大家好,我是隔壁小王,上次给大家讲了简单易懂的selenium,完全模拟人的行为来爬取网站的方法,但是巨慢,那这次就说一下爬虫必学的经典:scrapy。
可能你会问,为什么scrapy资料这么多,这么成熟,还要费事去说一下呢?我希望我的帖子是通过一个完整的项目可以让一个新手快速了解掌握这个框架,唯一的要求,就是你会python的基本语法。
ok,废话不多说。所谓代码未动,需求先行:爬取某个微博用户的所有微博内容,同时顺便把每个微博的评论都爬了(教一下怎么爬取多层的数据)。目前在网上有不少爬微博的demo,但是相关文档中为了实现自动登录加入比较复杂的抓包分析,并不利于新手快速上手一个需要登录的网站爬取,所以,就以微博为例做个示例。
在制作工程前,如果你有时间可以把scrapy的官方文档阅读一下:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html,写的简单明了便于后面的理解,当然没空读也没关系。
安装
scrapy也是个python库,用pip安装一下。
创建一个工程
scrapy的项目操作最好都用指令,这样一能熟练指令,二不用在意平台。
scrapy startproject xxx:创建一个叫xxx的工程。
创建完工程后,你会发现里面有如下文件:

1.spiders
这个文件夹是用来保存爬虫文件的,也就是具体的爬虫逻辑会存在这里。
2.items.py
这个文件是定义scrapy中一个特有的数据类型item的,这是一个类字典的数据类型,用来存储爬取下来的内容。
3.pipelines.py
中文名叫管道,用法很简单,就是把item中的数据写到本地的文件中。
4.middlewares.py
这是在python框架中非常常见的模块,叫中间件,如果在这里写了中间件的类和方法,并在settings中开启了,就可以在执行爬虫的前后对request或者response进行一些特定的处理。
5.settings
设置文件。
6.scrapy.cfg
配置文件,例如你项目有多个settings,你可以根据不同的场景在这里指定使用哪个settings等。
That's all!
创建一个spider
scrapy genspider 爬虫名 目标网站域名
这样,你就会发现在spiders这个文件夹中会出现你刚刚生成的一个spider文件,我用sinaweibo命名。点开瞅一眼,里面是这样的:
# -*- coding: utf-8 -*- import scrapy class SinaweiboSpider(scrapy.Spider): name = 'sinaweibo' allowed_domains = ['weibo.com'] start_urls = ['http://weibo.com/'] def parse(self, response): pass
name:每个爬虫类的唯一标识。
allowed_domains:填入的域名,表示允许爬虫访问的网站。这行是可以注释掉的,其实没啥卵用,删掉一点影响也没。
start_urls:包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。但是,我更倾向于删了这个,自己重写函数start_requests这个方法,那样会方便配置cookie,headers等。
parse:爬虫的具体实现方法。
定义我们需要的item
从这里开始,就是需要准备代码部分了。在开始编写爬虫之前,首先需要想好爬下来的数据以怎样一种数据结构来展示,这就是item的作用了。以微博为例,假设我要爬取某人的微博,那么我大概需要如下几点:1.博主url;2.微博的内容;3.点赞人数;4.转发人数;5.评论人数;6.微博日期;7.该微博对应的所有评论。代码如下:
class WeiboItem(scrapy.Item): # define the fields for your item here like: user = scrapy.Field() content = scrapy.Field() support_number = scrapy.Field() transpond_number = scrapy.Field() comment_number = scrapy.Field() date = scrapy.Field() observer = scrapy.Field()
设置settings
在编写代码前,最好把settings中的某些变量设置一下,首先是USER_AGENT,这样使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。如果不设置,很容易导致服务器将你判断为爬虫程序从而拒绝访问。当然,如果你需要大量访问,强烈建议设置随机的user agent,这样会安全一点,方法呢可以看一下这篇帖子:https://www.cnblogs.com/cnkai/p/7401343.html。
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
接下来是ROBOTSTXT_OBEY,默认是True的,这代表爬虫遵循某些特性的协议,会选择性的爬取内容,建议改成False。
然后你需要知道的是DOWNLOAD_DELAY这个变量,这是控制爬虫下载时间的变量,控制对服务器短时间内的访问频率也是很重要的,激烈的访问很容易暴露自己是个爬虫。
编写代码
这里创建一个叫weibo的爬虫文件。
1.类名叫‘WeiboSpider’,name叫‘weibo’。
2.配置cookie和headers,这两个名字大家应该是熟悉的,如果不是很清楚可以百度下。微博是一种需要用户验证的网站,所以说cookie和headers是一定要配置的。获取这两个方法很简单,打开chrome,按下F12,输入网址:weibo.cn,然后登陆你的微博账号。选中浏览器工具栏中的network,这时候你会在右边的工具栏中发现如下的条目:
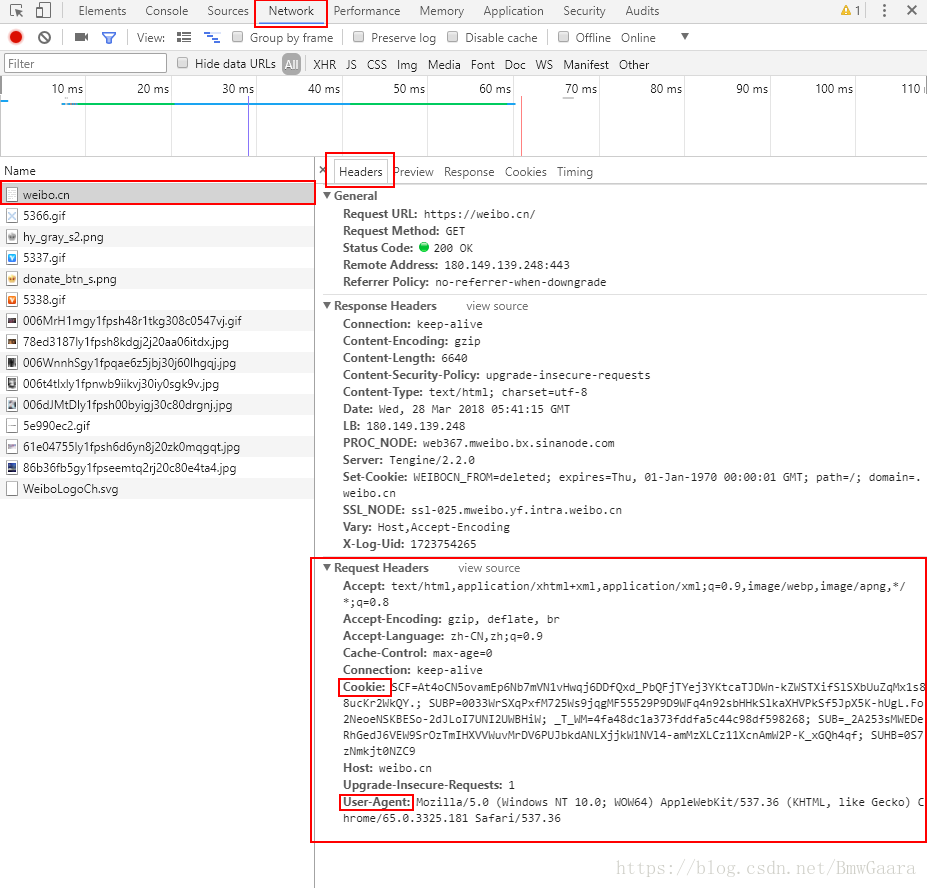
cookie是什么就显而易见啦,但是这里的cookie是字符串的形式,注意要转成字典的形式,至于headers就直接转成字典的形式拿来用就可以了。代码如下:
self.cookie = { 'SCF': 'xxxxxxxx', 'SUB': 'xxxxxxxx', 'SUBP': 'xxxxxxxx', '_T_WM': 'xxxxxxxx', 'SUHB': 'xxxxxxxx', 'SSOLoginState': 'xxxxxxx' } self.header = { 'Referer': 'https://weibo.cn/' }
我筛选了一些必须要用的,当然你把浏览器里的信息全部荡下来也是没有问题的,为了个人信息安全,我的cookie这里就隐去了。这两个信息我保存在了WeiboSpider的__init__方法中。
接下来,构建爬取首个网址的初始函数start_requests,函数名必须是这个,因为这是从基类里继承的,爬虫没有检测到start_urls这个列表时,会自动去执行这个函数。
def start_requests(self): return [Request('https://weibo.cn/xxxxx', callback=self.parse, cookies=self.cookie, headers=self.header)]这样,每当启动爬虫的时候,就会默认从这个网址开始请求,这里的callback,指的是爬虫向该网址发起请求后,获取的response将作为参数传递给parse函数,作下一步的执行操作。为啥这里爬取的是weibo.cn,因为weibo.com是pc版的,反扒机制健全,网页也复杂很多,从性价比的角度讲,weibo.cn是最优的。
ok,接下来编写主体部分,首先定义weibo_item对象,接下来获取一个选择器对象,选择器对象是用来将网页内容进行过滤的工具,将response传入到selector后,可以通过xpath、css、re等获取你需要的网页中的信息,至于其他的方法用到的时候再进行解释。我以下的所有的过滤方法都是使用xpath的,xpath获取的方法和含义可以百度下,也可以看下我另外一篇描述selenium的博客,其中有对xpath的介绍。
weibo_item = WeiboItem() selector = Selector(response) wbs = selector.xpath("//div[@class='c']") # get all elements which class name is 'c' weibo_item['user'] = response.url这样,所有的类名为c的网页元素就获取到了,因为所有的微博信息在网页中都保存在class=c这样一个对象中,所以这个wbs中就是网页上所有微博消息的集合,每一个元素都表示一个微博消息。接下来对每个微博消息体进行遍历,利用xpath将需要的信息过滤出来。以下是代码部分:
for i in range(len(wbs) - 2): comment_href = '' divs = wbs[i].xpath('./div') weibo_item['observer'] = [] weibo_item['content'] = divs[0].xpath('./span[@class="ctt"]/text()').extract()[0] if len(divs) == 1: a = divs[0].xpath('./a') if len(a) > 0: for j in range(len(a)): weibo_item['support_number'] = a[-4].xpath('./text()').extract()[0] weibo_item['transpond_number'] = a[-3].xpath('./text()').extract()[0] weibo_item['comment_number'] = a[-2].xpath('./text()').extract()[0] comment_href = a[-2].xpath('./@href').extract()[0] weibo_item['date'] = divs[0].xpath('./span[@class="ct"]/text()').extract()[0] if len(divs) == 2: a = divs[1].xpath('./a') if len(a) > 0: for j in range(len(a)): weibo_item['support_number'] = a[-4].xpath('./text()').extract()[0] weibo_item['transpond_number'] = a[-3].xpath('./text()').extract()[0] weibo_item['comment_number'] = a[-2].xpath('./text()').extract()[0] comment_href = a[-2].xpath('./@href').extract()[0] weibo_item['date'] = divs[1].xpath('./span[@class="ct"]/text()').extract()[0] yield Request(comment_href, meta={'item': weibo_item}, callback=self.parse_comment)
为什么len(wbs)需要减去2呢?因为在每一个网页中,分析后发现最后两个类名为c的网页元素并不是微博信息,所以要排除掉。不管用什么方法来编写爬虫,分析网页是必不可少的一步,具体过程可以看我写的关于selenium的博客。extract()方法是用来将网页信息序列化的,但是因为xpath得出的结果是一个list,所以要加上[0]来定位下信息。
observer是用来保存每个微博里的所有评论的列表。
但是此时我们得出的仅仅是第一层的网页,如果需要爬取每个微博的评论信息,就需要进入到下一层的网页中。通过获取“评论”按钮所链接的url,来构建跳转到下一层网址的请求地址,同时将weibo_item作为参数加入到meta中,传递到下一层的爬虫中,便于将爬取的消息记录到这个item中,最后设置具体的回调函数为:parse_comment。
当然这个方法至此并没有结束,一个博主可能有多条微博,那就可能有很多的页数,所以要判断下是否有下一页,如果有下一页就继续执行本函数:
if selector.xpath('//*[@id="pagelist"]/form/div/a/text()').extract()[0] == u'下页': next_href = selector.xpath('//*[@id="pagelist"]/form/div/a/@href').extract()[0] yield Request('https://weibo.cn' + next_href, callback=self.parse)
下面看一下parse_comment的内容,实现的逻辑和具体方案与上述基本一致:
def parse_comment(self, response): observer_item = Fan() selector = Selector(response) weibo_item = response.meta['item'] comment_list = [] comment_records = selector.xpath('//div[@class="c"]') for comment_record in comment_records[3:-1]: observer_item['user'] = comment_record.xpath('./a[1]/text()').extract()[0] try: observer_item['content'] = comment_record.xpath('./span[@class="ctt"]').extract()[0] except Exception: observer_item['content'] = '' comment_list.append(dict(observer_item)) weibo_item['observer'].extend(comment_list) if selector.xpath('//*[@id="pagelist"]/form/div/a/text()').extract()[0] == u'下页': next_href = selector.xpath('//*[@id="pagelist"]/form/div/a/@href').extract()[0] yield Request('https://weibo.cn' + next_href, meta={'item': weibo_item}, callback=self.parse_comment) else: yield weibo_item
你会发现这里多出个一个叫Fan的类型,这是用来保存评论的item,具有评论人和评论内容两个成员,具体定义添加在items.py中,结构非常简单:
class Fan(scrapy.Item):
user = scrapy.Field()
content = scrapy.Field()
至此,基本的代码逻辑就完成了,这里没有讲的很细,但是如果你知道xpath的用法,应该是很容易理解的。所以就不多加赘述了。那么如果想要把yield出来的item保存到文件中该怎么办呢?那就要用到pipelines了,在scrapy中,管道的作用就是这个。首先要定义一个管道:
class WeiboPipeline(object): def __init__(self): self.f = open('result.txt', 'a+') def process_item(self, item, spider): line = json.dumps(dict(item)) + '\n' self.f.write(line) return item def close_spider(self, spider): self.f.close()
这是个非常简单的文件读写功能,这是一种自定义的方法,你还可以使用scrapy专门提供的文件读写接口来实现。但是,仅仅是定了管道并不能启动该功能,还需要在settings里面开启管道:
ITEM_PIPELINES = {
'weibo.pipelines.WeiboPipeline': 300,
}
300表示在使用多个管道时执行的优先级,只有一个的时候是无所谓的。
这样每当你yield一个item时,管道都会将对应的值写入到本地文件中。
最后再补充一点,如果你需要在爬虫执行前后加一些固定的功能,就可以考虑启动中间件,例如使用代理就是中间件的一种实现方法。相关的知识可以再去百度下。
最后运行爬虫:scrapy crawl weibo(weibo是爬虫类中的name) 给大家看下爬虫的结果:

这都是unicode编码格式的微博结果。
全部的详细代码可以参照我的github:https://github.com/whgaara/weibo.cn
谢谢您的阅读。