Description
Before the digital age, the most common "binary" code for radio communication was the Morse code. In Morse code, symbols are encoded as sequences of short and long pulses (called dots and dashes respectively). The following table reproduces the Morse code for the alphabet, where dots and dashes are represented as ASCII characters "." and "-":
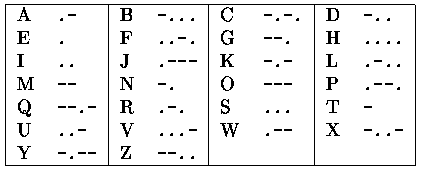
Notice that in the absence of pauses between letters there might be multiple interpretations of a Morse sequence. For example, the sequence -.-..-- could be decoded both as CAT or NXT (among others). A human Morse operator would use other context information (such as a language dictionary) to decide the appropriate decoding. But even provided with such dictionary one can obtain multiple phrases from a single Morse sequence.
Task
Write a program which for each data set:
reads a Morse sequence and a list of words (a dictionary),
computes the number of distinct phrases that can be obtained from the given Morse sequence using words from the dictionary,
writes the result.
Notice that we are interested in full matches, i.e. the complete Morse sequence must be matched to words in the dictionary.
Notice that in the absence of pauses between letters there might be multiple interpretations of a Morse sequence. For example, the sequence -.-..-- could be decoded both as CAT or NXT (among others). A human Morse operator would use other context information (such as a language dictionary) to decide the appropriate decoding. But even provided with such dictionary one can obtain multiple phrases from a single Morse sequence.
Task
Write a program which for each data set:
reads a Morse sequence and a list of words (a dictionary),
computes the number of distinct phrases that can be obtained from the given Morse sequence using words from the dictionary,
writes the result.
Notice that we are interested in full matches, i.e. the complete Morse sequence must be matched to words in the dictionary.
Input
The first line of the input contains exactly one positive integer d equal to the number of data sets, 1 <= d <= 20. The data sets follow.
The first line of each data set contains a Morse sequence - a nonempty sequence of at most 10 000 characters "." and "-" with no spaces in between.
The second line contains exactly one integer n, 1 <= n <= 10 000, equal to the number of words in a dictionary. Each of the following n lines contains one dictionary word - a nonempty sequence of at most 20 capital letters from "A" to "Z". No word occurs in the dictionary more than once.
The first line of each data set contains a Morse sequence - a nonempty sequence of at most 10 000 characters "." and "-" with no spaces in between.
The second line contains exactly one integer n, 1 <= n <= 10 000, equal to the number of words in a dictionary. Each of the following n lines contains one dictionary word - a nonempty sequence of at most 20 capital letters from "A" to "Z". No word occurs in the dictionary more than once.
Output
The output should consist of exactly d lines, one line for each data set. Line i should contain one integer equal to the number of distinct phrases into which the Morse sequence from the i-th data set can be parsed. You may assume that this number is at most 2 * 10^9 for every single data set.
Sample Input
1 .---.--.-.-.-.---...-.---. 6 AT TACK TICK ATTACK DAWN DUSK
Sample Output
2
解题思路:
字典配对问题。就是把输入的各个字符串先转化为"..--"等形式,然后对于给定的字符串,如题中的".---.--.-.-.-.---...-.---.",从第0位开始和下面的候选字符串开始配对。采用dp的思想,dp[i]表示前i个已经配对的情况数。如果dp[i]不为0,表示当前的情况可以由之前的情况转化。
# include<stdio.h>
# include<string.h>
# define N 10050
char cod[26][10] = {{".-"},{"-..."},{"-.-."},{"-.."},{"."},{"..-."},{"--."},
{"...."},{".."},{".---"},{"-.-"},{".-.."},{"--"},{"-."},{"---"},{".--."},
{"--.-"},{".-."},{"..."},{"-"},{"..-"},{"...-"},{".--"},{"-..-"},{"-.--"},{"--.."}};
char final[N][N];//用来存储转化后的字符串
int dp[N];
int main()
{
int t;
while(scanf("%d",&t)!=EOF)
{
// printf("t %d",t);
while(t--)
{
char str[N];
scanf("%s",str);
int Lens=strlen(str);
int n,i,j;
scanf("%d",&n);
for(i=0;i<n;i++)
{
char tmp[N];
scanf("%s",tmp);
//final[i]需要清零
final[i][0]='\0';
int len=strlen(tmp);
for(j=0;j<len;j++)
{
strcat(final[i],cod[tmp[j]-'A']);
}
}
memset(dp,0,sizeof(dp));
dp[0]=1;
for(i=0;i<Lens;i++)
{
if(dp[i]!=0)
{
for(j=0;j<n;j++)
{
int tmpL=strlen(final[j]);
if(strncmp(str+i,final[j],tmpL)==0)//很巧妙
dp[i+tmpL]+=dp[i];
}
}
}
printf("%d\n",dp[Lens]);
}
}
return 0;
}