概述: ConcurrentHashMap相对于HashMap的性能较差一些,但相比于Hashtable而言性能要高很多,因为Hashtable内部的所有方法都是同步方法,加了synchronized锁,所以性能上比较差,但在多线程环境下是具有很强的安全性的
ConcurrentHashMap避免了对全局加锁改成了局部加锁操作,这样就极大地提高了并发环境下的操作速度.
jdk1.7与jdk1.8的ConcurrentHashMap底层实现又有所不同,当然它们都有共同的一个特点就是键和值不能为null, 因为在并发的环境下, 通过get(key)的时候,你不知道是因为key为null而返回的null还是之前put进去的值为null.
jdk1.7的ConcurrentHashMap
在JDK1.7中ConcurrentHashMap采用了HashEntry+Segment+分段锁的方式实现。
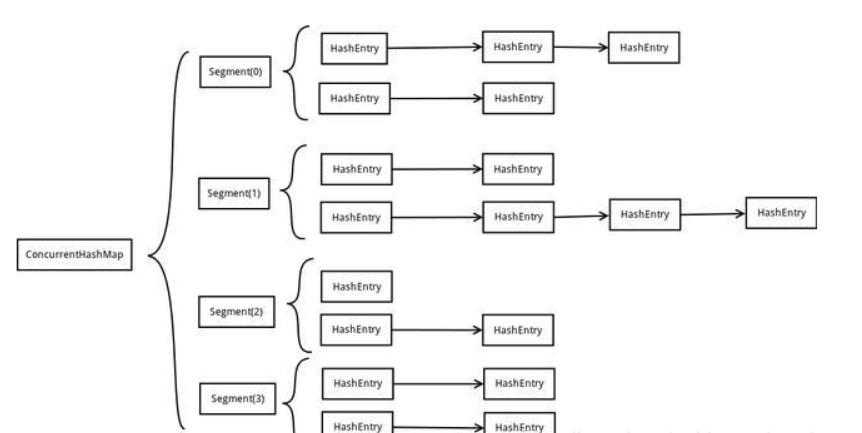
Segment是一种可重入锁(ReentrantLock),HashEntry数组用于存储键值对数据,数组中的每个元素又是一个链表.
如上图, 将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问
ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。
第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
优点:
写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上).
缺点:
hash操作的过程要比hashmap和jdk1.8的ConcurrentHashMap的过程要长,还加入多个分段锁浪费内存空间, 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
jdk1.8的ConcurrentHashMap
在jdk1.8的ConcurrentHashMap采用了HashEntry+红黑树+cas+synchronized的方式实现.
jdk8 放弃了分段锁而是用了 Node 锁,减低锁的粒度,提高性能,并使用 CAS操作来确保 Node 的一些操作的原子性,取代了锁。put 时首先通过 hash 找到对应链表过后,查看是否是第一个 Node,如是,直接用 cas 原则插入,无需加锁。然后, 如果不是链表第一个 Node, 则直接用链表第一个 Node 加锁,这里加的锁是 synchronized。
Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。

其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,相对于JDK1.7来说所粒度更细.