背景:循环结构是c语言中经常出现的内容。HLS会对数组作出具体的优化。
目的:目的,搞懂HLS对数组的操作。
UG902:HLS用户指南中数组的内容
目录
1. 数组
1.1 c仿真中的数组
在讨论coding style对数组的综合的影响之前,我们先讨论一下c仿真之前可能遇到的情况。
例如下面这段代码,一个非常大的数组,可能导致c仿真失败:
#include "ap_cint.h"
int i, acc;
// Use an arbitrary precision type
int32 la0[10000000], la1[10000000];
for (i=0 ; i < 10000000; i++) {
acc = acc + la0[i] + la1[i];
}仿真可能会失败,running out of memory,因为array会存储在stack中,而不是heap中。heap由OS分配在local disk并且可以grow。下面为可能出现的问题:
- 在PC端,available memory经常比large linux boxes少
- 运用arbitrary precision types可能会加剧这个问题,因为它比c standard types需要更多的memory
- 运用更复杂的fixed-point arbitrary precision types在c++或者system C可能需要更多的memory
一个解决的方法是用dynamic memory allocation用于仿真,例如下面的例子就是运用memory被OS分配于heap中。但是这种变化并不理想,因为code的仿真和code的综合会变得不一样,而好处是相应的设计可以继续推进。
#include "ap_cint.h"
int i, acc;
#ifdef __SYNTHESIS__
// Use an arbitrary precision type & array for synthesis
int32 la0[10000000], la1[10000000];
#else
// Use an arbitrary precision type & dynamic memory for simulation
int32 *la0 = malloc(10000000 * sizeof(int32));
int32 *la1 = malloc(10000000 * sizeof(int32));
#endif
for (i=0 ; i < 10000000; i++) {
acc = acc + la0[i] + la1[i];
}1.2 数组的实现
数组通常会被综合为memory(RAM,ROM,或者FIFO)。
- Top-level function中的数组会被综合为RTL ports,与外部的memory进行access。这个在数组的接口中会讨论。
- 内部的数组会被综合为RAM,LUTRAM,UltraRAM或者register,取决于optimization settings
与loops一样,数组可以在代码中加入指令性的代码。同样,vivado HLS可以对相应的数组进行相应的RTL优化。
1.3 可能出现的问题
在RTL实现时,数组可能出现:
- 数组的接口通常是性能的瓶颈,因为array实现在memory中时,memory ports的数量限制着获得数据的速率。
- 数组的初始化,如果不正确的话,可能会导致很长的reset和RTL的初始化时间。
- 要小心确保只读格式的数组被实现在ROM中
- 数组必须有大小,例如array[10],array[]格式是不支持的
HLS会支持数组的指针实现。见指针操作。每一个指针只能指向一个标量或者数组的标量。
2. 数组的接入与性能
下面的代码显示了在最终的RTL设计之中,数组可能是性能的瓶颈。例如下面的代码中,有三个接入来获取数组mem[N] : mem[i], mem[i-1], mem[i-2]
#include "array_mem_bottleneck.h"
dout_t array_mem_bottleneck(din_t mem[N]) {
dout_t sum=0;
int i;
SUM_LOOP:for(i=2;i<N;++i)
sum += mem[i] + mem[i-1] + mem[i-2];
return sum;
}在综合中,数组被实现RAM中,如果RAM被定义为单个管脚(single port)的RAM,则不可能对SUM_LOOP进行pipeline。如果对SUM_LOOP进行initiation iterval为1的pipeline,则HLS会出现下面报错:

原因在于单个管脚(single port)的RAM在一个时钟周期之中只能支持一个读,或者一个写操作
- SUM_LOOP Cycle1: read mem[i];
- SUM_LOOP Cycle2: read mem[i-1], sum values;
- SUM_LOOP Cycle3: read mem[i-2], sum values;
运用两个管脚(dual port)的RAM可以被用于这个地方,但是每个时钟周期之中只能运用两个接入。但是代码中运算sum的时候需要用三个接入。把上面代码改为下面这样可以获得更好的性能。通过预读取和手动对数据接入进行pipeline,在每个loop中只需要一次数据读取,这样就确保了获得更好的性能。(每个循环中只读取一次,然后读取的时候把相应的数组存于局部变量。但是我们发现了一个问题,在这个循环之中,上一次循环的结果会影响下一次sum的值。不过我们理解的是pipeline是流水线,并行运算是unroll,所以可以进行pipeline进行加速。)
#include "array_mem_perform.h"
dout_t array_mem_perform(din_t mem[N]) {
din_t tmp0, tmp1, tmp2;
dout_t sum=0;
int i;
tmp0 = mem[0];
tmp1 = mem[1];
SUM_LOOP:for (i = 2; i < N; i++) {
tmp2 = mem[i];
sum += tmp2 + tmp1 + tmp0;
tmp0 = tmp1;
tmp1 = tmp2;
}
return sum;
}vivado HLS包括了针对数组的优化指令,这些指令包括了数组如何实现和接入。数组会被分为相应的块(block)或者单个的元素。
- 当一个数组被分为多个块时,单个的数组会被分为多个RTL RAM block
- 当一个数组被分为多个元素时,每个元素被在RTL中是一个寄存器(register)
这两种情况下,分组可以使更多的数组元素被接入循环结构的并行,从而改善性能。
3. FIFO接入
一个数组序列可以被应用于FIFO中。这种情况多为运用dataflow优化指令的时候。
接入FIFO需要是一个序列结构,并且是从位置0开始。并且,如果一个数组在多个位置被读入,代码必须严格的按照FIFO的顺序来执行。通常情况下,一个数组有多个分列(fanout)的时候,不能被应用于FIFO上。
4. 数组的接口
vivado HLS将数组作为memory元素。但当数组作为top-level函数接口的时候,vivado HLS会做出如下:
- memory是在芯片之外(off-chip),HLS会将其综合为memory接口
- memroy是latency为1的标准block RAM,当地址确定时,数据会在1个时钟周期之后获得
vivado如何获得这些接口和管脚(ports):
- INTERFACE指令:将其具体化为RAM或者FIFO接口
- RESOURCE指令:将其具体化为单个或者双管脚(single or dual-port) RAM
- RESOURCE指令:能具体化RAM的latency
- array_partitation, array_map, array_reshape指令:将其具体化为相应的结构和IO口的数量
这些数组数据的接入需要RAM或者FIFO,数组的接口接入会影响相应的性能瓶颈,通过相应的指令可以优化这些瓶颈。数组在进行指令优化时必须确定相应的结构。例如运用d[],的时候,HLS就会出现下面的报错:

4.1 数组接口
相应的指令可以具体化哪一种RAM被用于数组,并且确定哪一种RAM端口被创建(sigle-port或者dual-port),如果没有具体的指令,HLS会进行:
- 默认为Single port RAM
- 减少initiation interval或者减少latency时运用dual-port
partitation,map,reshape指令会重新确定数组的接口。数组可以被分成很多个小的数组,每个数组都有其接口。还可以将所有的数组元素分为具体的单个的标量元素。同样的,小的数组可以被合并为大的数组。
//Example 3-17: RAM Interface
#include "array_RAM.h"
void array_RAM (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) {
int i;
For_Loop: for (i=0;i<4;i++) {
d_o[i] = d_i[idx[i]];
}
}
上面这个代码,相应的RAM会被实现为单个管脚的RAM,因为for循环里面只有一个数组元素的接入。运用双管脚的RAM并没有作用。如果for循环被unroll,则HLS就会运用双管脚的RAM,这样可以改善相应的initiation interval。RAM接口的类型可以被具体的指令确定。数组接口的类型会直接与吞吐量挂钩。
我们可以运用RESOURCE指令对具体的RAM的latency进行规定,这要求HLS运行额外的SRAMs,这种SRAMs时延小于1.
4.2 FIFO接口
HLS允许将数组元素实现在FIFO端口之中。如果FIFO端口被用到,就需要确保数组的接入和读出是成序列的。
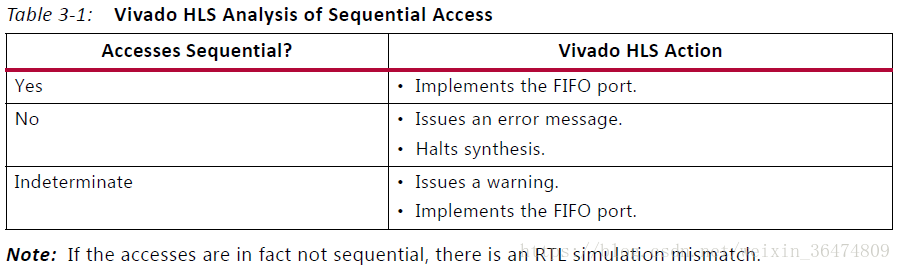
如果数组的接入不是按顺序的,RTL simulation就会报错。下面的代码就展示了一个情况,HLS不能确定数组的接入是否为按顺序的,d_i与d_o在综合中会被具体化为FIFO接口
#include "array_FIFO.h"
void array_FIFO (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) {
#pragma HLS INTERFACE ap_fifo port=d_i
#pragma HLS INTERFACE ap_fifo port=d_o
int i;
// Breaks FIFO interface d_o[3] = d_i[2];
For_Loop: for (i=0;i<4;i++) {
d_o[i] = d_i[idx[i]];
}是否能够作为FIFO接口,取决于idx数组是否为序列的。HLS进行综合时就会有下面的信息:

如果把//break FIFO interface这个指令去掉注释,则HLS就能决定数组的接入是非序列的,然后在FIFO的接口确定的时候就会报错。FIFO必须遵循下面的原则:
- 数组必须在一个循环或者函数中被写或者被读,并且是端到端的连接。
- 数组的读取必须与数组的写入相同的顺序,因为随机接入(random access)是对于FIFO不支持的。数组必须遵循先进先出的准则。
- 用于读和写数组的参数必须在编译的时候就被分析,数组的地址基于时间的变化如果不能被分析出,则HLS不会将其作为FIFO
大多数情况下,数组作为top-level的接口的时候不需要对代码进行更改。代码需要更改的时候可能是数组作为一个数组作为结构体一部分的时候。
5. 数组初始化
在Type qualifiers之中,xilinx推荐将数组实现为memories with the static qualifier。
int coeff[8] = {-2, 8, -4, 10, 14, 10, -4, 8, -2};上面这个数组的实现过程中,综合后,数组被实现为这些值,单端口RAM被用于实现数组,需要8个时钟周期。对于1024的数组来说,需要1024个时钟周期,并且在这段时间之中,不能对coeff进行操作。
static int coeff[8] = {-2, 8, -4, 10, 14, 10, -4, 8, -2};运用static指令的时候,数字被初始化为具体的值。并且HLS直接将该数组初始化为RTL的值烧入FPGA的比特流,这避免了初始化数组的多个时钟周期。
6. ROM实现
HLS将数组具体化,用static指令将其综合为memory,用const指令将其综合为ROM。HLS会分析整个设计并且将琦创建为最优的硬件设计。
6.1 c++中const与static的区别
6.1.1 const
定义的常量在超出其作用域之后其空间会被释放。在C++中,const成员变量也不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。const数据成员 只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类的声明中初始化const数据成员,因为类的对象没被创建时,编译器不知道const数据成员的值是什么。const数据成员的初始化只能在类的构造函数的初始化列表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现,或者static cosnt。
6.1.2 static
定义的静态常量在函数执行后不会释放其存储空间。在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化,如:double Account::Rate=2.25; static关键字只能用于类定义体内部的声明中,定义时不能标示为static.static表示的是静态的。类的静态成员函数、静态成员变量是和类相关的,而不是和类的具体对象相关的。即使没有具体对象,也能调用类的静态成员函数和成员变量。一般类的静态函数几乎就是一个全局函数,只不过它的作用域限于包含它的文件中
6.2 ROM实现
const 关键字会将数组确定为只读格式,然后实现在ROM之中。ROM是一个local,static(non-global)的数组。下面有一些实用的建议:
- 数组越早初始化越好
- 将写操作集成在一起
- 不要将数组(ROM)的初始化插入写过程,就是不要讲non-initialization code插入此过程
- 不要讲不同的值存在同一个数组之中
- 数组的值的运算必须是定值的(编译的时候)
如果复杂的初始化被用于初始化ROM,例如运用到math.h中的函数,HLS也会将其RTL初始化为ROM,例如下面:
#include "array_ROM_math_init.h"
#include <math.h>
void init_sin_table(din1_t sin_table[256]){
int i;
for (i = 0; i < 256; i++) {
dint_t real_val = sin(M_PI * (dint_t)(i - 128) / 256.0);
sin_table[i] = (din1_t)(32768.0 * real_val);
}
}
dout_t array_ROM_math_init(din1_t inval, din2_t idx){
short sin_table[256];
init_sin_table(sin_table);
return (int)inval * (int)sin_table[idx];
}