提升效率,如下图:
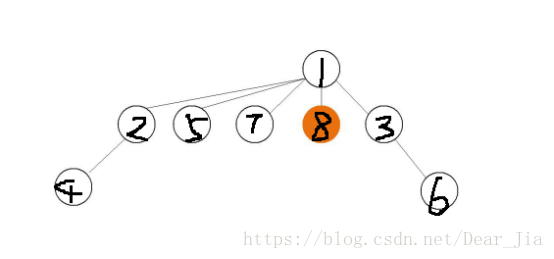
这样就把节点直接连接到根节点上,大大的减少了查找效率
先来看一下传统并查集的代码:
int find(int x){//寻找每个人的最终认识的人(根节点)
int r=x;
while(r!=parent[r])
r=parent[r];

return r;
}
}
可以看到,find函数的过程中其实只是改变了r变量的值,其实并没有改变parent数组(存储父结点)的值,然后如果每次都这么查找的话,时间效率是真的低,下面再看一下路径压缩后的代码
int find(int x)//寻找根节点
{
int k, j, r;
r = x;
while(r != parent[r]) //查找跟节点
r = parent[r]; //找到根节点,用 r 记录下
k = x;
while(k != r) //非递归路径压缩操作
{
j = parent[k]; //用 j 暂存 parent[k]的父节点
parent[k] = r; //parent[x]指向跟节点
k = j; //k 移到父节点
}
return r; //返回根节点的值
}
可以看到,在查找的时候改变了parent数组(存储父节点)的值,其实改变的过程中就将根节点变成了父结点,这样在每次查找一个点的跟节点的时候就不用再路过一遍父结点,很大程度上减少了路过节点的次数(提高了效率)
2. 按秩迭代
秩在这里就是树的深度,传统的合并就是不管三七二十一直接合并,没有考虑到树的深度问题,但是我们知道,树越平衡查找的效率越高,所以基于这个原理我们来合并节点
原则:左边树的秩比右边树的秩大我们让左边的作为根节点,如图
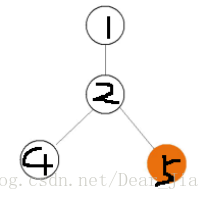
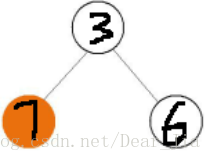
左边树的秩为3,右边数的秩为2,所以合并后为
还是先来看传统代码:
void cs(int x,int y){//将在同一个连通分量上的节点连接起来
int p,q;
p=find(x);
q=find(y);
if(p!=q){
parent[p]=q;
}
因为需要秩,所以需要一个数组来记录节点的秩(这也算是空间换时间了吧)
void union_set(int x, int y)//将两个节点合并到一起
{
x = find_set(x);
y = find_set(y);
if(rank[x] > rank[y])/*让 rank 比较高的作为父结点*/ parent[y] = x;
else
{
parent[x] = y;
if(rank[x] == rank[y])
rank[y]++;//因为两个相同高度的树连接后必有一个称谓子节点,所以树的深度就会加1(只需要加根节点的就可以)
}
}
注意rank数组的初始化
for(int i=0;i<=n;i++)
{
parent[i]=i;
rank[i]=0;
}