链接:https://pan.baidu.com/s/1qIIisSGE7JDHzHdfEJR_tg 密码:14es
链接:https://pan.baidu.com/s/15-f2xR5w_Bnxxwi-bgKr5Q 密码:vipv
上面是《利用python进行数据分析》这本书的PDF版和其相关资料。要安装的东西书上都有说,这些我也就不多瞎比比
有些地方很难,但这些都是后面的内容,现在看到的只是让你知道 数据分析 可以用来做什么。
一些简单可理解的地方、有坑的地方,我都说出我的理解或找到一些其他大佬的文章给大家作参考。
不能理解也无所谓,后面详解的时候,都会明白的。
-------------------------------------------------------------------------------------------------------------------------------------------------
#来自bit.ly的1.usa.gov的数据
path = "C:/Users/Lzy_nh/Desktop/example.txt"
#路径要么用双斜杠 "C:\\Users\\Lzy_nh\\Desktop\\example.txt" ,要么用反斜杠 "C:/Users/Lzy_nh/Desktop/example.txt",要么 #就是单斜杠要在字符串前加 r"path = "C:\Users\Lzy_nh\Desktop\example.txt"
open(path).readline() #用这种方法读入的是一串字符#围观输出
import json

records = [json.loads(line)for line in open(path)] #此时的records是一个list对象。
records[0] #围观输出
#上面运用了列表推导式。格式:variable = [out_exp_res for out_exp in input_list if out_exp==2],详情自行百度谷歌
-------------------------------------------------------------------------------------------------------------------------------------------------
#用纯python代码对时区进行计数
time_zones = [rec['tz']for rec in records if 'tz' in rec] #因为不是每组记录都有时区字段,所以要用到 if 将其不含时区字段的排除
#常见的遍历计数法
def get_counts(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts
#标准库计数法一
from collections import defaultdict
def get_counts2(sequence):
counts = defaultdict(int)#所有值都被初始化为0
for x in sequence:
counts[x] += 1
return counts
#defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值
#defaultdict参考文章地址https://blog.csdn.net/dpengwang/article/details/79308064
#要获得前十位的 时区和其计数值 ,需要用到一些有关字典的处理技巧
def top_counts(count_dict,n=10):
value_key_pairs = [(count,tz)for tz,count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:]
#Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组。
#标准库计数法二
from collections import Counter
counts = Counter(time_zones)
counts.most_common(10) #围观输出
#从字典对象创建了一个Counter类,其most_common(N)是返回一个Ntop列表
#Couter类参考文章地址http://www.pythoner.com/205.html
#用pandas对时区进行计数
from pandas import DataFrame,Series
import pandas as pd;import numpy as np
frame = DataFrame(records)#frame的输出形式是摘要视图,不会把一堆数据全部输出
tz_counts = frame['tz'].value_counts()#frame['tz']返回的是一个Series对象,value_counts是它的一个方法。这不详解,后面说
tz_counts[:10] #围观输出
#用matplotlib生成一张图片。要先把未知或缺失时区填上一个替代值。使用fillna函数可替换缺失值(即NA),未知值(即空字符#串)则可通过 布尔型数组索引 加以替换
clean_tz = frame['tz'].fillna('Missing')
clean_tz[clean_tz == ''] = 'Unknown'
#布尔型数组索引,我懂但不知道咋说,看文章去吧。参考文章地址https://blog.csdn.net/zby1001/article/details/54381535
tz_counts = clean_tz.value_counts()
#此时我们要使用%pylab进入绘图模式,否则是毫无反应
%pylab #就是在ipython命令行里输入这个
tz_counts[:10].plot(kind='barh',rot=0)
#得图如下(左边信息看不全,我的锅)

#上面的分析就告一段落了,我们现在来分析a字段。a字段里含有执行URL短缩操作的浏览器、设备、应用程序等信息。也就是 #咋们爬虫常说的请求头(USER_AGENT,一下简称agent)中的信息(以后会应该出一个爬虫的讲解,以巩固我对爬虫的理解)
results = Series([x.split()[0]for x in frame.a.dropna()])
results.value_counts()[:8] #这里的results也是一个Series对象哦,所以一样可以使用value_counts方法
#split()方法不多说,参考文章地址http://www.runoob.com/python/att-string-split.html
#Series参考文章地址https://blog.csdn.net/brucewong0516/article/details/79196902
#这里我有个疑问,为啥results = Series([x.split()[1]for x in frame.a.dropna()])越界?我想应该是有东西的啊,求大佬解答
#这时来按window和非window用户对时区统计信息进行分解。默认agent中有“Window”字样则认为是Window用户。
cframe = frame[frame.a.notnull()] #先使用notnull方法判断信息是否缺失,然后通过布尔型数组索引重构一个数组
operating_system = np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows') #np.where()后面章节会详解
by_tz_os = cframe.groupby(['tz',operating_system]) #cfame.groupby()后面也会详解
agg_counts = by_tz_os.size().unstack().fillna(0) #用size()进行计数类似上面的value_counts函数,并用unstack对计数结果重塑
agg_counts[:10]#围观输出
#unstack()方法参考文章地址https://www.cnblogs.com/bambipai/p/7658311.html
#通过升序排序选取最常出现的时区
indexer = agg_counts.sum(1).argsort()
indexer[:10] #围观输出
count_subset = agg_counts.take(indexer)[-10:]
count_subset #围观输出
count_subset.plot(kind = 'barh',stacked = True)
#如下图
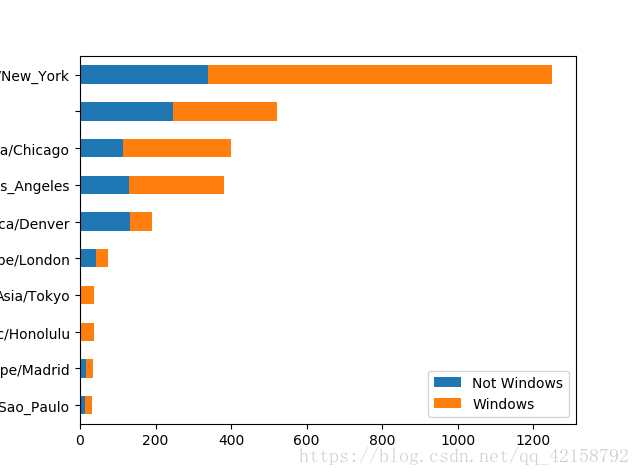
normed_subset = count_subset.div(count_subset.sum(1),axis = 0)
normed_subset.plot(kind = 'barh',stacked = True)
#如下图

第一章后面对电影评分,婴儿姓名等分析等内容就不多讲了,因为里面许多方法都是在后面讲的,现在不要纠结不会。等学到后面回来看就自然会懂了。
纯手打,好累,要萌妹子抱抱~~~
我们下一章节见~~~