面试总结
jQuery中的$是什么意思及 $. 和 $().的区别
$就是jQuery的别称
而jQuery就是jQuery库提供的一个函数.(好像也不仅仅只是函数, 因为还有 $.ajax(options) 这样的使用,等同 jQuery.ajax(options))
这个函数的作用是根据 () 里的参数进行查找和选择html文档中的元素, 函数作用之一就是GetElementByID的代替,但()内不仅可以是ID,还可以是各类选择器
比如:
$(document)就是 选取整个文档对象
那是不是只可以用$来代替,不是。为了防止命名冲突,jQuery库提供了另外的机制来给jQuery函数起另外的别名。
下面看下在jquery中,用 $. 和 $().有什么区别,它们分别的含义是什么?
$就是jquery对象,$()就是jQuery(),在里面可以传参数,作用就是获取元素
在jQuery中,最频繁使用的符号“$”。$提供了各种各样丰富的功能,
1.包括作为选择器选择页面中的一个或是一类元素
2.作为功能函数的前缀
javascript没有提供类似trim()的功能,而引入jQuery后,便可以直接使用trim()函数,例如$.trim(sString);
以上代码相当于:jQuery.trim(sString);即trim()函数时jQuery对象的一个方法。
3.window.onload的完善
4.创建页面的DOM节点
如下例子
$(".div1") 表示获取类名为div1的元素,例如获取<div class="div1"></div>
$(".div1").onclick表示类名为div1的div点击事件
jquery中$.,例如$.post(),$.get(),$.ajax()等这些都是jquery这个对象的方法
"=="和equals方法究竟有什么区别?
1)==是用于比较两个对象的内存地址值(引用值)是否相等;equals()方法是用于比较两个对象的内容是否一致。
2)对于非字符串变量来说,==和equals方法的作用是相同的都是用来比较其对象在堆内存中的首地址,即用来比较两个引用变量是否指向同一个对象。
3)如果是基本类型比较,只能用==来比较,不能用equals。
4)对于基本类型的包装类型,比如Boolean,Character,Byte,Shot,Integer,Long,Float,Double等的引用变量,==是比较地址的,equals是比较内容的。
5)字符串的比较基本上都是使用equals方法
Ajax同步与异步区别
AJAX中根据async的值不同分为同步(async = false)和异步(async = true)两种执行方式;
普通B/S模式(同步)AJAX技术(异步)
同步:提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事
异步: 请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕
一.什么是同步请求:(false)
同步请求即是当前发出请求后,浏览器什么都不能做,必须得等到请求完成返回数据之后,才会执行后续的代码,相当于是排队,前一个人办理完自己的事务,下一个人才能接着办。也就是说,当JS代码加载到当前AJAX的时候会把页面里所有的代码停止加载,页面处于一个假死状态,当这个AJAX执行完毕后才会继续运行其他代码页面解除假死状态。
二.什么是异步请求:(true)
异步请求就当发出请求的同时,浏览器可以继续做任何事,Ajax发送请求并不会影响页面的加载与用户的操作,相当于是在两条线上,各走各的,互不影响。
一般默认值为true,异步。异步请求可以完全不影响用户的体验效果,无论请求的时间长或者短,用户都在专心的操作页面的其他内容,并不会有等待的感觉。
有人说:既然异步这么好,那全部都用异步好了,同步存在还有什么意义?
那么,同步适用于一些什么情况呢?
我们可以想一下,同步是一步一步来操作,等待请求返回的数据,再执行下一步,那么一定会有一些情况,只有这一步执行完,拿到数据,通过获取到这一步的数据来执行下一步的操作。这是异步没有办法实现的,因此同步的存在一定有他存在的道理。
多线程有几种实现方法?同步有几种实现方法?
多线程有两种实现方法,分别是继承Thread类与实现Runnable接口
同步的实现方面有两种,分别是synchronized,wait与notify
wait():使一个线程处于等待状态,并且释放所持有的对象的lock。
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
Allnotity():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。
HashMap和Hashtable的区别
hashtable是线程安全的,即hashtable的方法都提供了同步机制;
hashmap不是线程安全的,即不提供同步机制 ;
hashtable不允许插入空值,hashmap允许!
HashMap是非线程安全的(非同步的)。那么怎么才能让HashMap变成线程安全的呢?
我认为主要可以通过以下三种方法来实现:
1.替换成Hashtable,Hashtable通过对整个表上锁实现线程安全,因此效率比较低
2.使用Collections类的synchronizedMap方法包装一下。方法如下:
3.使用ConcurrentHashMap,它使用分段锁来保证线程安全
//Hashtable
Map<String, String> hashtable = new Hashtable<>();
//synchronizedMap
Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
//ConcurrentHashMap
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
通过前两种方式获得的线程安全的HashMap在读写数据的时候会对整个容器上锁,而ConcurrentHashMap并不需要对整个容器上锁,它只需要锁住要修改的部分就行了
List、Map、Set三个接口,存取元素时,各有什么特点?
list集合
有序 不唯一(可重复)
子类 ArrayList LinkedList 最常用 ArrayList
ArrayList 底层就是数组
List集合在collection接口基础上增强很多功能
ArrayList 与 LinkedList 区别:
实现原理不同 ArrayList 数组 LinkedList 链表
ArrayList 查询快 增删改慢
LinkedList 查询慢 增删改快
Set集合
无序 唯一(不可重复)
首先,List与Set具有相似性,它们都是单列元素的集合,所以,它们有一个功共同的父接口,叫Collection。Set里面不允许有重复的元素,所谓重复,即不能有两个相等(注意,不是仅仅是相同)的对象 ,
List表示有先后顺序的集合, 。
Map与List和Set不同,它是双列的集合,其中有put方法,定义如下:put(obj key,obj value),每次存储时,要存储一对key/value,不能存储重复的key,这个重复的规则也是按equals比较相等。取则可以根据key获得相应的value
List 以特定次序来持有元素,可有重复元素。Set 无法拥有重复元素,内部排序。Map 保存key-value值,value可多值。
HashSet按照hashcode值的某种运算方式进行存储,而不是直接按hashCode值的大小进行存储
遍历map的4种方式:
普遍使用 二次取值
for(String key : map.keySet()){
System.out.println("key : " + key + "\t value : "+ map.get(key));
}
通过Map.entrySet 和Iterator 遍历key 和value
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String, String> entry = it.next();
System.out.println("key : " + entry.getKey() + "\t value : "+ entry.getValue());
}
推荐使用 尤其容量大时
for(Map.Entry<String, String> entry : map.entrySet()){
System.out.println("key : " + entry.getKey() + "\t value : "+ entry.getValue());
}
通过map.value 遍历value 但不能遍历key
for(String str : map.values()){System.out.println(str);}
Collections 与 collection的区别:
Collections 是容器的操作类 类似于 Arrays
Collection 是接口 定义规范方法的
去掉一个Vector、ArrayList集合中重复的元素
ArrayList list=new ArrayList();
String a="aaa";
list.add(a);
list.remove(a);//根据对象删除
- 按下标删除 如:
list.remove(0),
list.remove(list.size() -1);
2.按元素删除 如:
list.remove(list.get(0)) 删除第一个元素
list.remove(list.get(list.size()-1)) 删除最后一个元素
或者下面方法把Vector 换成ArrayList即可
Vector newVector = new Vector();
For (int i=0;i<vector.size();i++)
{
Object obj = vector.get(i);
if(!newVector.contains(obj);
newVector.add(obj);
}
还有一种简单的方式,HashSet set = new HashSet(vector);
递归算法
public class DiguiHe{
public static void main(String[] args) {
System.out.println("递归1-100和:"+dghe(5));
System.out.println("递归1-100和:"+fdghe(5));
}
/**
* 递归1-100和
*/
private static int dghe(int i) {
/**
* 这里以5为例:
* 5+dghe(4)=5+4+dghe(3)=5+4+3+dghe(2)+5+4+3+2+dghe(1)=5+4+3+2+1
* 当dghe(1)走 return 1;程序结束了
*/
if(i == 1){
return 1;
}else{
return i+dghe(i-1);
}
}
/**
* 非递归1-100和
*/
private static int fdghe(int i) {
int sum = 0;
int j = 1;
while(j<=i){
sum+=j;
j++;
}
return sum;
}
}
递归10的阶乘
public class DiguiChen{
public static void main(String[] args) {
System.out.println("递归阶乘:"+dgjc(10));
System.out.println("非递归阶乘:"+fdgjc(10));
}
/**
* 递归阶乘
*/
private static int dgjc(int i) {
//这里举例5的阶乘,10的阶乘同理:
//5*dgjc(4)=5*4*dgjc(3)=5*4*3*dgjc(2)=5*4*3*2*dgjc(1)=5*4*3*2*1=120
if(i == 1){
return 1;
}else{
return i*dgjc(i-1);
}
}
/**
* 非递归阶乘
*/
private static int fdgjc(int i) {
int sum = 1;
while(i>0){
sum*=i;
i--;
}
return sum;
}
说出一些数据库优化方面的经验?
使用索引
少用SELECT*
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
不要把SQL语句写得太长,太过冗余
使用NOT NULL
where子句优化避免在 where 子句中使用 or 来连接
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
应尽量避免在 where 子句中对字段进行 null 值判断
Mysql分页查询关键字: limit
Oracle分页查询关键字:runnum
获得两个日期之间的天数
首先把获取的字符串日期转换成Date类型(从前台页面获取的是字符串类型的日期 a,b):
Date a1 = new SimpleDateFormat("yyyy-MM-dd").parse(a);
Date b1 = new SimpleDateFormat("yyyy-MM-dd").parse(b);
//获取相减后天数
long day = (a1.getTime()-b1.getTime())/(24*60*60*1000);
getTime 方法返回一个整数值,这个整数代表了从 1970 年 1 月 1 日开始计算到 Date 对象中的时间之间的毫秒数是long类型,如果要显示日期,需要进行格式化,比如使用 SimpleDateFormat
SpringMVC常用注解整理
@Controller 用于标记在一个类上,使用它标记的类就是一个SpringMVC Controller 对象
@RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
package com.cqvie.handler;
import org.springframework.stereotype.Controller;
@Controller
public class HelloWorld {
@RequestMapping("/helloworld")
public String sayHello() {
System.out.println("Hello World!");
return "success";
}
}
@RequestParam:用于获取传入参数的值
@RequestMapping("/requestParams1.do")
public String requestParams1(@RequestParam(required = false) String name){
System.out.println("name = "+name);
return "index";
}
@Resource和@Autowired都是做bean的注入时使用
@Autowired顾名思义,就是自动装配,其作用是为了消除代码Java代码里面的getter/setter与bean属性中的property。当Spring发现@Autowired注解时,将自动在代码上下文中找到和其匹配(默认是类型匹配)的Bean,并自动注入到相应的地方去。当Spring找不到bean时会抛出异常,将@Autowired注解的required属性设置为false 不会抛出异常,会显示null
当有多个bean对应时,Spring因为不能判定应该使用哪个bean同样会抛出异常,此时使用@Qualifier("class-name")注解,即可指定bean
public class HelloWorld{
@Autowired
@Qualifier("userDao")
private UserDao userDao;
}
public class HelloWorld{
// 下面两种@Resource只要使用一种即可
@Resource(name="userDao")
private UserDao userDao; // 用于字段上
@Resource(name="userDao")
public void setUserDao(UserDao userDao) { // 用于属性的setter方法上
this.userDao = userDao;
}
}
@responseBody注解的作用是将controller的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML数据。
在使用@RequestMapping后,返回值通常解析为跳转路径。加上@responsebody后,返回结果直接写入HTTP response body中,不会被解析为跳转路径。比如异步请求,希望响应的结果是json数据,那么加上@responsebody后,就会直接返回json数据。
@ModelAttribute:用于把参数保存到model中,可以注解方法或参数,注解在方法上的时候,该方法将在处理器方法执行之前执行,然后把返回的对象存放在 session(前提时要有@SessionAttributes注解) 或模型属性中
@SessionAttributes默认情况下Spring MVC将模型中的数据存储到request域中。当一个请求结束后,数据就失效了。如果要跨页面使用。那么需要使用到session。而@SessionAttributes注解就可以使得模型中的数据存储一份到session域中。配合@ModelAttribute("user")使用的时候,会将对应的名称的model值存到session中
@Controller
@RequestMapping("/test")
@SessionAttributes(value = {"user","test1"})
public class LoginController{
@ModelAttribute("user")
public UserEntity getUser(){
UserEntity userEntityr = new UserEntity();
userEntityr.setUsername("asdf");
return userEntityr;
}
@RequestMapping("/modelTest.do")
public String getUsers(@ModelAttribute("user") UserEntity user ,HttpSession session){
System.out.println(user.getUsername());
System.out.println(session.getAttribute("user"));
return "/index";
}
}
@Service@Override
linux下实时查看tomcat运行日志和基本命令
启动Tomcat
./startup.sh
Tomcat关闭命令
./shutdown.sh
查看Tomcat是否以关闭
ps -ef|grep java
杀死Tomcat进程
kill -9 7010
查看tomcat日志
先切换到:cd usr/local/tomcat7/logs
tail -f catalina.out
按ctrl+c即可结束查看
cp 复制 mv 剪切、重命名 rm 删除
ls 查看目录内容 ll查看详细信息 cd .. 切换到上级目录
mkdir 创建目录 tab 自动补全 cat 查看文件内容
ping命令 clear 清除 kill 杀死进程 ifconfig 查看或配置网卡信息
Linux服务器内存使用情况free -m /top 以k为单位显示出来的
cat命令主要用来查看文件内容,创建文件,文件合并,追加文件内容等功能 例如:cat aa.txt
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
ps与grep常用组合用法,查找特定进程
命令:ps -ef | grep yushan
more 查看文件内容,分页显示,按空格翻页
more和less一般用于显示文件内容超过一屏的内容,并且提供翻页的功能。more比cat强大,提供分页显示的功能,less比more更强大,提供翻页,跳转,查找等命令。而且more和less都支持:用空格显示下一页,按键b显示上一页
Java中创建对象的五种方式
创建对象的方法:使用New关键字、使用Class类的newInstance方法、使用Constructor类的newInstance方法、使用Clone方法、使用反序列化。
1.使用new关键字:这是我们最常见的也是最简单的创建对象的方式,通过这种方式我们还可以调用任意的够赞函数(无参的和有参的)。比如:Student student = new Student();
2.使用Class类的newInstance方法:我们也可以使用Class类的newInstance方法创建对象,这个newInstance方法调用无参的构造器创建对象,
如:Student student2 = (Student)Class.forName("根路径.Student").newInstance();
或者:Student stu = Student.class.newInstance();
3.使用Constructor类的newInstance方法:本方法和Class类的newInstance方法很像,java.lang.relect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数的和私有的构造函数。
如:Constructor<Student> constructor = Student.class.getInstance(); Student stu = constructor.newInstance();
这两种newInstance的方法就是大家所说的反射,事实上Class的newInstance方法内部调用Constructor的newInstance方法。这也是众多框架Spring、Hibernate、Struts等使用后者的原因。
4.使用Clone的方法:无论何时我们调用一个对象的clone方法,JVM就会创建一个新的对象,将前面的对象的内容全部拷贝进去,用clone方法创建对象并不会调用任何构造函数。要使用clone方法,我们必须先实现Cloneable接口并实现其定义的clone方法。
如:Student stu2 = <Student>stu.clone();这也是原型模式的应用。
5.使用反序列化:当我们序列化和反序列化一个对象,JVM会给我们创建一个单独的对象,在反序列化时,JVM创建对象并不会调用任何构造函数。为了反序列化一个对象,我们需要让我们的类实现Serializable接口。
如:ObjectInputStream in = new ObjectInputStream (new FileInputStream("data.obj")); Student stu3 = (Student)in.readObject();
redis面试总结
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。
Redis支持的数据类型
Redis通过Key-Value的单值不同类型来区分, 以下是支持的类型:
Strings Lists Sets 求交集、并集 Sorted Set hashes
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet
为什么redis需要把所有数据放到内存中?
Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。
如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
ehcache与redis区别
ehcache直接在jvm虚拟机中缓存,速度快,效率高;但是缓存共享麻烦,集群分布式应用不方便。
redis是通过socket访问到缓存服务,效率比ecache低,比数据库要快很多,处理集群和分布式缓存方便,有成熟的方案。
如果是单个应用或者对缓存访问要求很高的应用,用ehcache。
如果是大型系统,存在缓存共享、分布式部署、缓存内容很大的,建议用redis。
补充下:ehcache也有缓存共享方案,不过是通过RMI或者Jgroup多播方式进行广播缓存通知更新,缓存共享复杂,维护不方便;简单的共享可以,但是涉及到缓存恢复,大数据缓存,则不合适。
使用Redis有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
JavaScript中定时器使用
setTimeout()
setTimeout函数用来指定某个函数或某段代码,在多少毫秒之后执行。它返回一个整数,表示定时器的编号,以后可以用来取消这个定时器。
setInterval()
setInterval函数的用法与setTimeout完全一致,区别仅仅在于setInterval指定某个任务每隔一段时间就执行一次,也就是无限次的定时执行。
// 执行在面的代码块会输出什么?
setTimeout(function () {
console.log('timeout');
}, 1000);
setInterval(function () {
console.log('interval')
}, 1000);
// 输出一次 timeout,每隔1S输出一次 interval
关闭定时器的方法:clearInterval(),clearTimeout
setTimeout和setInterval函数,都返回一个表示计数器编号的整数值,将该整数传入clearTimeout和clearInterval函数,就可以取消对应的定时器。
var id1 = setTimeout(f,1000);
var id2 = setInterval(f,1000);
clearTimeout(id1);
clearInterval(id2);
Spring框架IOC和AOP的实现原理
IOC: Inversion of Control(控制反转)是指容器控制程序对象之间的关系,而不是传统实现中,由程序代码直接操控。控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。
DI: Dependency Injection,即“依赖注入”。它并不是一种技术实现,而是一种设计思想。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,即由容器动态地将某种依赖关系注入到组件之中。
依赖注入的思想是通过反射机制实现的,在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。
优点
第一,资源集中管理,实现资源的可配置和易管理,降低对象关系维护的复杂度。
第二,降低了使用资源双方的依赖程度,也就是我们说的耦合度。
举例:某一天,你生病了,但是你不清楚自己到底得了什么病,你只知道自己头疼,咳嗽,全身无力。这个时候你决定去药店买药,药店有很多种药,仅仅是治疗头疼就有好几十种,还有西药中药等区别。然后你自己看了看说明书,选择了一盒你自己觉得最能治疗自己病症的药,付钱吃药,期待可以早点好起来。
但是这个过程,对于一个病人来说,太辛苦了。头疼,咳嗽,全身无力,还要一个个的看药品说明书,一个个的比较哪个药比较好,简直是太累了。这个时候,你决定直接去医院看医生。
医生给你做了检查,知道你的病症是什么,有什么原因引起的;同时医生非常了解有哪些药能治疗你的病痛,并且能根据你的自身情况进行筛选。只需要短短的十几分钟,你就能拿到对症下药的药品,即省时又省力。
在上面这个例子中,IOC起到的就是医生的作用,它收集你的需求要求,并且对症下药,直接把药开给你。你就是对象,药品就是你所需要的外部资源。通过医生,你不用再去找药品,而是通过医生把药品开给你。这就是整个IOC的精髓所在。
AOP(Aspect Oriented Programming)
AOP面向方面编程基于IoC,是对OOP的有益补充;
AOP利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了 多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的 逻辑或责任封装起来,比如日志记录,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
使用“横切”技术,AOP把软件系统分为两个部分:核心关注点(业务逻辑)和横切关注点(通用逻辑,即方面)。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的特点是,其经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理,debug管理,性能检测等。AOP 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
2. 实现方式
实现AOP的技术,主要分为两大类:
一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;
二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
3. 优点
①.横切关注点的代码都集中于一块,不再是分散在各个业务组件中,不会出现大量重复代码;
②.核心模块只关注核心功能的代码,与通用模块分离,模块间藕合度降低。
Java运行时内存分配
线程独有区域:
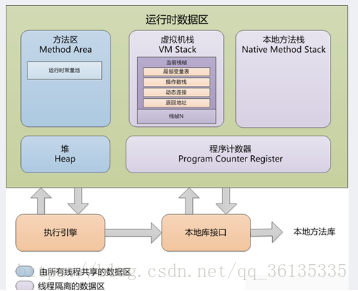
程序计数器:
是JVM分配的较小的一块内存空间,它可以看作是当前线程所执行的字节码的行号指示器。
字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
虚拟机栈:
描述的是java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接方法出口等信息。
栈帧也叫过程活动记录,是编译器用来实现过程/函数调用的一种数据结构。
线程启动——线程中方法按使用顺序入栈——方法入栈时创建栈帧
本地方法栈:
它与虚拟机栈发挥的作用非常相似,区别只在于,虚拟机栈为虚拟机执行java方法,而本地方法栈则为用到的本地方法服务。
所有线程共享区域:
堆:
此内存区域的唯一目的就是存放对象实例,所有的对象实例以及数组都要在堆上分配内存。
堆是垃圾收集器管理的主要区域。
方法区:
是各个线程共享的内存区域,它用来存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
Java 堆和栈的区别
概述
在Java中,内存分为两种,一种是栈内存,另一种就是堆内存。
2、堆内存
1.什么是堆内存?
堆内存是是Java内存中的一种,它的作用是用于存储Java中的对象和数组,当我们new一个对象或者创建一个数组的时候,就会在堆内存中开辟一段空间给它,用于存放。
2.堆内存的特点是什么?
第一点:堆其实可以类似的看做是管道,或者说是平时去排队买票的的情况差不多,所以堆内存的特点就是:先进先出,后进后出,也就是你先排队,好,你先买票。
第二点:堆可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,但缺点是,由于要在运行时动态分配内存,存取速度较慢。
3.new对象在堆中如何分配?
由Java虚拟机的自动垃圾回收器来管理
3、栈内存
1.什么是栈内存
栈内存是Java的另一种内存,主要是用来执行程序用的,比如:基本类型的变量和对象的引用变量
2.栈内存的特点
第一点:栈内存就好像一个矿泉水瓶,像里面放入东西,那么先放入的沉入底部,所以它的特点是:先进后出,后进先出
第二点:存取速度比堆要快,仅次于寄存器,栈数据可以共享,但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性
3.栈内存分配机制
栈内存可以称为一级缓存,由垃圾回收器自动回收
4、栈和堆的区别
JVM是基于堆栈的虚拟机.JVM为每个新创建的线程都分配一个堆栈.也就是说,对于一个Java程序来说,它的运行就是通过对堆栈的操作来完成的。堆栈以帧为单位保存线程的状态。JVM对堆栈只进行两种操作:以帧为单位的压栈和出栈操作。
差异
1.堆内存用来存放由new创建的对象和数组。
2.栈内存用来存放方法或者局部变量等
3.堆是先进先出,后进后出
4.栈是后进先出,先进后出
相同
1.都是属于Java内存的一种
2.系统都会自动去回收它,但是对于堆内存一般开发人员会自动回收它
数据库事务四大特性(ACID)
Spring事务管理基于底层数据库本身的事务处理机制。数据库事务的基础,是掌握Spring事务管理的基础。

事务具备ACID四种特性,ACID是Atomic(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性)的英文缩写。
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
数据库在不同的隔离性级别下并发访问可能会出现以下几种问题:
脏读(Dirty Read)
当一个事务读取另一个事务尚未提交的修改时,产生脏读
不可重复读(Unrepeatable Read)
一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了
幻读(Phantom Read)
一个事务先后读取一个范围的记录,但两次读取的数据不同,我们称之为幻象读(两次执行同一条 select 语句会出现不同的结果,第二次读会增加一数据行,并没有说这两次执行是在同一个事务中)
现在来看看MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化)就是序列化:可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
记住:设置数据库的隔离级别一定要是在开启事务之前!
如果是使用JDBC对数据库的事务设置隔离级别的话,也应该是在调用Connection对象的setAutoCommit(false)方法之前。

css样式优先级问题
通用选择器(*) < 元素(类型)选择器 < class类选择器 < 属性选择器 < 伪类 < ID 选择器 < style内联样式
*{width:100px}通用选择器(*)
.img{width:400px;}类class选择器
img[alt="img"] {width:300px}伪类选择器
img:hover{width:350px}属性选择器
img{width:450px}元素(类型)选择器
#img{width:250px;}id选择器
MySQL与Oracle的区别
1. Oracle是大型数据库而Mysql是中小型数据库,Oracle市场占有率达40%,Mysql只有20%左右,同时Mysql是开源的而Oracle价格非常高。
2. Oracle支持大并发,大访问量,是OLTP最好的工具。
3. 安装所用的空间差别也是很大的,Mysql安装完后才152M而Oracle有3G左右,且使用的时候Oracle占用特别大的内存空间和其他机器性能。
4.Oracle也Mysql操作上的一些区别
①主键 Mysql一般使用自动增长类型,在创建表时只要指定表的主键为auto increment,插入记录时,不需要再指定该记录的主键值,Mysql将自动增长;Oracle没有自动增长类型,主键一般使用的序列,插入记录时将序列号的下一个值付给该字段即可;只是ORM框架是只要是native主键生成策略即可。
②单引号的处理 MYSQL里可以用双引号包起字符串,ORACLE里只可以用单引号包起字符串。在插入和修改字符串前必须做单引号的替换:把所有出现的一个单引号替换成两个单引号。
③翻页的SQL语句的处理 MYSQL处理翻页的SQL语句比较简单,用LIMIT 开始位置, 记录个数;ORACLE处理翻页的SQL语句就比较繁琐了。每个结果集只有一个ROWNUM字段标明它的位置, 并且只能用ROWNUM<100, 不能用ROWNUM>80
④ 长字符串的处理 长字符串的处理ORACLE也有它特殊的地方。INSERT和UPDATE时最大可操作的字符串长度小于等于4000个单字节, 如果要插入更长的字符串, 请考虑字段用CLOB类型,方法借用ORACLE里自带的DBMS_LOB程序包。插入修改记录前一定要做进行非空和长度判断,不能为空的字段值和超出长度字段值都应该提出警告,返回上次操作。
⑤空字符的处理 MYSQL的非空字段也有空的内容,ORACLE里定义了非空字段就不容许有空的内容。按MYSQL的NOT NULL来定义ORACLE表结构, 导数据的时候会产生错误。因此导数据时要对空字符进行判断,如果为NULL或空字符,需要把它改成一个空格的字符串。
⑥字符串的模糊比较 MYSQL里用 字段名 like '%字符串%',ORACLE里也可以用 字段名 like '%字符串%' 但这种方法不能使用索引, 速度不快。
⑦Oracle实现了ANSII SQL中大部分功能,如,事务的隔离级别、传播特性等而Mysql在这方面还是比较的弱