上一篇文章(HashMap原理浅析)讲解了HashMap的基本原理。这篇文章我们来看一下支持高并发的ConcurrentHashMap。
HashMap是线程不安全的,在高并发场景下做插入操作没有可能出现环形链表(具体原理太过烧脑,这里不做分析)。
想要避免HashMap 的线程安全问题,可以使用Collections.synchronized(map)方法进行同步化,但是性能比较低下。无论读操作还是写操作,这个方法都会给整个集合加锁(将所有对容器状态的访问都串行化了),以保证线程的安全性,但这样做的代价就是严重降低了并发性,当多个线程竞争时,吞度量严重降低(实际上HashTable也是这样)。
所以便有了兼顾安全性与性能的ConcurrentHashMap。ConcurrentHashMap可以做到读取数据不加锁,写操作的时候能够将加锁的粒度保持尽量小,不会对整个ConcurrentHashMap加锁。
ConcurrentHashMap为了提高自身并发能力,内部采用了一个叫做的Segment的结构,一个Segment其实就是一个类似HashMap的结构,他包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。下图是整个ConcurrentHashMap的结构:
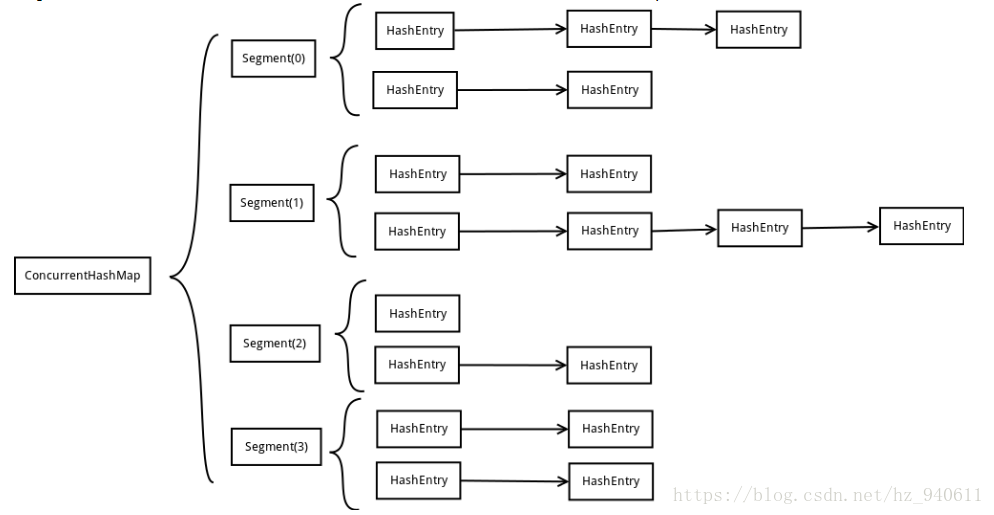
可以说,ConcurrentHashMap是一个二级哈希表。在一个总得哈希表下面,有若干个子哈希表。这样的二级结构,和数据库的水平拆分有些相似。ConcurrentHashMap优势就是采用了“锁分段技术”,每一个Sgement就好比一个自治区,读写操作高度自治,Segment之间互不影响。
- 不同Segment的写入是可以并发执行的;
- 同一Segment的读和写是可以并发执行的;
- 同一Segment的并发写入会阻塞(Segmrnt写入会上锁)
ConcurrentHashMap中每一Segment各自持有一把锁。在保证线程安全的同时降低锁的粒度,并发操作效率更高。
ConcurrentHashMap定位一个元素需要进行两次Hash操作。第一次Hash定位到Segment,第二次Hash在Segment内部定位到链表的头部,因此这样的副作用是Hash的过程比普通的HashMap长,但是好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment。所以,在最理想的情况下,ConcurrentHashMap可以最高支持Segmeent数量大小的写操作(刚好这些写操作平均分布在所有的Segment上)。通过这样一种结果,ConcurrentHashMap的并发能力可以大大提高。
参考文章: