学了这么久数据库,考考你,DDL和DML有啥区别呢?
DDL 数据定义语言
当执行DDL语句时,在每一条语句前后,oracle都将提交当前的事务。
如果用户使用insert命令将记录插入到数据库后,执行了一条DDL语句(如create table),此时来自insert命令的数据将被提交到数据库。
当DDL语句执行完成时,DDL语句会被自动提交,不能回滚。
create table 创建表
alter table 修改表
drop table 删除表
truncate table 删除表中所有行
create index 创建索引
drop index 删除索引
DML数据操作语言
当执行DML命令如果没有提交,将不会被其他会话看到。
除非在DML命令之后执行了DDL命令或DCL命令,或用户退出会话,或终止实例,此时系统会自动发出commit命令,使未提交的DML命令提交。
insert 将记录插入到数据库
update 修改数据库的记录
delete 删除数据库的记录
如何在Maven项目中使用Oracle数据库
在本地安装依赖包
mvn install :install-file -Dfile=ojdbc6.jar 所在的绝对路径 -Dpackaging=jar -DgroupId=com.oracle -DartifactId=ojdbc6 -Dversion=Oracle数据库版本
其中 ojdbc6.jar 的绝对路径是可以在安装的 Oracle 目录下找到的,我的是在D:\oracle\app\oracle\product\11.2.0\server\jdbc\lib\ojdbc6.jar;数据库版本可以通过执行查询语句获得select * from v$version;
在Maven项目中添加依赖
`<dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>11.2.0.2.0</version> </dependency>`
基本配置
jdbc.oracle.fs.url=jdbc:oracle:thin:@localhost:1521:XE
jdbc.oracle.fs.username=gene
jdbc.oracle.fs.password=xxx
语句编写实例
public static final String sqlAdd = "INSERT INTO FILE_ELE(\"id\",\"size\",\"create_time\",\"existed\") VALUES (?,?,?,?)";
public static final String sqlQueryAll = "select * from file_ele";
public static final String sqlGet = "select * from file_ele where \"id\"=?";
public static final String sqlDel = "update file_ele set \"existed\"=0 where \"id\"=?";使用 Navicat 连接 Oracle数据库
在 Oracle 配置文件中找到服务名等需要的信息
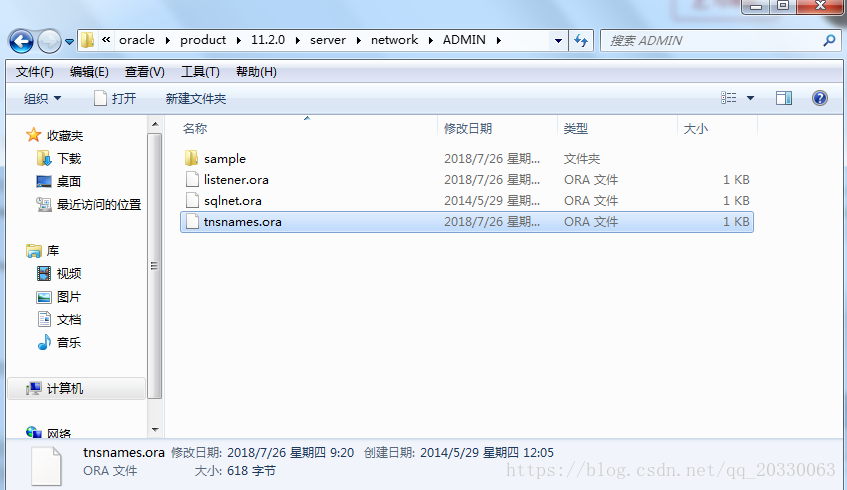
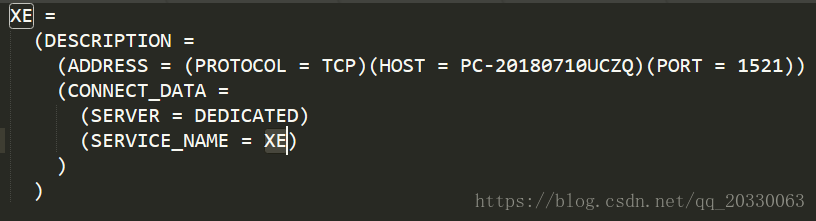
在Navicat中甜如需要的信息
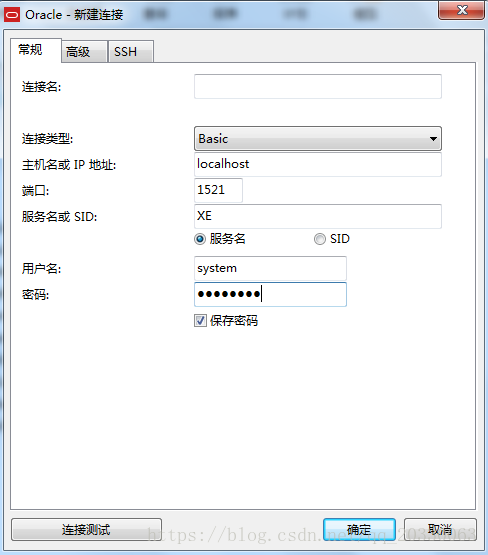
Oracle安装
访问官网、下载windows 或者 Linux 版本、解压缩、安装程序
数据类型(建议使用通过加粗表示)
字符型:固定长度(CHAR(n<=2000), NCHAR(n<=1000)常用来存汉语)、可变长度(VARCHAR2(n<=4000),NVARCHAR2(n<=2000))。
数值型:NUMBER(p,s),其中p:有效数字,s:小数点后的位数;FLOAT(n)表示1~126位的二进制数字。
日期型:Date表示范围公元前4712年1月1日到公元9999年12月31日,可精确到秒;TIMESTAMP则可以更精确到小数秒。
其他类型(存放大对象):BLOB存放二进制数据;CLOB存放字符串数据,可存储的大小均为4GB。
数据库、表备份
数据导出
扫描二维码关注公众号,回复: 2658280 查看本文章
1、将数据库TEST完全导出,用户名system,密码manager,导出到D:\tmp.dmp
exp system/manager@TEST file=d:\tmp.dmp full=y
2、将数据库TEST中system用户与sys用户的表导出
exp system/manager@TEST file=d:\tmp.dmp owner(system,sys)
3、将TEST数据库中的表table1、table2导出
exp system/manager@TEST file=d:\tmp.dmp tables(table1,table2)
4、将数据库中的表table1中字段field以“00”打头的数据导出
exp system/manager@TEST file=d:\tmp.dmp tables(table1)query=\"where field like '00%'\"数据导入
1、将D:\tmp.dmp中的数据导入TEST数据库
imp system/manager@TEST file=d:\tmp.dmp
2、将D:\tmp.dmp中的table1导入
imp system/manager@TEST file=d:\tmp.dmp tables=(table1)权限控制
创建用户user
create user 用户名 identified by 密码
赋予权限
grant create user,drop user, alter user, cerate any view, drop any view, exp_full_database, imp_full_database, dba, connect, resource, create session to 用户名管理表
创建表:注意同一个用户下表名唯一。查看表结构语句:desc table_name。
CREATE TABLE table_name
(
column_name datatype, …
);CREATE TABLE user_info
(
id number(6,0),
username varchar2(20),
password varchar2(20),
email varchar2(20),
regdate date default sysdate
);修改表结构
添加字段
ALTER TABLE table_name ADD column_name datatype;更改字段数据类型
ALTER TABLE table_name MODIFY column_name datatype;删除字段
ALTER TABLE table_name DROP COLUMN column_name;修改字段名
ALTER TABLE table_name RENAME COLUMN column_name TO new_column_name;修改表名
RENAME table_name TO new_table_name;删除表
清空数据保留表结构
TRUNCATE TABLE table_name;清空数据删除表结构
DROP TABLE table_name;单表增删改查
增(向表中指定字段添加值)
INSERT INTO table_name (column1, column2,…) VALUES (value1, value2,…);
增(向表中所有字段添加值)
INSERT INTO table_name VALUES (value1, value2,…);复制表数据(在创建表时复制 && 复制所有字段)
CREATE TABLE table_new AS SELECT * FROM table_old;
复制表数据(在创建表时复制 && 复制指定字段)
CREATE TABLE table_new AS SELECT column1,… FROM table_old;
复制表数据(在添加数据时复制)
INSERT INTO table_new
(column1,…)
SELECT column1,…|*FROM table_old; 修改数据(有条件更新)
UPDATE table_name
SET column1=value1, …
[WHERE conditions];
修改数据(无条件更新)
UPDATE table_name
SET column1=value1, …;删除表数据
DELETE FROM table_name
[WHERE CONDITIONS];高级查询
- 分组查询
分组函数:作用于一组数据,并对一组数据返回一个值
SELECT column,group_condition
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column]
求出员工的平均工资和工资总额
select avg(sal),sum(sal) from emp;
求出员工工资的最大值和最小值
select max(sal),min(sal) from emp;
求出员工的总人数(*代表所有列)
select count(*) from emp;
求出部门数(使用关键字DISTINCT去重)
select count(distinct depno) from emp;
WM_CONCAT行转列
select deptno,wm_concat(ename) from emp group by depno;
分组函数自动过滤空值,NVL函数使得分组函数无法忽略空值
NVL函数的用意:当第一个参数为空时,返回第二个参数
select count(*),count(nvl(comm,0)) from emp;求每个部门的平均工资,要求显示:部门号,部门的平均工资
在select列表中所有没有包含在组函数中的列都应该包含在GROUP BY子句中
select depno,avg(sal)
from emp
group by depno;
多列分组
按部门、不同的职位,统计员工的工资总额
select depno,job,sum(sal)
from emp
group by depno,job;
group by语句的增强,主要用于报表
group by rollup(a,b) === group by a,b + group by a + group by null
break on depno skip 2(相同部门号只显示1次,不同部门号之间空2行)


查询10号部门的平均工资(从SQL优化角度看,尽量使用where)
select depno,avg(sal)
from emp
group by depno
having depno=10;
select depno,avg(sal)
from emp
where depno=10
group by depno;
不能在*WHERE子句中*使用组函数,先过滤,后分组
可以在*HAVING子句中*使用组函数,先分组,后过滤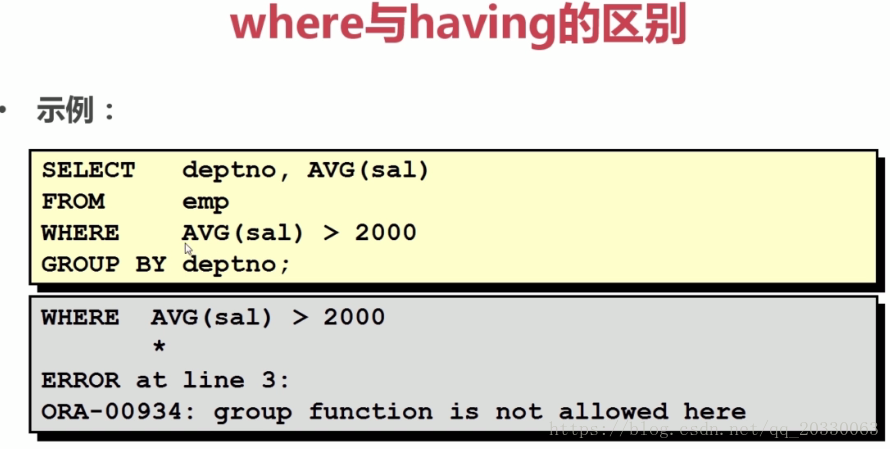
多表查询
笛卡尔积合表(子表的笛卡尔积)的列数是各个子表列数的和,行数是各个子表行数的积;因为笛卡尔积所产生的数据有些是正确的、有些是不正确的,有些是我们需要的、有些是我们不需要的,所以,多表查询的目的就是获取正确的、我们需要的数据。下面这个例子简单,我们需要的、正确的数据就是黄deptno=蓝deptno。为了保证笛卡尔积的效率,我们应该保证n张表做笛卡尔积,至少有n-1个连接条件
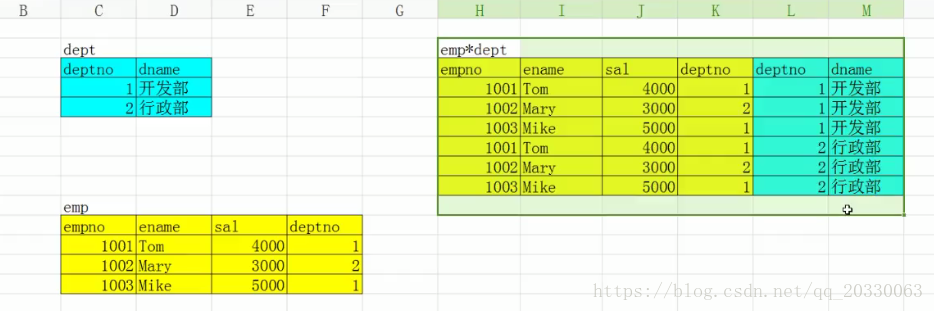
等值连接
实例:查询员工信息,要求显示:员工号、姓名、月薪、部门名称
select e.empno, e.ename, e.sal, d.dname
from emp e, dept d
where e.deptno=d.deptno; 不等值连接
实例:查询员工信息,要求显示:员工号、姓名、月薪、薪水级别
对于 between and 来讲,小值在前,大值在后
select e.empno, e.ename, e.sal, s.grade
from emp e, salegrades s
where e.sal between s.losal and s.hisal; 外连接
核心:通过外连接,把对于连接条件不成立的记录,仍然包含在最后的结果中
左外连接:当连接条件不成立时,等号左边的表仍然被包含
右外连接:当连接条件不成立时,等号右边的表仍然被包含
实例:按部门统计员工人数,要求显示:部门号、部门名称、人数(右外连接在等号左边写+号)
select d.deptno 部门号, d.dname 部门名称, count(e.empno) 人数
from emp e, dept d
where e.deptno(+)=d.deptno
group by d.deptno, d.dname; 内连接
通过别名,将一张表视为多表
实例:查询员工姓名和员工老板的姓名
内连接解决办法(不适合操作大表)
select e.name 员工姓名, b.name 老板姓名
from emp e, emp b
where e.mgr = b.empno
层次查询解决办法(可以替代自连接)
level是伪列,使用select引用
select level, empno, ename, sal, mgr
from emp
connect by prior empno = mgr
start with mgr is null(根节点表示法)
|| start with empno=7566(某节点表示法)
order by level;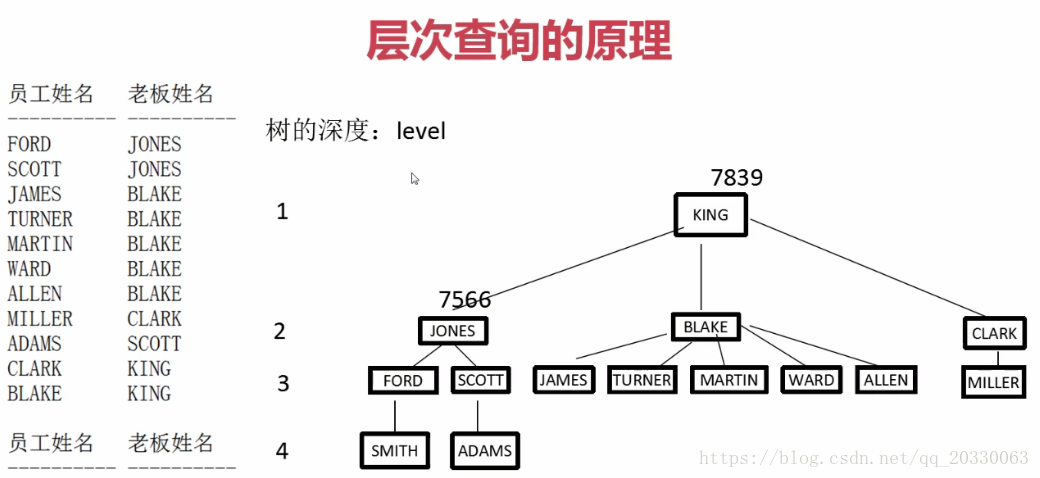
PL/SQL(Oracle数据库对SQL语句的扩展,是存储过程和自定义函数的必备基础)
**declare**
说明部分(变量说明、光标申明、例外说明)
begin
语句系列(DML语句)
exception
例外处理语句
end;
/基本变量类型
declare
--定义基本变量类型
--基本数据类型
pnumber number(7,2);
--字符串变量
pname varchar2(20);
--日期变量
pdate date;
begin
pnumber := 1;
dbms_output.put_line(pnumber);
pname := 'Gene';
dbms_output.put_line(pname);
pdate := sysdate;
dbms_output.put_line(pdate + 1);
end;
/引用型变量类型
将emp表格中ename的数据类型赋给pname
数据赋值两种方法:pname := 'Gene'; 或者 ename,sal into pname,psal
--引用型变量
declare
--定义引用型变量:查询并打印7839的姓名和薪水
pname emp.ename%type;
psal emp.sal%type;
begin
--得到7839的姓名和薪水
select ename,sal into pname,psal from emp where empno=7839;
--打印姓名和薪水
dbms_output.put_line(pname||'的薪水是'||psal);
end;
/记录型变量
代表表中的一行。因为一行包括多个列,所以记录型变量可以理解为数组变量,数组中的每一个元素都代表这一行某一列
emp_rec emp%rowtype;
emp_rec.ename := 'Gene';
declare
--定义记录型变量:注意代表一行
emp_rec emp%rowtype;
begin
--得到7839的姓名和薪水
select * into emp_rec into from emp where empno=7839;
--打印姓名和薪水
dbms_output.put_line(emp_rec.pname||'的薪水是'||emp_rec.psal);
end;
/declare
说明部分(变量说明、光标申明、例外说明)
**begin**
语句系列(DML语句)
exception
例外处理语句
end;
/IF语句
IF 条件 THEN 语句1;
语句2;
END IF;IF 条件 THEN 语句系列1;
ELSE 语句序列2;
END IF;IF 条件 THEN 语句;
ELSIF 语句 THEN 语句;
ELSE 语句 ;
END IF;--判断用户从键盘输入的数字
--接受一个键盘输入
--num: 地址值,含义是:在该地址上保存输入的值
accept num prompt'请输入一个数字';
declare
--定义变量保存用户从键盘输入的数字
pnum number := #
begin
-- 执行 if 语句
if pnum = 0 then dbms_output.put_line('输入的数字是0');
elsif pnum = 1 then dbms_output.put_line('输入的数字是1');
else dbms_output.put_line('输入的数字非0或1');
end if;
end;
/循环语句
WHILE total <= 2500 LOOP
……
total := total + salary;
END LOOP;LOOP
EXIT[WHEN 条件]
……
END LOOP;FOR I IN 1..3 LOOP
语句系列;
END LOOP;光标(为什么使用光标,在下图中有详细说明。下图的程序是错误的)
光标就是一个结果集
--光标的语法,中括号内容可以省略
CURSOR 光标名 [(参数名 数据类型[,参数名 数据类型]…)]
IS SELECT 语句;
--打开光标,执行查询
open c1
--取一行到变量中(取一行光标的值)
fetch c1 into pname;
--关闭光标,释放资源
close c1
-- 光标具体事例:查询并打印员工姓名和薪水
/*
光标的属性:
%notfound:如果fetch语句取到数据,为false,否则true
%found:如果fetch语句取到数据,为true,否则false
*/
SET SERVEROUTPUT ON;
declare
--定义一个光标
cursor cemp is select ename,sal from emp;
--为光标定义变量
pename emp.ename%type;
psal emp.sal%type;
begin
--打开光标
open cemp;
--取出光标记录
loop
--取一条记录
fetch cemp into pename,psal;
--思考:循环什么时候退出呀
--思考:一定可以取到数据吗
exit when cemp%notfound;
--打印
dbms_output.put_line(pename||'的薪水是'||psal);
end loop;
--关闭光标
close cemp;
end;
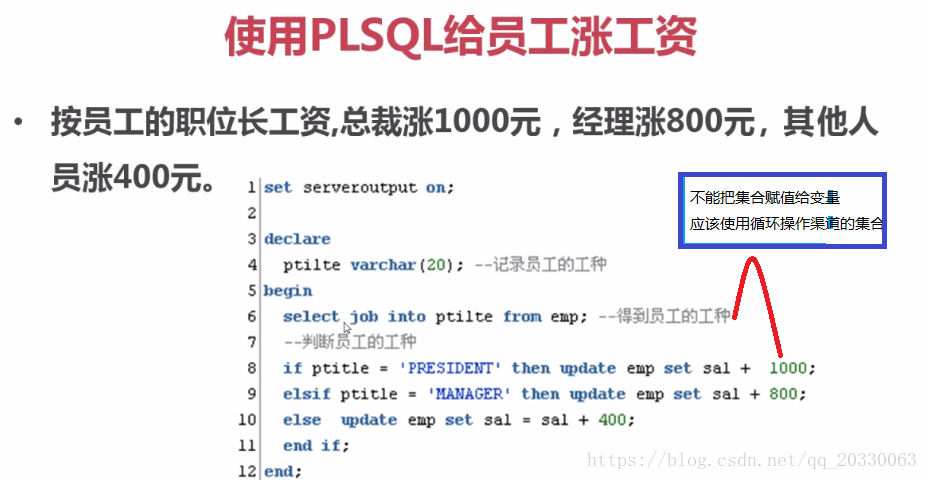
/--光标具体事例2:给员工涨工资,总裁1000,经理800,其他400
set serveroutput on;
declare
--定义光标代表给那些员工涨工资
cursor cemp is select empno,empjob from emp;
pempno emp.empno%type;
pjob emp.empjob%type;
begin
open cemp;
loop
-- 取出一个员工
fetch cemp into pempno,pjob;
exit when cemp%notfound;
--判断员工职位
if pjob = 'PRESIDENT' then update emp set sal=sal+1000 where empno=pempno;
elsif pjob = 'MANAGER' then update emp set sal=sal+800 where empno=pempno;
else update emp set sal=sal+400 where empno=pempno;
end if;
end loop;
close cemp;
commit;
dbms_output.put_line('涨工资完成');
end;
/--带参数的光标事例:查询某个部门中员工的姓名
set serveroutput on
declare
--定义带参数的光标
cursor cemp(dno number)is select ename from emp where deptno=dno;
pename emp.ename%type;
begin
open cemp(10);
loop
-- 取出每个员工的姓名
fetch cemp into pename;
exit when cemp%notfound;
end loop;
close cemp;
end;
/例外
系统例外
No_data_found(没有找到数据)
set serveroutput on;
declare
pename emp.ename%type;
begin
select ename into pename from emp where empno=1234;
exception
when no_data_found then dbms_output.put_line('没有找到该员工');
-- 捕获其他所有例外
when others then dbms_output.put_line('其他例外');
end;
/触发器(trigger
触发器的作用:每当一个特定的数据操作语句(insert、update、delete)在指定的表发出时,Oracle自动的执行触发器中定义的语句序列。
触发器的应用场景:1、复杂的安全性检查2、数据确认3、实现审计功能4、完成数据的备份和同步。
创建触发器的语法
如果有FOR EACH ROW [WHEN 条件]代表行级触发器,否则为语句触发器
语句触发器:针对表。在指定的操作语句操作之前或之后执行一次,不管这条语句影响了多少行
行级触发器:针对行。触发语句作用的每一条语句都被触发。使用:old 和 :new 伪记录变量,识别值得状态
CREATE TRIGGER 触发器名{INSTER | UPDATE[OF 列明] | DELETE}
{BEFORE | AFTER}
ON 表名
[FOR EACH ROW [WHEN 条件]]
PLSQL块
--第一个触发器saynewmep:每当成功插入一个新员工后,自动打印“成功插入新员工”
create trigger saynewemp
after insert
on emp
declare
begin
dbms_output.put_line('成功插入');
end;
/