零拷贝
本文图片和一些内容均来自后面的参考,非原创只是把文章中的一些关键内容整理一下,算作是一个学习笔记。
传统的I/O操作
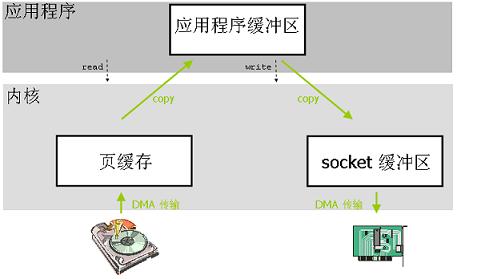
传统的IO操作是用户应用程序只是需要调用两个系统调用 read() 和 write() 就可以完成这个数据传输操作,但是底层会发生很多步骤,这些步骤对上层都是隐藏的。我们来梳理一下。
当应用程序需要访问某块数据的时候:
- 应用程序发起系统调用
read()读取文件(一次上下文切换,或者说是模式切换模式切换1,用户态切换到内核态) - 操作系统内核会先检查这块数据是不是已经被存放在操作系统内核地址空间的缓冲区内,如果存在就直接返回。如果不在就执行下一步。
- 如果在内核缓冲区中找不到这块数据(叫做缺页,会触发缺页异常),Linux 操作系统内核会先将这块数据从磁盘读出来放到操作系统内核的缓冲区里去(一次DMA2拷贝,硬盘到页缓存)
- 然后内核把这块数据拷贝到应用程序的地址空间中去(一次CPU拷贝,内核空间到用户空间)
read()函数返回。(一次上下文切换,或者说是模式切换,内核态切换到用户态)- 应用程序调用
write()函数向socket缓冲区写数据。(一次上下文切换,或者说是模式切换,用户态切换到内核态) - 内核需要将数据再一次从用户应用程序地址空间的缓冲区拷贝到与网络堆栈相关的内核缓冲区(一次CPU拷贝,内核空间内)
- 执行DMA拷贝,把内核的socket缓冲区数据通过DMA方式发送给物理网卡,在执行期间用户空间应用程序的
write()函数返回。(一次上下文切换,或者说是模式切换,内核态切换到用户态)
从上面过程来看,经过了4次上下文切换或者是模式切换,4次拷贝操作(2次DMA拷贝,2次CPU拷贝)。
为什么需要零拷贝
从上面过程来看,4次切换和4次拷贝,整个处理过程比较冗长,但这还不是问题,在网络速度比较慢的时代(56K猫、10/100MB以太网)其实不需要这种技术,因为内部再快也会被网络速率卡住,木桶效应。但是当网路速度大幅提升出现1Gb、10Gb甚至100Gb网速的时候这种零拷贝技术就迫切需要,因为网络传输速度已经远远大于计算机内部的数据流转速度。所以有必要提速,那么这时候人们就关注如何优化计算机内部数据流转。
零拷贝解决了什么问题
零拷贝技术的实现有很多种,但归根结底其目的是减少数据传输的中间环节,尤其是上述过程中的用户空间和内核空间的数据拷贝。
减少CPU拷贝的方法
直接I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存(page cache)。读取数据的时候先在缓冲中查找如果命中就直接返回,没有命中则去磁盘读取。其实这种机制是一种为了提高速度减少IO操作的良性机制,因为毕竟磁盘属于低速设备。
那么反过来在写数据的时候应用程序也是先写到页缓存,至于是否会立即同步到磁盘这取决于采用的写操作机制,到底是同步写还是异步写。同步写机制应用程序会立刻得到响应,而异步写则会稍晚些得到响应。当然还有另外一种机制就是延迟写入机制,不过延迟写入写到磁盘上的时候不会通知应用程序。
在直接I/O机制中,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,完全不需要页缓存的支持。这类零拷贝技术针对的是操作系统内核并不需要对数据进行直接处理的情况。在某些场景下会使用到这种方式。
Kafka就利用这种缓存I/O机制,写入缓存,读取的时候也从缓存读取,这样吞吐量非常高,但是数据丢失风险就会比较高,因为大量数据在内存中,不过参数可以调整。
mmap
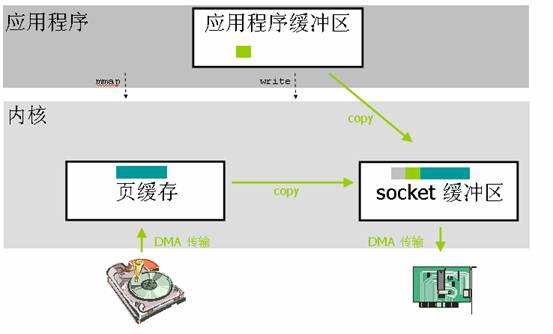
应用程序调用了mmap()之后,发生2次上下文切换(调用和返回)。数据拷贝除了2次DMA没有变化之外最主要的就是减少了一次内核到用户空间的数据拷贝,而是直接从页缓存拷贝到socke缓冲区,所以跟标准I/O比,就变成了2次上下文切换,2次DMA拷贝,1次CPU拷贝。这个优化就减少了中间环节。
但是对文件进行了内存映射,就是应用程序缓冲区和内核空间缓冲区都映射到同一地址范围的物理内存,你也可以说操作系统共享这个缓冲区给应用程序,而且映射操作也是一个开销很大的虚拟存储操作,这种操作需要通过更改页表以及冲刷 TLB (使得 TLB 的内容无效)来维持存储的一致性。不过这种刷新TLB的开销要比。
不过mmap有一个比较大的隐患就是,调用 write() 系统调用,如果此时其他的进程截断了这个文件,那么 write() 系统调用将会被总线错误信号 SIGBUS 中断,因为此时正在执行的是一个错误的存储访问。这个信号将会导致进程被杀死。
sendfile
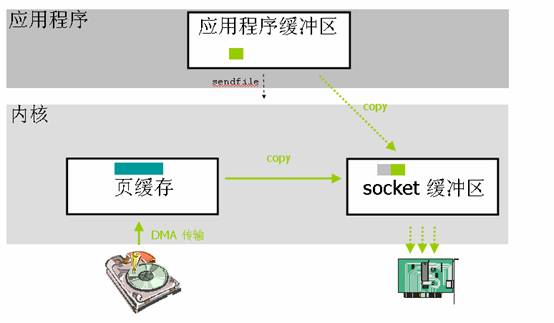
从上图可以看到应用程序调用sendfile()系统调用这里就只发生2次上下文切换(调用和返回)。数据拷贝除了2次DMA没有变化之外最主要的就是减少了一次内核到用户空间的数据拷贝,而是直接从页缓存拷贝到socke缓冲区,所以跟标准I/O比,就变成了2次上下文切换,2次DMA拷贝,1次CPU拷贝。这个优化就减少了中间环节,提高了内部传输效率也解放了CPU。不过这并不是零拷贝,因为还有1次CPU拷贝。
在高级语言中如何使用这种特性就需要去查看该语言的库函数,看看那些库函数底层调用的是
sendfile()系统调用。
带DMA的sendfile

这种方式就是为了解决sendfile中的那1次CPU拷贝,也就是内核缓冲区到socket缓冲区的拷贝。不拷贝的话该如何发送数据呢?就是将内核缓冲区中待发送数据的描述符发送到网络协议栈中,然后在socket缓冲区中建立数据包的结构,最后通过DMA的收集功能将所有的数据结合成一个网络数据包。网卡的 DMA 引擎会在一次操作中从多个位置读取包头和数据。Linux 2.4 版本中的 socket 缓冲区就可以满足这种条件,这也就是用于 Linux 中的众所周知的零拷贝技术。
- 首先,sendfile() 系统调用利用 DMA 引擎将文件内容拷贝到内核缓冲区去;
- 然后,将带有文件位置和长度信息的缓冲区描述符添加到 socket 缓冲区中去,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中;
- 最后,DMA 引擎会将数据直接从内核缓冲区拷贝到协议引擎中去,这样就避免了最后一次数据拷贝。
sendfile的局限性
首先,sendfile只适用于数据发送端;其次要发送的数据中间不能被修改而是原样发送的。