1.前言
浏览器工作原理的实质就是实现http协议的通讯,具体过程如下:(HTTP通信的流程,大体分为三个阶段)
- 连接,服务器通过一个ServerSocket类对象对某端口进行监听,监听都之后进行连接,打开一个socket虚拟文件。
- 请求,创建与监理socket连接相关的流对象后,浏览器获取请求,为get请求,则从请求信息中获取所访问的html文件名,向服务器发送请求。
- 响应,服务器收到请求后,搜索相关的目录文件,若不存在,返回错误的信息。若存在,则读取html文件,进行加http头等处理响应给浏览器,浏览器解析html文件,若其中还包含图片,视频等资源,则浏览器再次访问web服务器,获取图片视频等,并对其进行组装显示给用户。
2.目前流行的浏览器
目前使用的主流浏览器有:IE,Firefox,Safari,Chrome,Opera.浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源。这里所说的资源一般是指 HTML 文档,也可以是 PDF、图片或其他的类型。资源的位置由用户使用 URI(统一资源标示符)指定。浏览器解释并显示 HTML 文件的方式是在 HTML 和 CSS 规范中指定的。这些规范由网络标准化组织 W3C(万维网联盟)进行维护。
浏览器的用户界面有很多彼此相同的元素,其中包括:
- 用来输入 URI 的地址栏
- 前进和后退按钮
- 书签设置选项
- 用于刷新和停止加载当前文档的刷新和停止按钮
- 用于返回主页的主页按钮
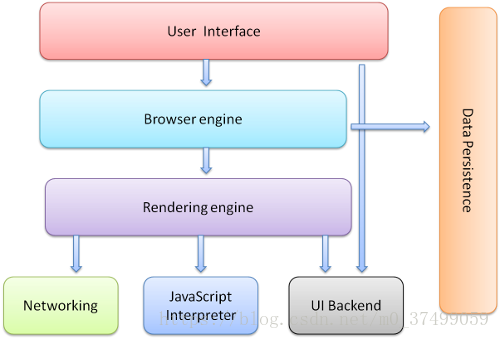
3.浏览器的高层结构
1)用户界面-地址栏,前进、后退,书签菜单。
2)浏览器引擎-在用户接和呈现引擎之间传送指令。
3)呈现引擎-显示请求的内容。
4)网络-网络调用,如http请求。
5)用户界面后端-绘制基本窗口小部件。
6)JavaScript解析器-解析和执行js代码。
7)数据存储-持久层,把需要的数据保存在硬盘上,如cookie.
那这里不得不说呈现引擎了:
当然是呈现的作用,Firefox使用的是Gecko,Safari和Chrome浏览器使用的是WebKit(看法源代码).
我们来看一下Webkit引擎的流程图:
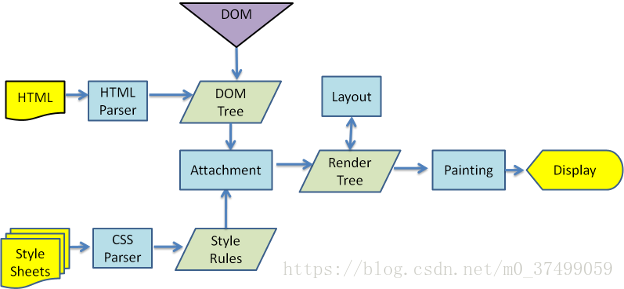
1. 呈现引擎一开始会从网络层获取请求文档的内容,内容的大小一般限制在 8000 个块以内。
2. 呈现引擎将开始解析 HTML 文档,并将各标记逐个转化成“内容树”上的 DOM 节点。同时也会解析外部 CSS 文件以及样式元素中的样式数据。HTML 中这些带有视觉指令的样式信息将用于创建另一个树结构:呈现树。呈现树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。
3. 呈现树构建完毕之后,进入“布局”处理阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标。下一个阶段是绘制 - 呈现引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来。
需要着重指出的是,这是一个渐进的过程。为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
解析
那呈现前肯定要有个解析的过程,我们来分析一下:
解析文档是指将文档转化成为有意义的结构,也就是可让代码理解和使用的结构。解析得到的结果通常是代表了文档结构的节点树,它称作解析树或者语法树。
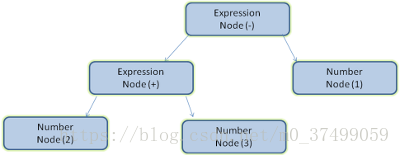
示例 - 解析 2 + 3 - 1 这个表达式,会返回下面的树:
这里了解一下就好,解析:词法分析-语法分析
解析是一个迭代的过程。通常,解析器会向词法分析器请求一个新标记,并尝试将其与某条语法规则进行匹配。如果发现了匹配规则,解析器会将一个对应于该标记的节点添加到解析树中,然后继续请求下一个标记。如果没有规则可以匹配,解析器就会将标记存储到内部,并继续请求标记,直至找到可与所有内部存储的标记匹配的规则。如果找不到任何匹配规则,解析器就会引发一个异常。这意味着文档无效,包含语法错误。