1.线程安全
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
----使用锁,维护计数器的串行访问与安全性
import java.util.ArrayList;
import java.util.List;
public class TestAddToList implements Runnable{
public static List<Integer> numberList = new ArrayList<Integer>();
int startNum = 0;
public TestAddToList(int startNum){
this.startNum = startNum;
}
@Override
public void run(){
int count = 0;
while(count < 1000000){
numberList.add(startNum);
startNum += 2;
count++;
}
}
public static void main(String[] args) throws Exception{
Thread t1 = new Thread(new TestAddToList(0));
Thread t2 = new Thread(new TestAddToList(1));
t1.start();
t2.start();
while(t1.isAlive()||t2.isAlive()){
Thread.sleep(1);
}
System.out.println(numberList.size());
}
}

为什么会越界呢?
如果单线程是不会出现越界的情况的,因为list在不够用的时候回扩容,但是多线程来说,在list正要准备扩容的时候,理应不能对list进行操作的,但是没有相关代码进行处理,所以在扩容的时候, 有线程继续往里面添加元素,导致数组越界。
2.对象头Mark
-Mark word, 对象头的标记,32位
-描述对象的hash、锁信息,垃圾回收标记,年龄
------指向锁记录的指针
------指向monitor的指针
------GC标记
------偏向锁线程ID
3.偏向锁
--大部分情况是没有竞争的,所以可以通过偏向来提高性能
--所谓的偏向,就是偏心,即锁会偏向于当前已经占有锁的线程
--将对象头mark的标记设置为偏向,并将线程ID写入对象头Mark
--只要没有竞争,获得偏向锁的线程,在将来进入同步块,不需要做同步
--当其他线程请求相同的锁时,偏向模式结束
-- -XX:+UseBiasedLocking ----默认启用
--在竞争激烈的场合,偏向锁会增加系统负担
4.轻量级锁
--嵌入在线程栈中的对象

--普通的锁处理性能不够理想,轻量级锁是一种的快速的锁定方法
--如果对象没有被锁定
------将对象头的mark指针保存到锁对象中
------将对象头设置为指向锁的指针(在线程栈空间中)
锁对象拥有对象头的mark指针,对象头拥有指向锁的指针。笼统来讲就是,线程栈指向对象头,对象头指向线程栈,一个循环引用的过程

将对象头的mark备份到锁中,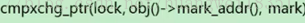
如何判断线程持有这个锁,只需判断对象头的指针是不是指向线程栈中的锁的方向。
--如果轻量级锁失败,表示存在竞争,升级为重量级锁Monitor
--在没有锁竞争的前提下,减少传统锁使用OS互斥量产生的性能损耗
--在竞争激烈时,轻量级锁会做很多很多额外操作,导致性能下降
5.自旋锁
线程在那边什么都不做,只是在做空循环循环体里面没有任何语句,也不挂起,等待一把锁。
--当竞争存在时,如果线程可以很快获得锁,那么可以不再OS层挂起线程,让线程做几个空操作(自旋)
--JDK1.6中-XX:+UseSpinning开启自旋锁
--JDK1.7中,去掉此参数,改为内置实现
--如果同步块很长,自旋失败,会降低系统性能,因为自旋目的是不需要线程挂起就能获得锁,我用空转指令代替线程挂起和恢复的开销,只要空转指令的成本小于,挂起和恢复的开销,就是合算的,如果自旋之后,我还拿不到锁,最终还是要挂起和恢复,那么自旋就是无用功,更加降低系统性能。
--如果同步块很短,自旋成功,节省线程挂起切换时间,提升系统性能
6.偏向锁、轻量级锁、自旋锁的总结
--不是java语言层面的锁优化方法
--内置于JVM中的获取锁的优化方法和获取锁的步骤
------偏向锁可用会优先尝试偏向锁
------轻量级锁可用会先尝试轻量级锁
------以上都失败,尝试自旋锁
------在失败,尝试普通锁,使用OS互斥量在操作系统层挂起
7.锁优化
减少锁持有时间
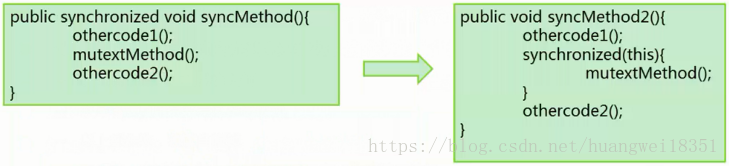
只对需要同步的块进行同步,这样有助于减少锁的持有时间, 就减少线程等待的时间,这样如果你需要自旋,那么自旋成功的概率就会增大,提升系统性能。
减小锁粒度
--将大对象,拆成小对象,大大增加并行度,降低锁竞争
--偏向锁,轻量级锁成功率提高
--HashMap的同步实现

一旦有put或者get操作,整个hashmap集合都会被锁住,这回让效率变慢,如下操作可以加快效率
--ConcurrentHashMap
------若干个Segment:Segment<K, V>[] segments
------Segment中维护HashEntry<K, V>,相当于小的hashmap
------put操作时,先定位到Segment,锁定一个Segment,执行put
普通hashmap里面只有一个大数组,如果进行put操作时,需要对大数组进行加锁,而—ConcurrentHashMap中有若干个数组,进行put操作时候,只需对小数组进行加锁
--减小锁粒度之后,--ConcurrentHashMap允许若干线程同时进入
锁分离
--根据功能进行锁分离
--ReadWriteLock
--读多写少的情况,可以提高性能

--读写分离思想可以延伸,只要操作互不影响,锁就可以分离
--LinkedBlockingQueue
------队列
------链表

在多线程中,如果只使用一个锁,那么在take 的时候,需要锁住链表,put不能进行,在put的时候,也需要锁住链表,take不能进行,这样对于效率来说并不好,竞争也比较激烈。然后锁分离状况,take使用take锁,put使用put锁,take和put就可以同时进行,效率也会提高。
锁粗化
通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁,只有这样,等待这个锁上的其他线程才能尽早的获得资源执行任务。但是,凡事都有个度,如果对同一个不停的进行请求、同步和释放,其本身也会消耗系统的宝贵资源,反而不利于性能的优化。
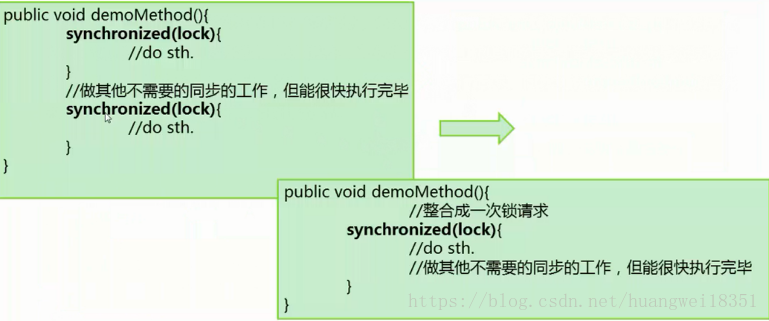
修改前,两个同步块需要频繁拥有锁,而中间的不需要同步的代码会很快执行完毕,因此返回拥有和释放锁,会引起效率下降。应该将其整合成一块,从而减少拥有和释放锁的次数
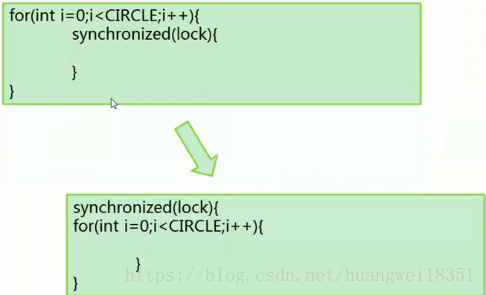
锁消除
--在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作
public class TestLockClear{
public static String createStringBuffer(String s1, String s2)
{
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
public static void main(String[] args)
{
long start = System.currentTimeMills();
for(int i = 0; i < 1000; i++)
{
createStringBuffer("JVM", "Diagnosis");
}
long bufferCost = System.currentTimeMills() - start;
System.out.println("createStringBuffer: " + bufferCost + "ms");
}
}
StringBuffer本身是个线程安全的类,append方法是同步操作
上述createStringBuffer方法里面的sb是局部变量,不会引起线程不安全的问题,所以append方法里面的锁就是多余,会降低运行效率,可以将其通过下面命令进行锁消除
-server –XX:+DoEscapeAnalysis –XX:+EliminateLocks开启锁消除
-server –XX:+DoEscapeAnalysis –XX:-EliminateLocks关闭锁消除

8.无锁
--锁是悲观的操作,无锁是乐观的操作
--无锁的一种实现方式
------CAS(Compare and swap)
------非阻塞的同步
------CAS(V,E,N)v表示要更新的变量,E对V的一种期望值,N就是新的值
------把新值N赋值给V,但是不是无条件的,当且仅当,V=E的时候
--在应用层面判断多线程的干扰,如果有干扰,则通知线程重试

这里简单介绍一下CAS,通过AtomicInteger说明
private volatile int value;
//此处省略一万字代码
/**
* Atomically sets to the given value and returns the old value.
* @param newValue the new value
* @return the previous value
*/
public final int getAndSet(int newValue) {
for (;;) {
int current = get();
if (compareAndSet(current, newValue))
return current;
}
}
/**
* Atomically sets the value to the given updated value
* if the current value {@code ==} the expected value.
* @param expect the expected value
* @param update the new value
* @return true if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}从这段代码可知,AtomicInteger中真正存储数据的是value变量,而value是被volatile修饰的,保证了线程的直接可见性
getAndSet方法通过一个死循环不断尝试复制操作,而真正复制操作交给了unsafe类实现,AtomicInteger的getAndSet调用了unsafe类的 unsafe.compareAndSwapInt(this, valueOffset, expect, update);,这个函数表明,如果expect与valueOffset的值一致,九江update赋值给valueOffset,而valueOffset的含义如下
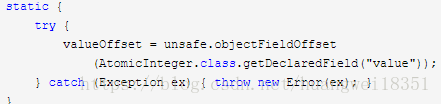
value存的是当前值,而当前值存放的内存地址可以通过valueOffset来确定,实际上是value字段相对于java对象的起始地址的偏移量。即CAS方法通过对比“valueOffset上的value”与expect是否相同,来决定是否修改value值为update值
既然是这样,虽然CAS是原子性操作,但是也不代表不会出问题,就是概率不太大
下面介绍CAS引起的ABA问题
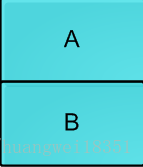
有一个单链表实现的堆栈,栈顶为A,线程1已知A.next=B,然后希望CAS将栈顶替换为B;
head.compareAndSet(A,B);
在线程1执行上面的指令之前,线程2介入,将A,B出栈,然后在pushD,C,A,,此时结构如下
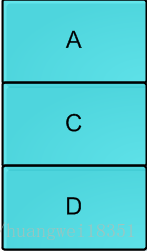
此时,线程1执行CAS操作,检测时仍然发现栈顶为A,所以CAS成功,栈顶变为B,但实际上B.next为null,此时情况变为
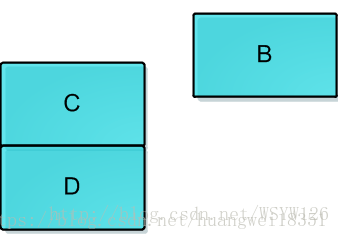
其中堆栈中只有B一个元素,C和D组成的链表已经不在堆栈中,平白无故把C,D丢了