一、json 模块
1、定义
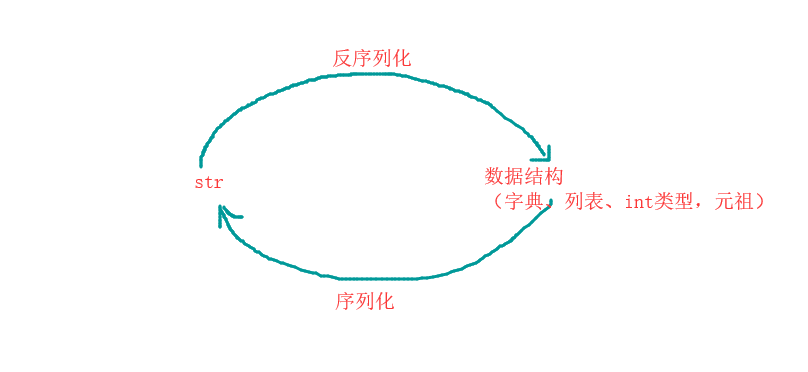
将字典、列表等内容转换成字符串的过程就是序列化。
操作的数据类型有限,但是可以支持所有编程语言操作。
2、为什么要有序列化?
1、以某种存储形式使自定义对象持久化。
2、将对象进行传递
3、是程序更具维护性
3、四大功能 (dumps,loads,dump,load)
dumps loads
import josn lst = ['aa'', 11, 'b3'] ret = json.dumps(lst) # 序列化 print(ret) ret1 = json.loads(ret) # 反序列化 print(ret1)
dump load
import json with open ('t1.txt',mode='w',encoding= 'utf-8') as f: json.dump(lst, f) # 序列化 # dump 用于直接将序列化的字符串写入文件中 with open ('t1.txt',mode='r',encoding= 'utf-8') as f: print(json.load(f)) # 反序列化 # load 可以将文件中的字符串返回来
json 模块的限制
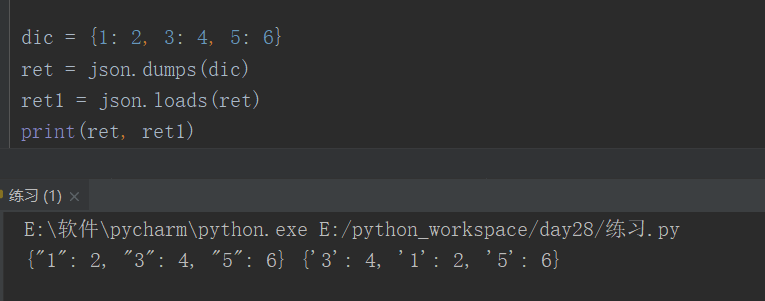
1、json 操作字典的时候,key 必须是字符串形式。
2、json 格式的字典,的key 不能是数字,如果是数字,会被强行转成str。且进行反序列化后,还是字符串。
3、json格式中的字符串必须是双引号的形式,如果将json 格式的字符串的双引号换成单引号,就会报错。
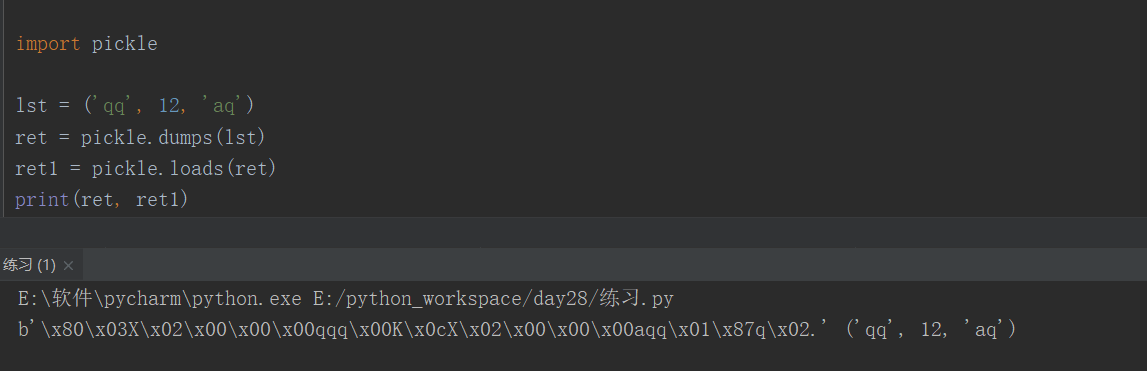
4、json 对元祖进行序列化是会被强行转换成列表,反序列化后还是列表,而不会返回元祖。
5、json 支持元祖做字典的value值,不支持做key 。
6、json.dump支持多次dump写入文件,但不支持load。(因为写入后会出现,多种类型出现在一行)。

要想dump多个数据进入文件,需要用dumps

7、对于中文,如果不处理,序列化后会变成ascii码类型。
因此,ensure_ascii = False 时,就可以是中文类型了。
8、set 不能被dumps/dump
二、pickel 是python特有的模块,不能跨语言,但是支持的数据类型多样。
1、dumps, loads (pickel.dumps 的结果是bytesle类型)
2、dump load
如果对文件进行操作,dump时,需要时 wb 模式写入,而进行 load时,需要 rb 模式读出。
3、可以进行多次dump/load 操作。
三、shelve
1、当你写定一个文件后,对文件的改动较小,读取文件的次数较多的时候,可以使用shelve。