Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop主要包括HDFS、MapReduce,以及数据仓库工具Hive, 分布式数据库Hbase
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hive作为构建在Hadoop之上的数据仓库,hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
apache计算引擎的发展关系
在apche中的三篇论文鉴定大数据的基础其中mr收到其中一篇论文的启发创造了mapreduce,同时随着时代的发展也出现了其他的技术技术。
Hbase全称为Hadoop Database,即hbase是hadoop的数据库,是一个分布式的存储系统。Hbase利用Hadoop的HDFS作为其文件存储系统,利用Hadoop的MapReduce来处理Hbase中的海量数据。利用zookeeper作为其协调工具。
1.第一代计算引擎 mapreduce
mapreduce 作为第一个计算引擎,用于批处理,是计算引擎的先驱,内部支持机器学习但是现在机器学习库不在更新,并且mapreduce 编写十分的耗时,开发效率低,开发时间成本太大,所以很少有企业写mapreduce 来跑程序。
2.第二代计算引擎 pig/hive
作为第二代引擎pig/hive 对hadoop(如果不知道hadoop的话,建议不要看了。。。。。)进行了嵌套,其存储基于hdfs,计算基于mr,hive/pig在处理任务时首先会把本身的代码解析为一个个m/r任务,这样就大大的降低了mr的编写编写成本。 pig 有自己的脚本语言属于,比hive更加的灵活 hive 属于类sql语法,虽然没有pig灵活,但是对于现在程序员都会sql的世界来说大家更喜欢使用hive pig/hive 只支持批处理,且支持机器学习 (hivemall)
3.第三代计算引擎 spark/storm
随着时代的发展,企业对数据实时处理的需求愈来愈大,所以就出现了storm/spark
这两者有着自己的计算模式 storm属于真正的流式处理,低延迟(ms级延迟),高吞吐,且每条数据都会触发计算。 spark属于批处理转化为流处理即将流式数据根据时间切分成小批次进行计算,对比与storm而言延迟会高于0.5s(s级延迟),但是性能上的消耗低于storm。“流式计算是批次计算的特例(流式计算是拆分计算的结果)”
4.第四代计算引擎 flink
flink2015年出现在apache,后来又被阿里巴巴技术团队进行优化(这里我身为国人为之自豪)为blink,flink支持流式计算也支持的批次处理。 flink为流式计算而生属于每一条数据触发计算,在性能的消耗低于storm,吞吐量高于storm,延时低于storm,并且比storm更加易于编写。因为storm如果要实现窗口需要自己编写逻辑,但是flink中有窗口方法。 flink内部支持多种函数,其中包括窗口函数和各种算子(这一点和spark很像,但是在性能和实时上spark是没有办法比较的) flink支持仅一次语义保证数据不丢失 flink支持通过envent time来控制窗口时间,支持乱序时间和时间处理(这点我觉得很厉害) 对于批次处理flink的批处理可以理解为 “批次处理是流式处理的特例”(批次计算是流式计算的合并结果)
exactly once 精准一次
At least once 至少一次

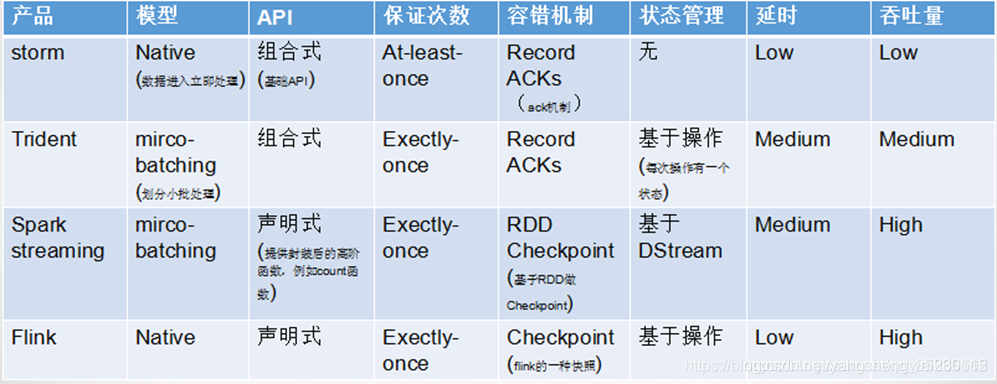
相比于storm ,spark和flink两个都支持窗口和算子,减少了不少的编程时间 flink相比于storm和spark,flink支持乱序和延迟时间(在实际场景中,这个功能很牛逼),个人觉得就这个功能就可以锤爆spark 对于spark而言他的优势就是机器学习,如果我们的场景中对实时要求不高可以考虑spark,但是如果是要求很高就考虑使用flink,比如对用户异常消费进行监控,如果这个场景使用spark的话那么等到系统发现开始预警的时候(0.5s),罪犯已经完成了交易,可想而知在某些场景下flink的实时有多重要。