https://www.cnblogs.com/yaohaitao/p/5703288.html
Spark Streaming与Storm的应用场景
对于Storm来说:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择
对于Spark Streaming来说:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性
Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。
事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
| 对比点 |
Storm |
Spark Streaming |
| 实时计算模型 |
纯实时,来一条数据,处理一条数据 |
准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
| 实时计算延迟度 |
毫秒级 |
秒级 |
| 吞吐量 |
低 |
高 |
| 事务机制 |
支持完善 |
支持,但不够完善 |
| 健壮性 / 容错性 |
ZooKeeper,Acker,非常强 |
Checkpoint,WAL,一般 |
| 动态调整并行度 |
支持 |
不支持 |
Flink
http://www.360doc.com/content/17/0526/17/21332217_657502791.shtml
流式的数据流执行引擎,针对数据流分布式计算提供了数据分布、数据通信以及容错机制等功能。
DataSet 对静态数据进行操作,将静态数据抽象成分布式数据集 / DataStream 流式 / Table结构化数据抽象成关系表
集成Hadoop生态圈其他项目,可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式数据源,直接重用MapReduce或Storm代码或通过YARN申请集群资源等
一般原则:
storm流处理任务,mapreduce、spark支持批量任务,spark streaming是在spark上支持流处理任务的子系统,其采用了一种mirco-batch的架构,把输入的数据切分为细粒度的batch,并且每个batch数据提交一个批处理的spark任务,所以spark streaming本质上还是基于spark批处理系统对流式数据的处理,而storm则完全流式,flink能够同时支持批量任务处理和流处理任务。
在执行引擎这一层,流处理系统和批处理系统最大的不同在于节点之间的数据传输方式。对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立即通过网络传输到下一个节点,由下一个节点继续处理。对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完毕后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。这两种充分体现了流处理对系统低延迟的要求和批处理系统对高吞吐量的要求。
Flink执行引擎采用了一种十分灵活的方式,同时支持了两种传输模型。以固定的缓存块为单位进行网络传输,用户可以通过缓存块超时值指定缓存块的传输机制,如果缓存块超时值为0,则数据传输方式类似流式系统标准模型,此时系统获得最低的处理延迟。如果缓存块的超时无限大,则数据传输方式类似批处理系统标准模型,此时系统可以获得最高的吞吐量。总之缓存块的超时阈值越小,流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。用户通过延迟和吞吐量进行权衡
容错:批处理系统由于文件可以重复访问,当某个人物失败后,重启该人物即可,但流式系统数据源源不断,任务连续运行
spark RDD transfer/action 血统linger
storm ID之类的
flink 分布式快照、可部分重发的数据,用户可以自定义对整个JOB进行快照的时间间隔,当任务失败时,flink会将整个job恢复到最近一次快照,并从数据源重发快照之后的数据。
按照用户自定义的分布式快照间隔时间,flink会定时在所有数据源中插入一种特殊的快照标志消息,这些快照标志消息和其他消息一样在DAG中流动,但是不会被用户定义的业务逻辑所处理,每一个快照标记消息都将其所在的数据流分成两部分:本次快照数据和下次快照数据
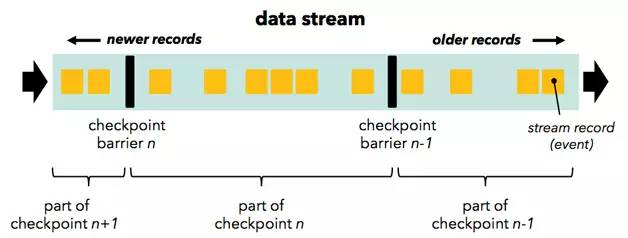
快照标记消息沿着DAG流经各个操作符,当操作符处理到快照标记消息时,会对自己的状态进行快照,并存储起来,当一个操作符有多个输入的时候,Flink会将先抵达的快照标记消息及其之后的消息缓存起来,当所有的输入中对应该次快照标记消息全部抵达后,操作符对自己的状态快照并存储,之后处理所有快照标记消息之后的已缓存消息。操作符对自己的状态快照并存储可以是异步与增量的操作,并不需要阻塞消息的处理。
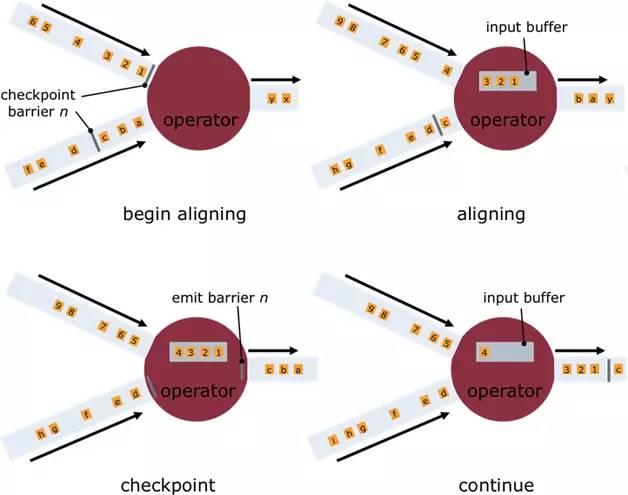
当所有的Data Sink(终点操作符),都收到快照标记信息并对自己的状态快照和存储后,整个分布式快照就完成了,同时通知数据源释放该快照标记消息之前的所有消息,若之后发生节点崩溃等异常情况时,只需要恢复之前存储的分布式快照状态,并从数据源重发该快照以后的消息就可以了
Exactly-Once是流处理系统需要支持的一个非常重要的特性,它保证每一条消息只被流处理系统处理一次,许多流处理系统的业务逻辑都依赖于Exactly-Once。相对于至多一次和至少一次,flink基于分布式快照实现了精确一次特性
分布式快照方式的优点:
低延迟,由于操作符状态的存储可以异步,所以进行快照的过程基本上不会阻塞消息的处理,所以不会对消息延迟产生负面的影响。
高吞吐量,当操作符状态较少时,对吞吐量基本没有影响,当操作符状态较多时,相对于其他容错机制,分布式快照的时间间隔是用户自己定义的,所以用户可以权衡错误恢复时间和吞吐量要求来调整分布式快照的时间间隔
与业务逻辑的隔离,分布式快照机制与用户的业务逻辑完全隔离,用户的业务逻辑不会依赖或是对分布式快照产生任何影响
错误恢复的代价,分布式快照的事件间隔越短,错误恢复的事件越少,与吞吐量负相关
流处理的时间窗口:
对于流处理系统来说,流入的消息时不存在上限,所以对于聚合连接等操作,流处理系统需要对流入的消息进行分段,然后基于每一段数据进行聚合或者是连接,消息的分段即为窗口,流处理系统支持的窗口类型很多,比如基于时间间隔对消息进行分段的事件窗口。
事件窗口一般是根据Task所在节点的本地始终进行切分,这种实现容易,不会产生阻塞。但有的场景无法实现,比如消息本身带有时间戳,用户希望按照消息本身的时间戳来分段;由于不同节点的是种可能不同,以及消息在流经各个节点的延迟不同,在某个节点属于同一个时间窗口处理的消息,流到下一个节点时可能被切割分到不同的事件窗口中,从而产生不符合预期的结果。
flink支持3种时间窗
1. Operator Time: 根据Task所在节点的本地时钟来切分的时间窗口
2. Event Time: 消息自带的时间戳,确保时间戳在同一个时间窗口的所有消息一定会被正确处理,由于消息可能乱序流入Task,所以Task需要缓存当前时间窗口消息处理的状态,直到确认属于该时间窗口的所有消息都被处理,才可以释放,如果乱序的消息延迟很高会影响分布式系统的吞吐量
3. Ingress Time: 消息本身并不带有时间戳信息,但用户仍然希望按照消息而不是节点的时钟划分窗口时间,此时可以在消息流入flink流处理系统时自动生成增量的时间戳赋予消息,之后处理流程与event time相同。由于其在消息源处时间戳一定是有序的,所以在流处理系统中,相对于event time,其乱序的消息延迟不会很高,因此对flink分布式系统的吞吐量和延迟的影响也会更小
Event Time时间窗口实现:
通过water mark来支持 http://www.360doc.com/content/17/0526/17/21332217_657502879.shtml

flink的一些优化:通用手段
定制的序列化工具,显示内存管理的前提步骤就是序列化,将JAVA对象序列化成二进制数据存储在内存上(on heap 或 off heap),序列化反序列化,减少元数据信息冗余。比如Hadoop writable自己实现该接口等
显示的内存管理,一般通用的做法是批量申请和释放内存,每个JVM实例有一个统一的内存管理器,所有内存的申请和释放都通过该内存管理器进行,可以避免常见的内存碎片问题,同时由于数据以二进制的方式存储,可以大大减轻垃圾回收的压力
缓存友好的数据结构和算法,对于计算密集的数据结构和算法,直接操作序列化或的二进制数据,而不是将对象反序列化后再进行操作,同时,只将操作相关的数据连续存储,可以最大化的利用L1/L2/L3缓存,减少cache miss的概率,提升CPU计算的吞吐量,以排序为例,由于排序的主要操作是对Key进行对比,如果将所有排序数据的key与value分开并对key连续存储,那么访问key时cache命中率会大大提高
分布式计算框架可以使用定制序列化工具的前提是要待处理数据流是同一类型,由于数据集对象的类型固定,从而可以只保存一份对象的schema信息,节省大量的存储空间,同时,对于固定大小的类型,也可以通过固定的便宜位置存取,在需要访问某个对象成员变量时,通过定制的序列化工具,并不需要反序列化整个对象,而是直接通过偏移量,从而只需要反序列化特定的对象成员变量,如果对象的成员变量较多时,能够大大减少JAVA对象的创建开销,以及内存数据的拷贝大小,flink数据集都支持任意的java或scala类型,通过自动生成定制序列化工具,既能够保证api接口对用户的友好,也达到了和hadoop类似的序列化效果
Flink将内存分为3个部分,每个部分都有不同用途:
-
Network buffers: 一些以32KB Byte数组为单位的buffer,主要被网络模块用于数据的网络传输。
-
Memory Manager pool大量以32KB Byte数组为单位的内存池,所有的运行时算法(例如Sort/Shuffle/Join)都从这个内存池申请内存,并将序列化后的数据存储其中,结束后释放回内存池。
-
Remaining (Free) Heap主要留给UDF中用户自己创建的Java对象,由JVM管理。
更高效的存储格式。Parquet,ORC等列式存储被越来越多的Hadoop项目支持,其非常高效的压缩性能大大减少了落地存储的数据量。