一、python中的代码块
代码块如何理解?
代码块:同一个模块,函数中、类中、一个文件中等
在cmd窗口命令中,进入python的运行环境,每一行代码都是一个代码块
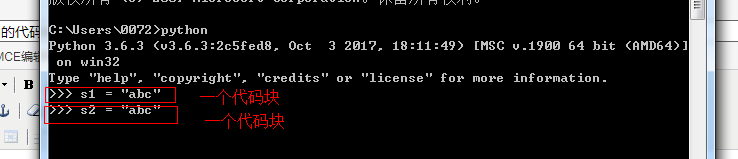
一个文件中的两个函数、两个类等是不同的代码块:

二、“==” 、id 、is
"==" :比较的是两个对象的值
id:获取该对象的内存地址值

is:判断的是两个对象的内存地址值是否相同
内存地址值:内存地址值是唯一的
is 判断是True,则“==”一定是True
三、小数据池(缓存机制,驻留机制)
1、什么是小数据池?
理解:python自动将-5~256的整数、有一定规则的字符串、都放在一个池中,只要是变量是这些范围内的整数或者是字符串,则直接引用,不需要另外开辟一块内存
小数据池的应用数据类型:-5~256之间的整数、字符串、bool值
2、小数据池的作用?
1)节省内存
2)提高性能和效率
3、int
只要数据范围是-5~256之间,多个变量都是指向这个范围中的数字时,就是指向同一个内存地址。用is判断就是True
4、str
(1)字符串的长度是0或者1,默认是驻留机制

(2)字符串的长度大于1时,且只含大小写字母、数字或者是下划线的任意组合,默认是驻留机制

(3)在字符串中使用到乘法
1)只在一个字符串中使用乘法,当乘数为1时,默认都是采用驻留机制,字符串可以是大小写字母、数字、下划线、特殊字符以及中文任意组合
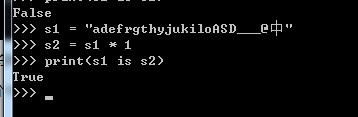
2)两个字符串中都使用乘法
i)当乘数为1时,且只含大小写字母、数字或者是下划线的任意组合,默认是驻留机制
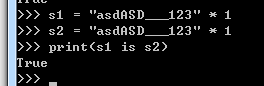
ii)当乘数为1时,字符串的长度是0或者是1时,默认是驻留机制
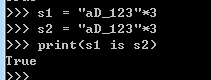
iii)当乘数>=2时,且只含大小写字母、数字或者是下划线的任意组合,最后总长度是小于等于20,默认是驻留机制
(4)指定驻留

5、bool
bool值就是True False 就是在小数据池中已经存在
四、代码块与小数据池的关系
对于下面这段代码分别在pycharm中和cmd命令窗口
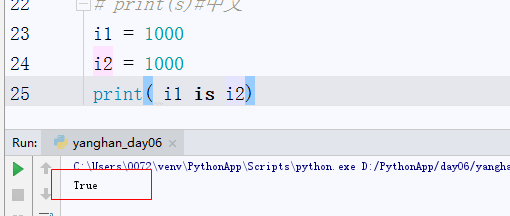

结果不同,在cmd命令窗口中再结合之前的小数据池的概念,是false是没有问题的,但是在pycharm中,返回的是True,为什么?
解决pycharm中的这个问题?结合代码块与小数据池的概念
在pycharm中运行同一个代码块,初始化变量时,会先检查该变量是否在字典中存在,如果不存在,就把变量和该值的内存地址值以key:value的形式存储到一个字典中,在遇到新的初始化变量时,先在字典中查找记录,如果有同样的记录,会重复使用这个内存地址值,就是指向同一个内存地址值
运行不同的代码块时,先看是否满足小数据池中的数据,如果满足指向同一个对象,如果不满足小数据池的数据,则是两块代码,指向不通过的对象,is比较是false
五、编码
1.编码方式回顾
ASCII:只对英文大小写字母、数字、一部分特殊字符,一个字节代表一个字符,一个字节由八位组成,一共是256位
Unicode:万国码
初期:英文 ------ > 16位组成,2个字节
中文---------> 16位组成,2个字节
升级:英文 -------> 32位组成,4个字节
中文-------->32位组成,4个字节
浪费资源
utf-8:
英文------>1个字节
欧洲------->2个字节
中文-------->3个字节
gbk :有字母、数字、特殊字符和中文组成
英文------->1个字节
中文-------->2个字节
编码之间是不能相互识别的
规定文件存储和网络传输使用非Unicode的编码方式
对于大环境下的python3x的版本:字符串在内存中的默认编码方式是Unicode
2、bytes
(1)bytes是python中的基础数据类型之一,bytes中的方法基本上和str的方法相同
格式: b1 = b"adc"
(2)bytes 与 str 的区别:
1)英文
表现形式:s = "abc"
b = b"abc"
内存中的编码方式:str :Unicode bytes:非Unicode
2)中文
表现形式:s = "中国“
b = s.encode("utf-8")
内存中的编码方式:str :Unicode bytes:非Unicode
(3)bytes与str的相互转化
str -------------- > bytes encode() 编码
s = "世外桃源"
b = s.encode("utf-8")
#b'\xe4\xb8\x96\xe5\xa4\x96\xe6\xa1\x83\xe6\xba\x90'
bytes ----------> str decode()解码
b = b'\xe4\xb8\x96\xe5\xa4\x96\xe6\xa1\x83\xe6\xba\x90'
s = b.decode("utf-8")
注意:以什么方式进行编码就以什么方式进行解码