Requests:是使用 Apache2 Licensed 许可证的 基于Python开发的HTTP 库,其在Python内置模块的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作。
BeautifulSoup:是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查找指定元素,从而使得在HTML或XML中查找指定元素变得简单。
一:安装模块
pip3 install requests
pip3 install beautifulsoup4
二:requests和beautifulsoup4模块的简单联合使用
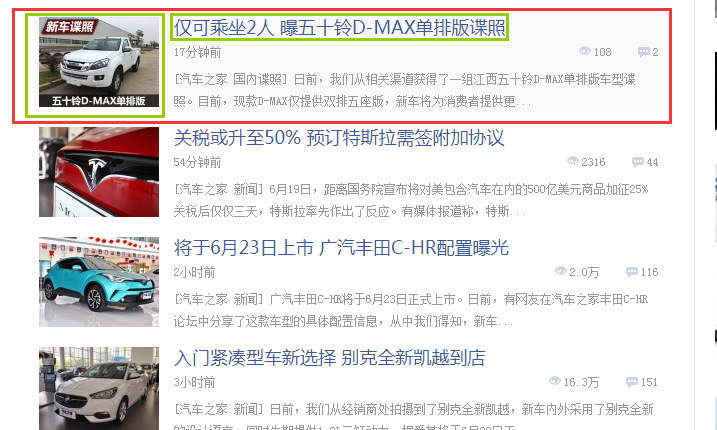
获取每条新闻的标题,标题链接和图片
import requests
from bs4 import BeautifulSoup
import uuid
reponse = requests.get(url="https://www.autohome.com.cn/news/")
reponse.encoding = reponse.apparent_encoding #获取文本原来编码,使两者编码一致才能正确显示
soup = BeautifulSoup(reponse.text,'html.parser') #使用的是html解析,一般使用lxml解析更好
target = soup.find(id="auto-channel-lazyload-article") #find根据属性去获取对象,id,attr,tag...自定义属性
li_list = target.find_all('li') #列表形式
for li in li_list:
a_tag = li.find('a')
if a_tag:
href = a_tag.attrs.get("href") #属性是字典形式,使用get获取指定属性
title = a_tag.find("h3").text #find获取的是对象含有标签,获取text
img_src = "http:"+a_tag.find("img").attrs.get('src')
print(href)
print(title)
print(img_src)
img_reponse = requests.get(url=img_src)
file_name = str(uuid.uuid4())+'.jpg' #设置一个不重复的图片名
with open(file_name,'wb') as fp:
fp.write(img_reponse.content)
总结使用:
(1)requests模块
reponse = requests.get(url) #根据url获取响应对象
reponse.apparent_encoding #获取文本的原来编码
reponse.encoding #对文本编码进行设置
reponse.text #获取文本内容,str类型
reponse.content #获取数据,byte类型
reponse.status_code #获取响应状态码
(2)beautifulsoup4模块
soup = BeautifulSoup('网页代码','html.parser') #获取HTML对象
target = soup.find(id="auto-channel-lazyload-article") #根据自定义属性获取标签对象,默认找到第一个
li_list = target.find_all('li') #根据标签名,获取所有的标签对象,放入列表中
注意:是自定义标签都可以查找
v1 = soup.find('div')
v1 = soup.find(id='il')
v1 = soup.find('div',id='i1')
find_all一样
对于获取的标签对象,我们可以使用
obj.text 获取文本
obj.attrs 获取属性字典