梯度下降法
梯度下降法是一种常用的一阶优化方法,是求解无约束优化问题最简单、最经典的方法之一。
梯度下降算法如下:
输入:目标函数,梯度函数
,计算精度
:
输出:的极小点
(1)取初始值,置为k=0
(2)计算
(3)计算梯度,当
时,停止迭代,令
,否则,令
,求
,使
(4) 令,计算
,当
或
时,停止迭代,令
(5)否则,令k=k+1,转(3)
当目标函数是凸函数时,梯度下降法的解释全局最优解,一般情况下,其解不保证是全局最优解,梯度下降法的收敛速度也未必是很快的。
基于梯度的搜索是使用最为广泛的参数寻优方法,但是会陷入局部极小。
扫描二维码关注公众号,回复:
2686616 查看本文章

批量梯度下降法(Batch Gradient Descent,简称BGD)
批量梯度下降法是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新。
在整个数据集上(求出罚函数 J(θ 并)对每个参数 θ 求目标函数 J(θ) 的偏导数:

优点:全局最优解,易于并行实现
缺点:训练过程慢,对于较大的内存无法容纳的数据集,该方法否无法被使用
随机梯度下降法(Stochastic Gradient Descent)
在每次更新参数时,随机选取一个样本,计算惩罚函数,然后求出相应的偏导数:

优点:训练速度快
缺点:SGD收敛过程中存在波动,会帮助跳出局部极小值,会让收敛到特定最小值的过程复杂化,因为该方法可能持续波动而不收敛,当慢慢降低学习率时,SGD和BGD表现出了相似的收敛过程。
小批量梯度下降法(Mini-Batch Gradient Descent)
更新每一参数时,使用一部分样本来更新,对n个样本构成的一批数据,计算惩罚函数并求导:
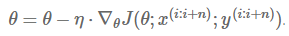
这种方法能够降低更新参数的方差,使得收敛过程更加稳定,能够利用最新的深度学习程序库中高度优化的矩阵运算器,能够高效地求出每小批数据的梯度。
梯度下降的优化算法:
- 动量法
- Nesterov 加速梯度法
- Adagrad 法
- Adadelta 法
- RMSprop 法
- Adam
对SGD进行平行计算或者分布式计算:
- Hogwild!
- Downpour SGD
- 容忍延迟的 SGD 算法
- TensorFlow
- 弹性平均梯度下降法(Elastic Averaging SGD)
优化SHD的其它手段:
- 重排法(Shuffling)和递进学习(Curriculum Learning)
- 批量标准化(Batch Normalization)
- 早停(Early Stopping)
- 梯度噪声(Gradient Noise)
参考:
- 《机器学习》
- 《统计学习方法》
- 深度解读最流行的优化算法:梯度下降
- 三种梯度下降的方式:批量梯度下降、小批量梯度下降、随机梯度下降