转载于:https://blog.csdn.net/shuzfan/article/details/77839176
人脸关键点检测的论文。速度略差,但想法不错。 视频中人脸关键点检测往往存在抖动,而常见的深度学习方法又不适合做连续跟踪。 本文提供了一个实现跟踪的思路。
文章链接: CVPR Workshop2017《Deep Alignment Network: A convolutional neural network for robust face alignment》
源码(Theano实现): https://github.com/MarekKowalski/DeepAlignmentNetwork
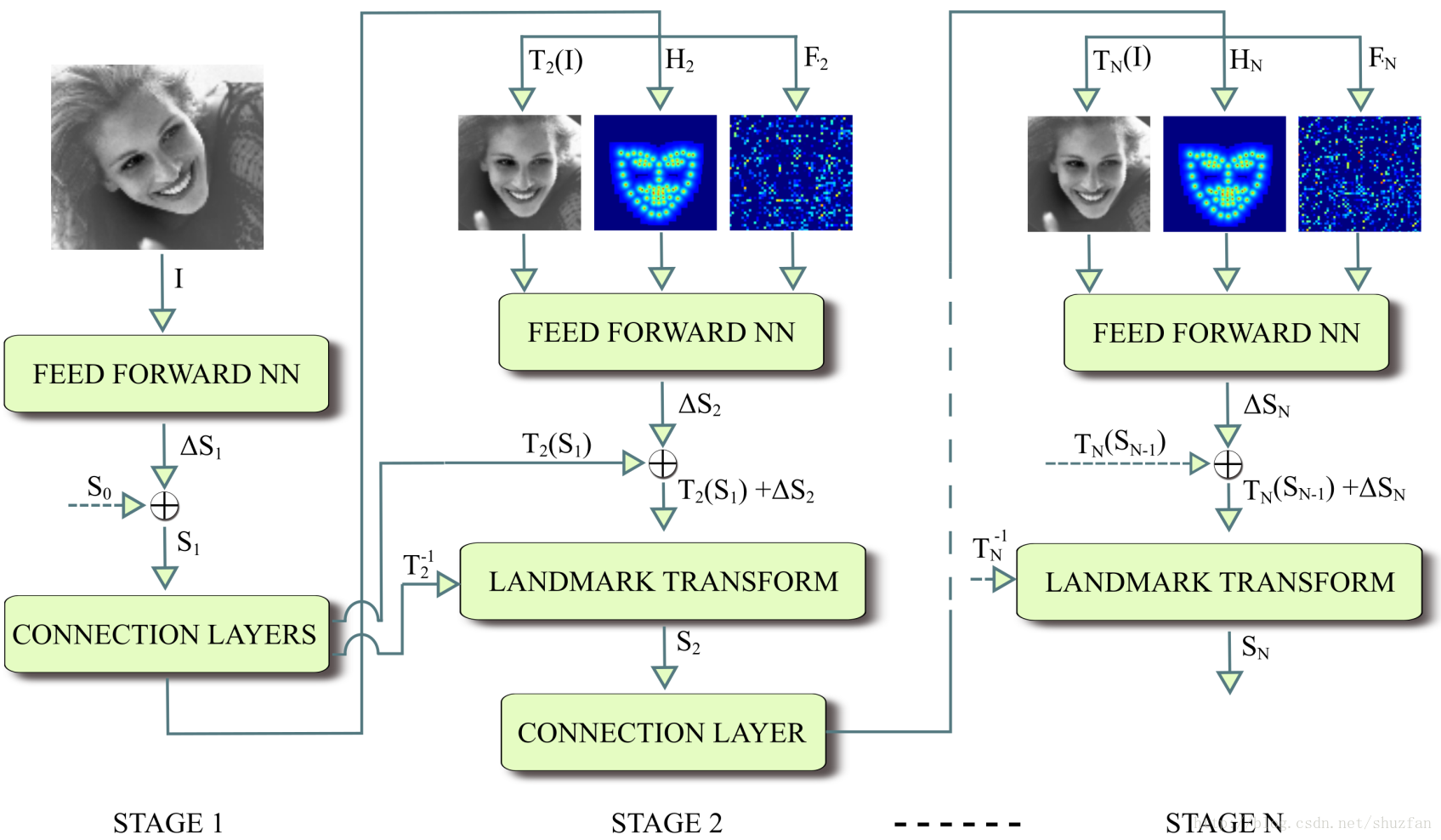
首先,可以明显看出是一个 迭代 处理的框架。 关键点检测流程如下:
(1)初始
输入灰度图 II 以及 标准关键点模板 S0S0,预测得到新的关键点位置 S1S1。
其中“Feed Forward NN” 结构如下,输出136用于预测68个关键点:

新的关键点位置会送入 “Connection Layers”,该网络示意图如下:

首先计算一个 S1S1 到 S0S0 的相似变化矩阵 T1T1。注意,这里不采用仿射变换矩阵,是为了防止局部畸变。 通过 T1T1 我们可以对图像进行矫正得到 T1(I)T1(I), 同时对关键点进行变换得到关键点热点图 H1H1。 特征图 F1F1 是通过拿取 “Feed Forward NN”的F1特征进一步得到的。
其中 关键点热点图 通过下式计算得到:(其实就是一个中心衰减,关键点处值最大,越远则值越小)

其中 特征图 如下计算的: 输出特征为1x3136,reshape为 56x56, 然后上采样到 112x112,和输入图像一样大。 (之所以一开始不搞成112x112,是因为实验发现提升不大但计算量会增加比较多。)
(2)初始迭代
每次迭代输入 TN(I)TN(I), HNHN 和 FNFN ,它们的维度均为 112×112112×112。 然后计算新的 St+1St+1。
需要注意的是,由于图像进行了相似变换,因此为了和最初的输入图像相匹配,需要做如下矫正:
St+1=T−1t+1(Tt+1(St)+ΔSt+1)St+1=Tt+1−1(Tt+1(St)+ΔSt+1)
效果图

Menpo challenge,没有人脸检测时(直接假定框位于图像中心)的效果:

Feature Work
- End-to-end learning
- A joint model for semi-frontal and profile faces
- A learning based method for similarity transform estimation
- Ensambling of multiple DAN networks