摘要: 作为函数式编程的核心,函数对象的创建和传递都有不同的实现方法。本文将带领你一同了解四种函数对象创建方法和两种函数对象传递方法,并剖析其各自的优劣之处。
摘要:作为函数式编程的核心,函数对象的创建和传递都有不同的实现方法。本文将带领你一同了解四种函数对象创建方法和两种函数对象传递方法,并剖析其各自的优劣之处。
数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
本次直播视频精彩回顾,戳这里!
直播涉及到的PPT,戳这里!
专家简介:
陶云峰,阿里云高级技术专家,上海交通大学理论计算机科学博士,专注数据存储、分布式系统与计算等领域,写了20多年程序。2000年参加ACM/ICPC大赛,实现亚洲队伍进World Final前十的突破。
在函数式编程中,最重要的自然是函数对象。在c++中,函数能够像参数一样传进另外一个函数,也能够像普通对象一样,作为某个函数的返回值。常用的函数对象写法有四种:
1、函数指针
2、自定义的operator()
3、std::function
4、Lambda expression(c++11才引入的新特性)
函数对象的发展史大致可以划分如下:
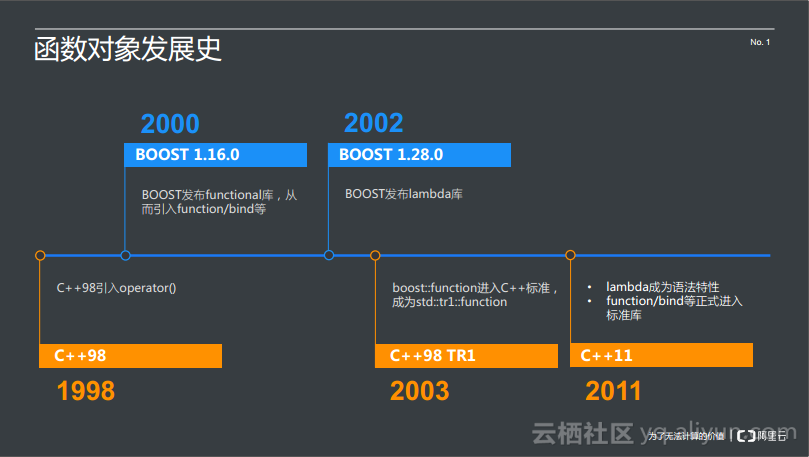
1998年,C++98引入了operator()。两年后,BOOST发布了functional库,从而引入了function/bind等。又过了两年,BOOST发布了lambda库。到了2003年,C++98做了第一次修订,boost::function进入了C++标准,成为了std::tr1::function。8年后,在C++11中,lambda成为语法特性,function/bind等正式进入标准库。
一、函数对象的四种写法
1、C风格的函数指针
具体实现代码如下:

首先定义了一个函数指针类型typedef void (*Fn)();这个函数指针没有参数、没有返回值。在test(f)中,可以将f函数作为参数进行传递,f()函数没有参数,也没有返回值,满足Fn这个类型的定义。
但是C风格的函数指针存在两个问题,一个问题是性能,另一个问题是在数据绑定方面,这种写法不好用。数据绑定是指绑定某个特定的值到函数的某个特定的参数上,从而使高维的函数变成低维的函数。数据绑定的一个典型案例是线程池:对于线程池的作者来说,他希望用户传递给他无参数、无返回值的函数;对于用户来说,无参数、无返回值、无副作用的函数是没有用的,只能引入副作用。而无参数、无返回值、有副作用的方式只有一种实现方法——全局变量,但是全局变量是一个非常难使用的特性,往往会产生许多难以发觉的bug。因此产生了一种妥协的办法,如下图所示:
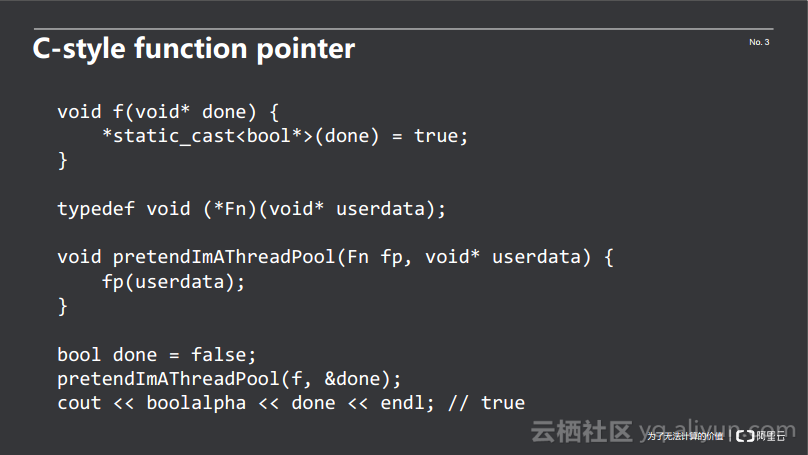
用户交给线程池两样东西:一个是函数指针,另一个是用户自定义的数据结构。由于线程池不知道也不关心这个数据结构,因此将其表示成了void*,用户在使用的时候,需要将void*转成实际的数据结构再去使用。
这种方法虽然可行,但却存在一个问题,即无法识别用户的数据类型,如上图中的bool类型传入f()函数,导致无法发挥C++强类型的优势。倘若用户交给pretendImAThreadPool的不是一个bool类型,就会导致程序运行失败。
2、operator()
由于上面的C风格的函数指针方法较为危险,在C++98的时候出现了operator(),解决了上面线程池场景中的问题,如下图所示:

在C++中,处理副作用的方式是使用对象来包装副作用。在类NullaryFn中,存在一个全局变量mDone,这个全局变量就是副作用。在使用的时候,先通过Fn fn声明一个对象,然后通过pretendToBeAThreadPool(fn)将其传给线程池。
这种方法解决了C风格函数指针中存在的一些问题,但它自身也存在两个问题:
(1)每个函数都需要创建一个新的类,导致语法上比较啰嗦。
(2)在语句virtual void operator()() = 0中引入了虚接口,然而对于一些第三方的类,没有这种声明这类接口,只能借助于代理对象的方法,即在每次使用时,都需要包装一个代理对象。
3、std::function
第三种写法是std::function。boost的老妖怪们将代理对象的使用抽象化,然后借助于模板技术,将代理对象的产生包裹在了bind()函数中,如下图所示:
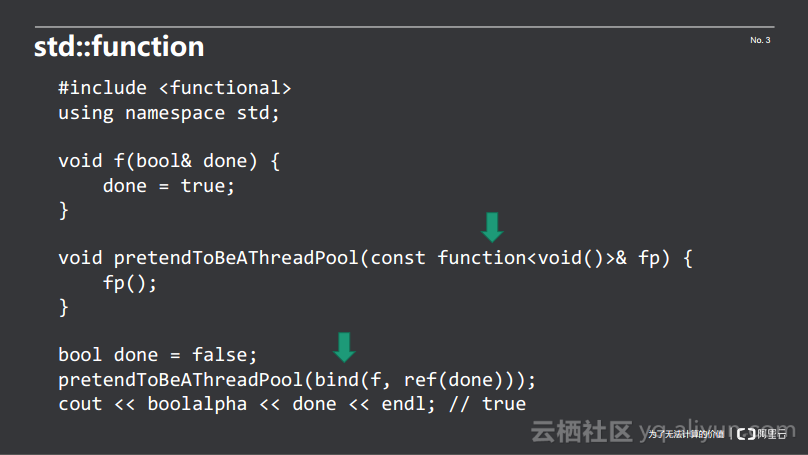
此时,线程池接收的是一个function对象,该对象没有参数,也没有返回值,在使用的时候直接调用fp()。而在交给线程池的时候将函数f和bool变量done的引用绑在一起即可,整个过程完全避免了operator()的两个问题。
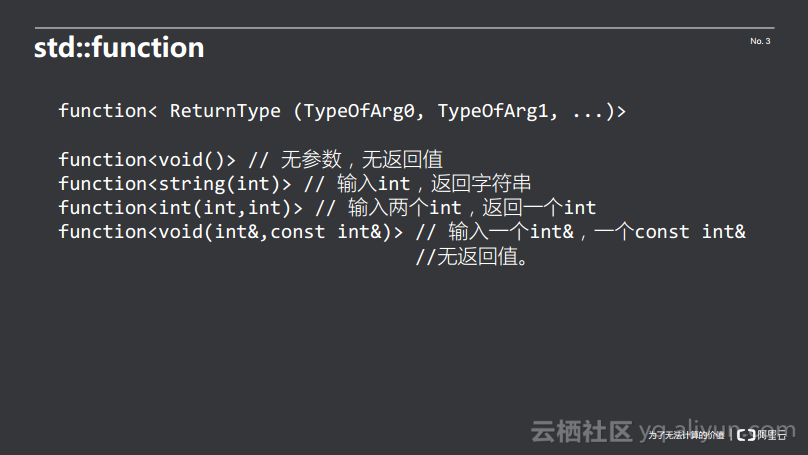
可以看到,function< ReturnType (TypeOfArg0, TypeOfArg1, ...)>中,ReturnType 代表其返回值,(TypeOfArg0, TypeOfArg1, ...)代表其各个参数的类型,如下面的四个例子:
(1)function<void()>表示无参数、无返回值。
(2)function<string(int)>表示输入int类型的数据,返回一个字符串。
(3)function<int(int,int)>表示输入两个int类型的数据,返回一个int类型的数据。
(4)function<void(int&,const int&)>表示输入一个int&,一个const int&,无返回值。
前文中提到的bind(f, ref(done)),是将一个一元函数绑定到一个值上,然而在很多情况下,需要将高元函数绑定到多个值上,以达到降维的目的。例如下图中的例子:
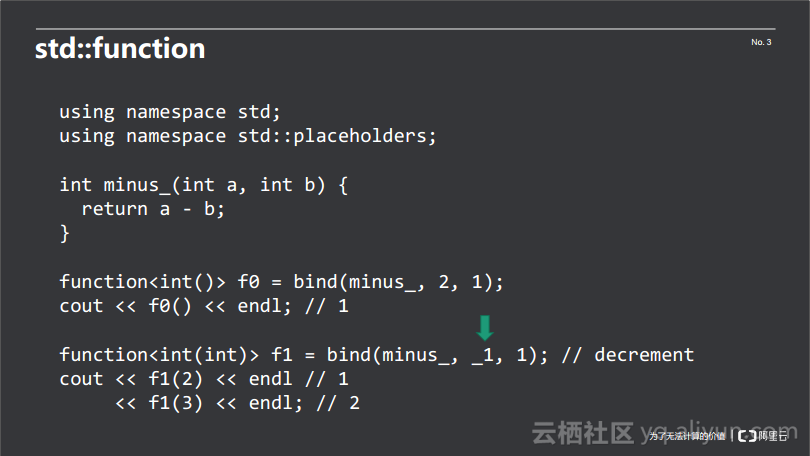
其中定义了一个减法运算minus_(int a, int b),返回值为a-b的值。然后借助于bind(minus_, 2, 1)将int类型的值2绑定到minus_()函数的第一个参数上,将值1绑定到第二个参数上。由于原函数的两个参数都已绑定,所以它是一个零元的函数。f0用于储存函数的返回值。如果想将其变成一元的函数,可以使用bind(minus_, _1, 1)的写法,其中_1代表在第一个参数上留一个空位,把值1绑定到第二个参数上。这样在调用的时候,需要传入一个参数以填补第一个参数的空位,如f1(2)中,将值2填补到第一个参数,返回值即为2-1=1。同理,f1(3)的返回值为3-1=2。

其实除了_1外,还有_2,_3...,_9,但在使用的时候,一般不会超过_5。_1的实际含义是绑定后函数的第一个参数,_2即为绑定后函数的第二个参数。像上图中bind(minus_, _2, 1)的用法是会报错的,因为minus_()本身是一个二元函数,在绑定之后,值1被绑定到第二个参数上,这样在绑定之后的函数没有第二个参数,所以使用_2会报错。
此外还有一些特殊用法,如bind(minus_, _1, _1)将一个占位符绑定到两个参数上,这样在调用f1(2)时,实际上是minus_(2, 2),返回值为2-2=0,这样将二元的函数变成了一个一元的函数。还有bind(minus_, _2, _1)可以达到交换两个参数位置的目的,在正常调用minus_(1, 2)时,输出1-2=-1,而在调用f2(1, 2)时,由于两个参数位置交换了,输出为2-1=1。
上面提及的都是绑定值类型,接下来看看绑定引用,如下图所示:

其中negate_()函数实现的功能很简单,即将第二个参数的相反数赋值给第一个参数。function<void(int)> f0 = bind(negate_, a, _1),在调用f0(1)后,并没有将a的引用与函数的第一个参数绑定,而是将a的副本与其绑定,因此在输出的时候,a仍为初始值0,a的副本的值为-1。若想改变a的值,需要将a的引用与函数第一个参数绑定,即function<void(int)> f0 = bind(negate_, ref(a), _1),此时便可将值1的相反数赋值给a,输出的a值即为-1。绑定const引用是个比绑定引用更坑的事情。绑定引用如果没有用ref,往往程序马上就出错了,一做测试马上能发现。但是const引用往往不会有逻辑上的错误,但是会引入不必要的对象复制。这种性能问题就很难在review代码的时候或者功能测试的时候发现。
除了普通函数外,成员函数也可以进行绑定,如下图所示:

上图中的negate()函数,参数列表中有一个隐藏的this指针,它实际上是一个二元函数。在使用function<void(int)> f = bind(&negation::negate, &a, _1)时,有两个需要注意的地方:
(1)在抽象函数名前必须添加取地址符,普通函数名前没有这个限制。
(2)在a对象前添加取地址符,对于negate()函数的this指针的参数,需要进行bind()。对于a对象,它的this值是它自己的地址,因此需要加一个取地址符。
4、Lambda expression
下图是Lambda表达式的一个完整例子:

一个完整的Lambda表达式共包含六部分:捕获、参数、可变性、异常、返回值类型和函数体。其中异常和返回值类型可以省略,编译器会自动做推导。
在编写函数体时,可能会使用到函数体外的代码块中的变量名或者变量值,这种时候就需要进行捕获。捕获大致可以分为以下几类:
(1)无需捕获

上图为最简单的情况,即该函数无需进行捕获(中括号内为空),函数体中的所有变量都已在参数列表中出现。
(2)值捕获

在捕获列表中直接写入变量名时,属于值捕获。如上图中,在f()函数体中,会产生一个x值的副本、y值的副本,虽然在程序的最后改变了x、y的值,但是f()的函数体中使用的是它们的副本,因此返回的值是-1。
在函数体中,可以对捕获到的值的副本进行改变,如下图所示:

在Lambda表达式中添加了可变性的声明后,便可对x、y值的副本进行更改。当然对x、y副本值的改变并不影响x、y自身的值,因此在最后输出的时候,x、y的值仍然是0和1。
(3)引用捕获

如果想在函数体中改变函数体外x、y变量的值,可以进行引用捕获。在[&x, &y]中捕获的分别是x的引用和y的引用,因此在函数体内对x、y的值进行修改的时候,实际上是修改的函数体外x、y的值。另外,f对象的生命周期必须短于x、y变量的生命周期,否则会出现悬空指针的错误。
当函数体中需要捕获环境中的很多变量时,可以使用默认值的形式进行捕获,如下图所示:

其中[=, &y]中的”=”代表默认使用值捕获的方式捕获上面的变量,”&y”代表的是个别需要采用引用捕获的变量。另外如果使用[&, x],则代表默认使用引用捕获,而变量x是个例外,变量x采用值捕获。
除了捕获环境中变量名和变量值外,还可以对其进行运算,如下图所示:

图中将x的值赋给了a,将y的地址赋给了b。需要注意:在函数体中不能再使用x和y;y前面的’&’代表的是取地址,而不是引用捕获。
表达式捕获最常用的场景是移动环境中的对象到lambda对象内。这样函数对象的生命期就可以和其捕获的变量的生命期脱钩。捕获中的表达式在lambda表达式执行的时候执行。这和函数体内移动是不同的。函数体内的移动在执行lambda对象的时候执行。

Lambda表达式的类型是编译器给出的,并不是std::function,该类型可以隐式地转化成std::function。忽略这一点往往会导致程序报错,如下图所示:

二、传递函数对象的两种写法
在了解如何构造函数对象之后,还需要知道如何传递函数对象。目前可行的方法有两种:模板和传std::function对象。如下图所示:

这两个方法在通用性上没有差别。差别在于,g0函数里编译器可以看到f的细节,从而可以做内联以及其他一些编译优化;而在g1里,编译器看不到f的细节,于是也做不了优化。这是说,模板配合inline operator()和lambda性能好,但是会有代码膨胀;std::function方法正好相反。另外,一般而言,阅读模板总比阅读std::function困难些。