基本实例
如果希望使用特殊字符,可以使用
<?xml version="1.0" encoding="UTF-8" standalone="true" ?>
<!DOCTYPE 书籍列表[
<!ELEMENT 书籍列表 ((计算机书籍+))>
<!ELEMENT 计算机书籍 ((书名,作者,价格)) >
<!ELEMENT 书名 (#PCDATA) >
<!ELEMENT 作者 (#PCDATA) >
<!ELEMENT 价格 (#PCDATA) >
]>
<书籍列表>
<计算机书籍>
<书名>数据结构</书名>
<作者>小刘</作者>
<价格>18.00</价格>
</计算机书籍>
<计算机书籍>
<书名>算法分析</书名>
<作者>小李</作者>
<价格>48.00</价格>
</计算机书籍>
</书籍列表>命名空间
作用:告知元素的所属
<?xml version="1.0" encoding="UTF-8"?>
<书籍列表>
<计算机书籍 xmlns:liu="http://liu.com.cn">
<liu:name>数据结构</liu:name>
<作者 xmlns:li="http://li.com.cn">
<li:name>小刘</li:name>
</作者>
<价格>18.00</价格>
</计算机书籍>
<计算机书籍>
<书名>算法分析</书名>
<作者>小李</作者>
<价格>48.00</价格>
</计算机书籍>
</书籍列表>XPath
XPath 语言是一门专门用于在 XML 文档中查询信息的语言,其他 XML 程序可利用 XPath 在 XML 文档中对元素和属性进行导航。
为什么要查找标签和属性呢?因为 XML 文档是用来存储数据的,所以我们需要将数据提取出来使用,所以通过查找标签和属性来进一步获取数据。
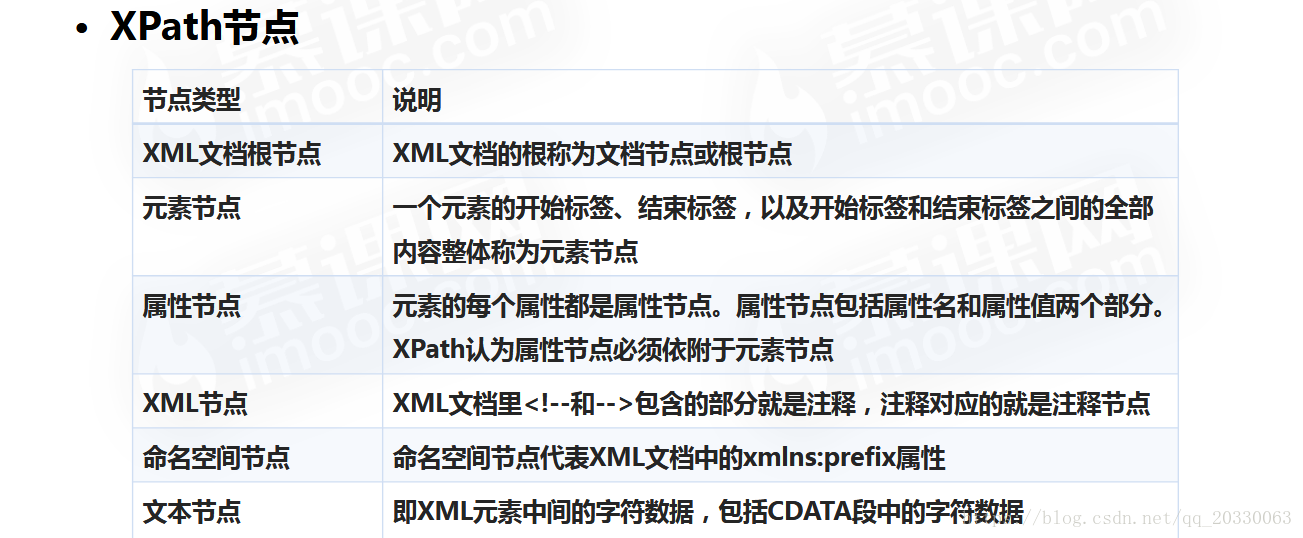
XPath 节点
XPath基本语法
1、路径(通过绝对路径或相对路径筛选节点集)
XPath 提供了 “|” 运算符,可用于组合多个路径表达式,从而可以一次选取多个路径。
例如:book[position()=1] | book[position()=last()]

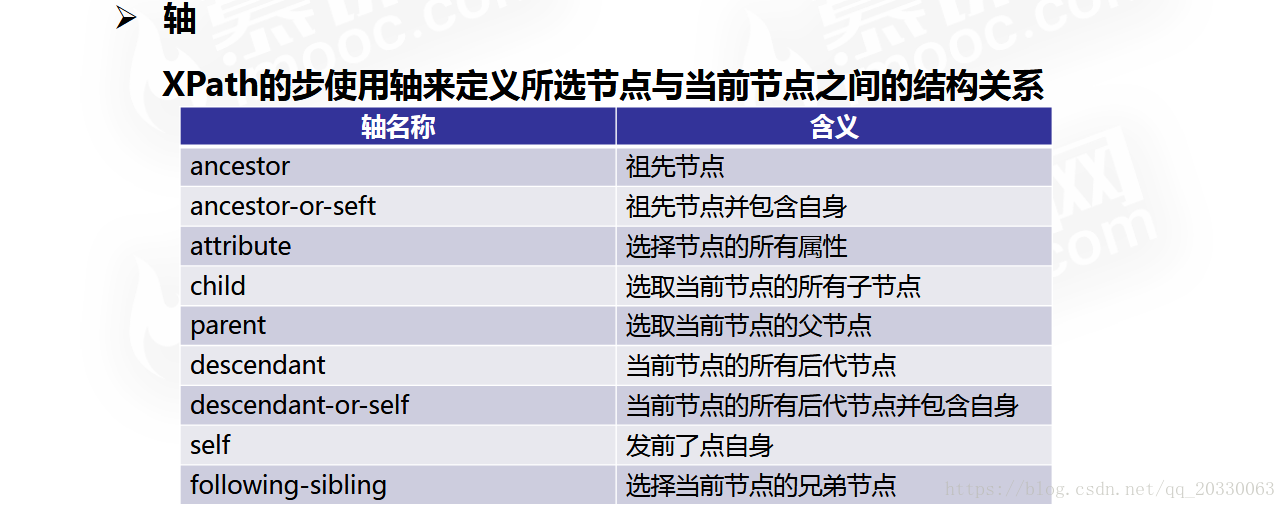
2、轴(通过节点间关系来过滤节点)
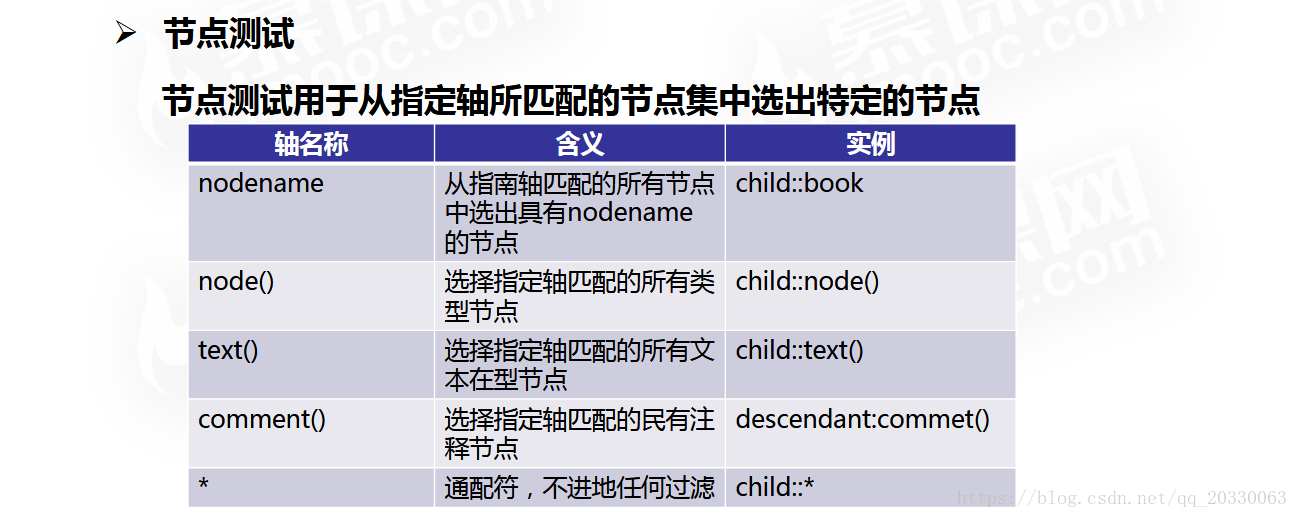
3、节点测试(进一步过滤需要的节点)
4、谓语(更进一步过滤所需要的节点)

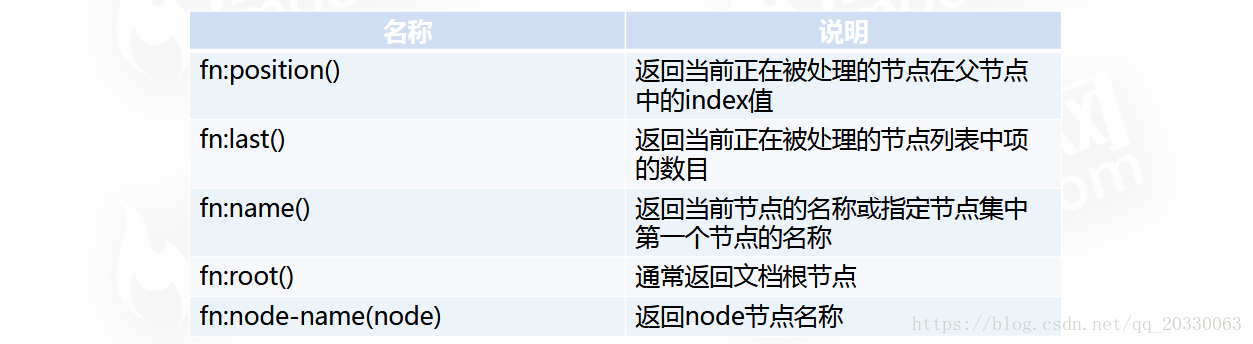
XPath函数
XML文档解析方式(原理:XML文档->XML解析器->解析结果)
DOM:文档对象模型,W3C推荐的处理XML文档的规范
SAX:整个XML行业的事实规范
处理机制:事件机制(没看到一个元素标签,就发送一个事件,事件监听器每监听到一个事件,就需要用使用处理器来处理这个事件)

JAXP:Java解析XML文档的API称为JAXP,全称是Java API for XML。因为定义的是接口,并没有实现,所以实际使用过程中还是需要具体的解析实现的。这就为开发者带来了便利,允许应用程序在不同的XML解析器之间进行切换。



实例:解析XML文档
实现思路
1、在工程中引入 Xeerces-J 具体解析器实现类 jar 包
2、自定义事件监听器(继承自DefaultHandler)
3、通过SAXParseFactory的newInstance()方法创建SAX解析器工厂对象
4、通过SAXParseFactory对象的newSAXParse()方法创建SAXParse对象
5、通过SAXParse对象的parse()方法解析XML文档
package com.muke.sax;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;
import com.natapp.sax.handler.MuKeHandler;
public class SAXParse {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//创建SAX解析器工厂
SAXParserFactory factory= SAXParserFactory.newInstance();
//创建SAX解析器
SAXParser parser= factory.newSAXParser();
//开始解析XML文档
parser.parse("D://firstxml.xml", new TestHandler());
}
}
package com.natapp.sax.handler;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class TestHandler extends DefaultHandler {
//定义一个变量来保存当前正在处理的tag
private String currentTag;
//每当处理文本数据时将触发该方法
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
String content=new String(ch,start,length);
if (content.trim().length()>0) {
System.out.println("<"+currentTag+">元素的值是:"+content.trim());
}
}
//解析文档结束时触发该方法
@Override
public void endDocument() throws SAXException {
System.out.println("解析文档结束");
}
//解析元素结束时触发该方法
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.println("处理元素结束:"+qName);
}
//每当解析文档开始时触发该方法
@Override
public void startDocument() throws SAXException {
System.out.println("解析文档开始");
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.println("开始处理元素:"+qName);
currentTag=qName;
if (attributes.getLength()>0) {
System.out.println("<"+currentTag+">元素的属性如下:");
for (int i = 0; i < attributes.getLength(); i++) {
System.out.println(attributes.getQName(i)+"--->"+attributes.getValue(i));
}
}
}
}