序列化-------转向一个字符串数据类型的过程
从数据类型 ---->字符串的过程 叫做序列化
从字符串----->其他数据类型的过程 叫做反序列化
字符串在哪用?
写文件,数据存储
网络上传输的时候
1**、json** 通用的序列化格式*****
只有很少的一部分数据类型可以转化为字符串
2、pickle ****
#所有的Python中的数据类型都可以转换为字符串类型
#pickle序列化的内容只有Python理解
#且部分反序列化依赖Python代码
3、shelve 特点:好操作
有序列化句柄,使用序列化句柄操作
注:有些代码块不能同时运行,需注意何时注释掉
#1、json
可以序列化的数据类型:数字,字符串,列表,字典,元组(转化为列表)
dumps序列化方法 loads反序列化方法
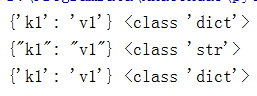
dic={'k1':'v1'}
print(dic,type(dic))#dict
import json
strd=json.dumps(dic)#序列化
print(strd,type(strd))#string
dic_d=json.loads(strd)#反序列化
print(dic_d,type(dic_d))
dump 、load 和dumps、loads相似,只是前者和文件进行了关联
json dunmp load
注:只能一次性写进去,一次性读出来
dic={1:'a',2:'b'}
f=open('a.txt','w',encoding='utf-8')
json.dump(dic,f,ensure_ascii=False)
json.dump(dic,f,ensure_ascii=False)#再写入一条 ,会出错
#如果写进去多次,load的时候就会报出这样错json.decoder.JSONDecodeError: Extra data: line 1
f=open('a.txt')
result=json.load(f)
print(result,type(result))
f.close()
2、pickle
可以序列化任何数据类型
dumps,loads
import pickle
ddic={'k1':'v1','k2':'v2','k3':'v3'}
str_ddic=pickle.dumps(ddic)
print(str_ddic)#序列化之后得到一串二进制内容
dic2=pickle.loads(str_ddic)
print(dic2,type(dic2))#得到字典
dump,load
时间类型,也可序列化,也可分布dump 分布load,这json形成对比
import time
struct_time=time.localtime(1000000000)
print(struct_time)
f=open('c.txt','wb')
pickle.dump(struct_time,f)
f.close()
f=open('c.txt','rb')
struct_time2=pickle.load(f)
print(struct_time2)
f.close()
3、shelve
会创建好几个文件
import shelve
‘’’
由于shelve在默认的情况下不会记录持久化 对象的任何修改,所以我们再
shelve.open()的时候修改默认参数,否则对象 的修改不会保存
'''
f=shelve.open('shelve_file')
f['key']={'int':10,'float':9.5,'string':'sample data'}#z直接对文件句柄操作,就可以
f.close()
#
import shelve
f1=shelve.open('shelve_file')
existing =f1['key']#取数据的时候也只需要直接用key获取即可,但如果key也不存在也会报错
f1.close()
print(existing)
修改
import shelve
f2=shelve.open('shelve_file')#没有改默认参数,修改后不会改
print(f2['key'])
f2['key']['newvalue']='thishisf'#修改值
f2.close()
f2=shelve.open('shelve_file',writeback=True)#这里修改默认参数,修改后的内容可以保存
print(f2['key'])
f2['key']['newvalue']="woshinibaba"#修改值
f2.close()
‘’’
writeback有有点也有缺点。
优点是:减少了我们的出错概率,并且让对象持久化对用户更透明化;
但是这种方式并不是所有情况都需要,首先,使用writeback以后,
shelf在open的时候会增加额外的内存消耗,并且当DB在close()的时候
会将缓存中的每一个对象都写入DB,这也会带来额外的等待时间,以为
shelve没有办法知道缓存中哪些对象修改了,哪些没有修改,因此所有对象斗湖被写入。
‘’’