看完觉得深受启发的一篇文章,根据自己的理解翻译过来留以后再次翻看
原文地址http://neuro.cs.ut.ee/demystifying-deep-reinforcement-learning/
DQN
上回书咱们说到,当状态和动作很小时,我们可以用表结构来记录Q值。
再捡起我们的打砖块游戏,它的环境中的状态,可以被定义为平板位置,球的位置和方向,每个独立砖块的存在性。然而,这个直觉性的表示方法对于每个游戏都是不同的。我们是否可以提出一个更通用的适用于所有游戏的方法呢?很显然,我们可以选择屏幕像素,它们包含了关于游戏的所有相关信息,除了球的方向和速度,这通过屏幕两个连续的帧就同样可以获得。
如果我们要应用DeepMind在论文中提到的对于屏幕预处理的方法——获取我们屏幕最后的信息,挑战尺寸为84*84并且转换为256灰度级——我们将会有256×84×84×4≈1067970 种可能的游戏状态。这太多了,Q表装不下了,整个宇宙的已知原子数目也没那么多!也许有人争辩说许多状态永远不可能出现,我们可以将它视为分散表结构仅包含已经发生过的状态。即便如此,想要遍历训练这个表可能会花费很长很长的时间。我们有更理想的方法,就是我们并不是全覆盖,而是对于从未访问过的状态依然有一个关于Q值的好的猜想。
神经网络特别擅长于在高层结构数据中获得更好的特征。我们可以将神经网络作为我们的Q函数,输入状态(屏幕像素)和行动,输出相应的Q值。或者我们仅输入状态,神经网络输出每个可能行动的Q值。这个方法自有其优点,就是如果我们想要获得一个Q值或者选择一个高Q值行动,我们只需要输入一次状态,前向传播通过神经网络并且立刻获得所有行动的Q值。

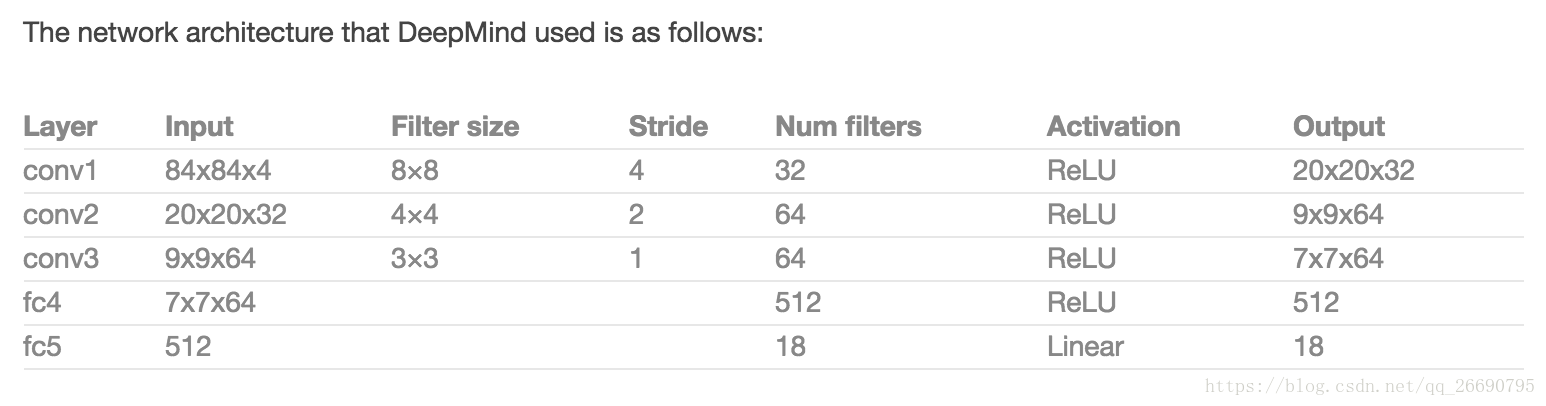
上图右是DeepMind在论文中提出的网络结构。这是一个经典的卷积神经网络(CNN),包含3个卷积层和两个全连接层。对于图像识别网络很熟悉的小伙伴可能注意到这里没有池化层,但是如果你仔细的思考,你会知道原因的:池化会去掉部分信息,使得网络对于物体在图像中所在位置信息不敏感,这对于图像识别很有效,但是对于游戏来说可完全不是那么回事:比如打砖块游戏,球的位置信息非常非常重要哦,它决定了潜在奖励,我们肯定不想丢掉这些信息!
网络输入是4个84*84的灰度游戏屏幕,输出是每个可能行动的Q值。Q值可以是任意实数,这使它成为一个回归任务,可以用一个简单的差方作为损失函数。
已知转换<s,a,r,s′>,之前算法的Q表更新规则呗如下规则替代:
1.当前状态s作为输入值前向传播通过NN,获得所有动作的预测Q值
2.下一状态s’作为输入值前向传播通过NN,并取最大值
3.设置行动a的目标Q值为,对于所有其它行动,设置目标Q值与原来相同,使它们的误差为0
4.通过反向传播更新权重