如何分配集群资源 (怎么配置Yarn)
总资源
集群中每台机器的配置 (RAM,CPU,Disk,网卡)
预留资源
总资源 - 集群中运行服务需要的资源(操作系统OS,DataNode,NodeManger,HBase,Hive,ZK,Impala..)
配置集群
YARN分配资源 主要参数:
yarn.nodemanager.resource.memory-mb 每个节点分配的内存
yarn.nodemanager.resource.cpu-vcores 每个节点分配的虚拟CPU

YARN资源调度分配 主要参数:
yarn.scheduler.minimum-allocation-mb container最少内存
yarn.scheduler.maximum-allocation-mb container最大内存<限制分配资源大小>
Determine HDP Memory Configuration Settings
python hdp-configuration-utils.py -c 12 -m 48 -d 12 -k False
Using cores=12 memory=48GB disks=12 hbase=False
Profile: cores=12 memory=43008MB reserved=6GB usableMem=42GB disks=12
Num Container=21
Container Ram=2048MB
Used Ram=42GB
Unused Ram=6GB
***** mapred-site.xml *****
mapreduce.map.memory.mb=2048
mapreduce.map.java.opts=-Xmx1536m
mapreduce.reduce.memory.mb=2048
mapreduce.reduce.java.opts=-Xmx1536m
mapreduce.task.io.sort.mb=768
***** yarn-site.xml *****
yarn.scheduler.minimum-allocation-mb=2048
yarn.scheduler.maximum-allocation-mb=43008
yarn.nodemanager.resource.memory-mb=43008
yarn.app.mapreduce.am.resource.mb=2048
yarn.app.mapreduce.am.command-opts=-Xmx1536m
***** tez-site.xml *****
tez.am.resource.memory.mb=2048
tez.am.java.opts=-Xmx1536m
***** hive-site.xml *****
hive.tez.container.size=2048
hive.tez.java.opts=-Xmx1536m
hive.auto.convert.join.noconditionaltask.size=402653000其他注意项
虚拟内存和物理内存检查
NodeManager 可以监控Container的虚拟和物理内存使用情况
一般都会关闭虚拟内存检查

Set -Xmx of java-opts of each container to 0.8 * (container memory allocation)
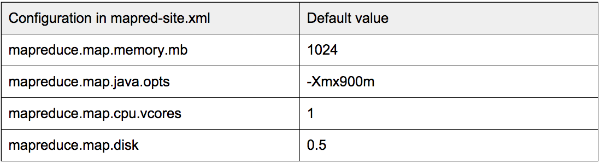
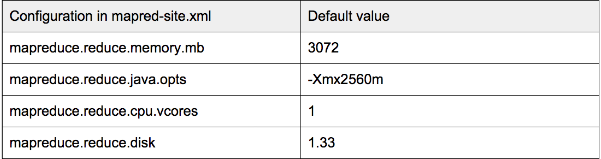
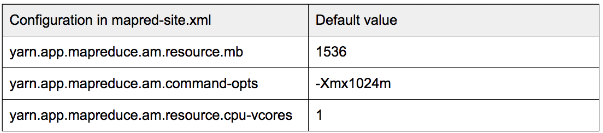
Bottleneck resource 瓶颈资源
Since there are three types of resources, different containers from different jobs may ask for different amount of resources. This can result in one of the resources becoming the bottleneck. Suppose we have a cluster with capacity (1000G RAM,16 Cores,16 disks) and each Mapper container needs (10G RAM,1 Core, 0.5 disks): at most, 16 Mappers can run in parallel because CPU cores become the bottleneck here.
As a result, (840G RAM, 8 disks) resources are not used by anyone. If you meet this situation, just check the RM UI http://:8088/cluster/nodes to figure out which resource is the bottleneck. You can probably allocate the leftover resources to jobs which can improve performance with such resource. For example, you can allocate more memory to sorting jobs which used to spill to disk.
参考文档
https://mapr.com/blog/best-practices-yarn-resource-management/
https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.3.0/bk_installing_manually_book/content/determine-hdp-memory-config.html