传送:基于Hierarchical Softmax的word2vec模型原理
基于Negative Sampling的word2vec模型原理
一、基本概念准备
稀疏向量(one-hot representation):用一个很长的向量来表示一个词,向量的长度为词典大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引。举例如果有一个词典[“面条”,”方便面”,”狮子”],那么“面条”对应的词向量就是[1,0,0],“方便面”对应的词向量就是[0,1,0]。这种表示方法不需要繁琐的计算,缺点是长度过长(维数灾难,特别是将其用于deep learning的一些算法时),以及无法体现出近义词之间的关系,比如“面条”和“方便面”显然有非常紧密的关系,但转化成向量[1,0,0]和[0,1,0]以后,就看不出两者有什么关系了,因为这两个向量相互正交。当然用这种稀疏向量求和来表示文档向量效果还不错,清华的长文本分类工具THUCTC使用的就是此种表示方法
密集向量(Distributed representation):基本思想是直接用一个普通稠密实数向量表示一个词:[0.972,-0.177,0.109...]维数以50,100比较常见(维数一般不高,向量的每一维称为一个词语特征,该特征捕获了有用的句法和语义特征,特点是将词语的不同句法和语义特征分布到它的每一个维度上去表示),一个词怎么表示成这样一个向量是需要训练的,word2vec是其中一种(每个词在不同的语料库和训练方法下,得到的词向量也可能不一样)
word2vec是谷歌在2013年开源提出基于上下文语境的词向量(简单的三层神经网络,为单词寻找一个连续向量空间中的表示,即将one-hot encode转为低维度的连续值,其中语义相近的词将被映射到嵌入空间中相近的位置,即根据给定的语料库,通过优化后的训练模块快速有效的将一个词语表达成向量形式),如图是百分点公司的训练词向量的模型图(这个图的原理,下面章节会重点抽丝剥茧讲解)
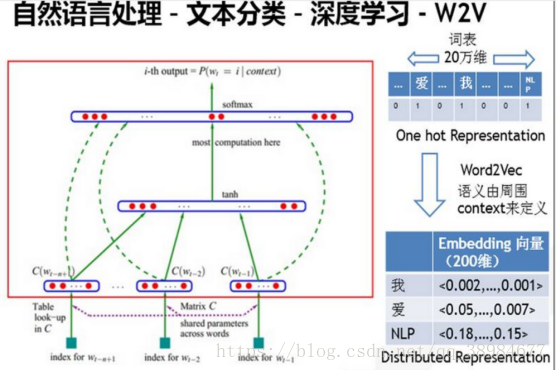
Word2vec通常作为一种预处理步骤,之后词向量被送入判别模型(通常是RNN)生成预测结果和执行其他操作(比如词性标注、语义角色标注、情感分析、句法分析等)
二、语言模型
语言模型就是分析一句话是否是正常人表述出来的,比如机器学习、语音识别得到若干候选之后,利用语言模型挑选靠谱的结果
#语言模型的形式化描述就是给定一个T个词的字符串s,分析它是自然语言的概率P(w1,w2,…,wt),w1到wt依次表示这句话中的各个词.有个很简单的推论是:
p(t)=p(x1,x2,⋯xt)=p(x1)p(x2|x1)p(x3|x1,x2)⋯p(xt|x1,x2,⋯xt−1)
#即在第一个词确定后,分析后面的词在前面词出现情况下的出现概率三、n-gram语言模型
n-gram模型只管这个词前面的n-1词,加上自身共n个词
p(Xj|contentj)=p(Xj|Xj-n+1,Xj-n+2,...Xj-1)
#n=3一般就是目前计算能力的上限了,n不能取太大(取大时语料库经常不足)
#无法建模出词之间的相似度:比如两个词经常出现在同一content,但建模时无法体现这一相似性的
#有些n元组(n个词的组合,与顺序有关)在语料库中没有出现,对应出来的条件概率=0(分子=0),那么一句话的概率=0,解决的方法两种:平滑法(分子分母都加一个数)、回退法(利用n-1元组的概率去替换n元组的概率)四、神经网络语言模型-词向量
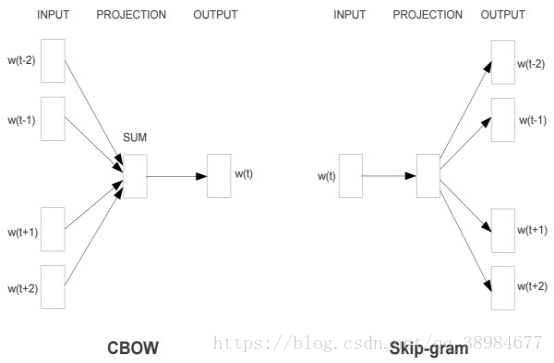
在CBOW中,输入的是2c个词向量,输出词表中所有词的softmax概率(训练目标是期望特定词对应的softmax概率最大),对应神经网络模型输入层有2c个神经元,输出层有词表个数个神经元,隐藏层的神经元个数可以自行设定,通过DNN反向传播算法,可求出DNN模型的参数,并得到所有词对应的词向量。当要求出2c个词对应最可能的中心词时,可用DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可
在skip-gram中,输入的是特定词,输出的是softmax概率排名前2c的词,对应神经网络模型输入层有1个神经元,输出层有词表个数个神经元,隐藏层的神经元个数自行设定,通过DNN反向传播算法,可求出模型参数并得到所有词对应的词向量。当要求出某一个词对应最可能的2c个上下文词时,可通过一次DNN前向传播算法得到排名前2c的softmax概率对应神经元所对应的词
word2ve为什么不用现成的DNN模型,要继续优化出新方法呢?最主要问题是DNN模型的这个处理过程非常耗时。词汇表一般在百万级别以上,这意味着DNN输出层需要进行softmax计算各个词的输出概率,计算量过大
五、基于Hierarchical Softmax模型
无论是CBOW模型或者skip-gram模型,具体的实现都可以用神经网络完成,但问题是计算量太大,参数定义如下:
n:一个词上下文包含的词数,与n-gram中n的含义相同
m:词向量的长度,通常在50~200
h:隐藏层的规模,一般在100量级
N:词典的规模,通常在1W~10W
T:训练文本中单词个数(即分词后的语料库中词个数)以神经网络CBOW模型为例,输入层为n-1个单词的词向量,长度为m(n-1),隐藏层的规模为h,输出层的规模为N。那么前向的时间复杂度就是o(m(n-1)h+hN)≈o(hN)这只是处理一个词所需要的复杂度。如果要处理所有文本,则需要o(hNT)的时间复杂度。在o(hNT)之中,h和T值相对固定,想要对其进行优化,应该从N入手。而输出层的规模之所以为N,是因为这个神经网络要完成的是N选1的任务。解决的思路是将一次分类分解为多次二分类,这也是Hierarchical Softmax的核心思想。举例有[1,2,3,4,5,6,7,8]这8个分类,想要判断词A属于哪个分类,首先判断A是属于[1,2,3,4]还是属于[5,6,7,8]。如果判断出属于前者,那么就进一步分析是属于[1,2]还是[3,4],以此类推,这样一来就把单个词的时间复杂度从o(h*N)降为o(h*logN),更重要的减少了内存的开销
六、word2vec的大概流程
(1)分词/词干提取和词形还原:中文和英文的nlp各有各的难点,中文的难点在于需要进行分词,将一个个句子分解成一个单词数组。而英文虽然不需要分词,但是要处理各种各样的时态,所以要进行词干提取和词形还原
(2)构造词典,统计词频:这一步需要遍历一遍所有文本,找出所有出现过的词,并统计各词的出现频率
(3)构造树形结构:依照出现频率构造Huffman树。需要注意的是,所有分类都应该处于叶节点,像下图绿色节点显示的那样
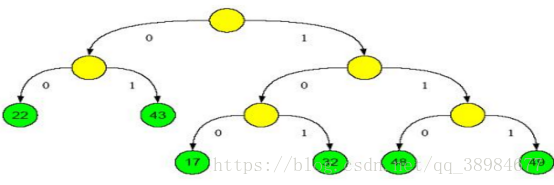
(4)生成节点所在的二进制码(左0右1):拿上图举例,22对应的二进制码为00,而17对应的是100。也就是这个二进制码反映了节点在树中的位置,就像门牌号一样能按照编码从根节点一步步找到对应的叶节点
(5)初始化各非叶节点的中间向量和叶节点中的词向量:树中的各个节点,都存储着一个长为m的向量(词向量长度),但叶节点和非叶结点中的向量的含义不同。叶节点中存储的是各词的词向量,是作为神经网络输入的。而非叶结点中存储的是中间向量,对应于神经网络中隐含层的参数,与输入一起决定分类结果
(6)训练中间向量和词向量:对于CBOW模型,首先将词A附近的n-1个词的词向量相加作为系统输入,并按照词A在步骤4中生成的二进制码,一步步的进行分类并按照分类结果训练中间向量和词向量。举例对于绿17节点,已经知道其二进制码是100,那么在第一个中间节点应该将对应的输入分类到右边。如果分类到左边,则表明分类错误,需要对向量进行修正。第二个,第三个节点也是这样,以此类推,直到达到叶节点。因此对于单个单词来说,最多只会改动其路径上的节点的中间向量,而不会改动其他节点
七、Huffman树的构造-word2vec Python源码解析
1.统计词频-在Python自带的counter类基础上进行修改,并去停用词
#继承自Counter的类.不直接用Counter是因为它虽然能够统计词频,但无法完成过滤功能.而MulCounter可以通过larger_than和less_than这两个方法过滤掉出现频率过少和过多的词
class MulCounter(Counter):
# a class extends from collections.Counter
# add some methods, larger_than and less_than
def __init__(self,element_list):
super().__init__(element_list)
def larger_than(self,minvalue,ret='list'):
temp = sorted(self.items(),key=_itemgetter(1),reverse=True)
low = 0
high = temp.__len__()
while(high - low > 1):
mid = (low+high) >> 1
if temp[mid][1] >= minvalue:
low = mid
else:
high = mid
if temp[low][1]<minvalue:
if ret=='dict':
return {}
else:
return []
if ret=='dict':
ret_data = {}
for ele,count in temp[:high]:
ret_data[ele]=count
return ret_data
else:
return temp[:high]
def less_than(self,maxvalue,ret='list'):
temp = sorted(self.items(),key=_itemgetter(1))
low = 0
high = temp.__len__()
while ((high-low) > 1):
mid = (low+high) >> 1
if temp[mid][1] <= maxvalue:
low = mid
else:
high = mid
if temp[low][1]>maxvalue:
if ret=='dict':
return {}
else:
return []
if ret=='dict':
ret_data = {}
for ele,count in temp[:high]:
ret_data[ele]=count
return ret_data
else:
return temp[:high]WordCounter完成的是根据文本来统计词频的工作。确切来说,是对完整的文本进行分词,过滤掉停用词,然后将预处理好的单词数组交给MulCounter去统计
class WordCounter():
# can calculate the freq of words in a text list
# for example
# >>> data = ['Merge multiple sorted inputs into a single sorted output',
# 'The API below differs from textbook heap algorithms in two aspects']
# >>> wc = WordCounter(data)
# >>> print(wc.count_res)
# >>> MulCounter({' ': 18, 'sorted': 2, 'single': 1, 'below': 1, 'inputs': 1, 'The': 1, 'into': 1, 'textbook': 1,
# 'API': 1, 'algorithms': 1, 'in': 1, 'output': 1, 'heap': 1, 'differs': 1, 'two': 1, 'from': 1,
# 'aspects': 1, 'multiple': 1, 'a': 1, 'Merge': 1})
def __init__(self, text_list):
self.text_list = text_list
self.stop_word = self.Get_Stop_Words()
self.count_res = None
self.Word_Count(self.text_list)
def Get_Stop_Words(self):
ret = []
ret = FI.load_pickle('./static/stop_words.pkl')
return ret
def Word_Count(self,text_list,cut_all=False):
filtered_word_list = []
count = 0
for line in text_list:
res = jieba.cut(line,cut_all=cut_all)
res = list(res)
text_list[count] = res
count += 1
filtered_word_list += res
self.count_res = MulCounter(filtered_word_list)
for word in self.stop_word:
try:
self.count_res.pop(word)
except:
pass2.Huffman树的构造
Huffman树的构造与Huffman编码密切相关(huffman树的叶子节点对应输出层神经元,内部节点则起到隐藏层神经元的作用)
#构造方法
while (单词列表长度>1) {
从单词列表中挑选出出现频率最小的两个单词;
创建一个新的中间节点,其左右节点分别是之前的两个单词节点;
从单词列表中删除那两个单词节点并插入新的中间节点(新节点的频率:加总);
}当以上循环执行完毕,节点列表中唯一一个节点即为根节点
构造过程:首先要构造一个Huffman树的节点类,在该类中存储一个节点的相关信息,包括这个节点的频率,左右子树,节点的value(value存储的内容根据节点类型有所不同,对于叶节点存储的是这个单词本身词向量,而对于非叶节点,存储的是中间向量)和对应的huffman码,如下所示
class HuffmanTreeNode():
def __init__(self,value,possibility):
# common part of leaf node and tree node
self.possibility = possibility
self.left = None # 左子树
self.right = None # 右子树
# value of leaf node will be the word, and be
# mid vector in tree node
self.value = value # the value of word
self.Huffman = "" # store the huffman codeHuffman树类中主要的方法有:build_tree、merge、generate_huffman_code。build_tree用来产生树形结构;merge用来合并两个节点并产生它们的父节点;generate_huffman_code用来根据已经产生的树结构来为词典中的每个词产生对应的huffman码
class HuffmanTree():
def __init__(self, word_dict, vec_len=15000):
self.vec_len = vec_len # the length of word vector
self.root = None
word_dict_list = list(word_dict.values())
node_list = [HuffmanTreeNode(x['word'],x['possibility']) for x in word_dict_list] #对词典中的每个词都产生对应的HuffmanTreeNode对象,以便进一步处理
self.build_tree(node_list)
# self.build_CBT(node_list)
self.generate_huffman_code(self.root, word_dict)
def merge(self,node1,node2):
top_pos = node1.possibility + node2.possibility # 将概率相加
top_node = HuffmanTreeNode(np.zeros([1,self.vec_len]), top_pos)
if node1.possibility >= node2.possibility :
top_node.left = node1
top_node.right = node2
else:
top_node.left = node2
top_node.right = node1
return top_nodemerge方法,新生成节点的频率是两个输入节点的频率之和,其左右子节点即为输入的两个节点。值得注意的是,新生成的节点肯定不是叶节点,而非叶结点的value值是中间向量,初始化为零向量
def build_tree(self,node_list):
while node_list.__len__()>1:
i1 = 0 # i1表示概率最小的节点
i2 = 1 # i2 概率第二小的节点
if node_list[i2].possibility < node_list[i1].possibility :
[i1,i2] = [i2,i1]
for i in range(2,node_list.__len__()): # 找到最小的两个节点
if node_list[i].possibility<node_list[i2].possibility :
i2 = i
if node_list[i2].possibility < node_list[i1].possibility :
[i1,i2] = [i2,i1]
top_node = self.merge(node_list[i1],node_list[i2]) # 合并两个节点,生成新的中间节点
if i1<i2: # 删除两个旧节点
node_list.pop(i2)
node_list.pop(i1)
elif i1>i2:
node_list.pop(i1)
node_list.pop(i2)
else:
raise RuntimeError('i1 should not be equal to i2')
node_list.insert(0,top_node) # 插入新节点
self.root = node_list[0]3.huffman码的生成:
生成Huffman树之后,就需要生成对应的Huffman码,以便进行下一步的训练过程。生成Huffman码的过程比较简单,假设一个节点的huffman码为“xx”,那么其左节点的huffman码为”xx1”,右节点的huffman码为”xx0”,从上到下直到叶节点,由此生成所有节点(包括叶节点和非叶结点)的Huffman码
def generate_huffman_code(self, node, word_dict):
stack = [self.root]
while (stack.__len__()>0):
node = stack.pop()
# go along left tree
while node.left or node.right :
code = node.Huffman
node.left.Huffman = code + "1"
node.right.Huffman = code + "0"
stack.append(node.right)
node = node.left
word = node.value
code = node.Huffman
# print(word,'\t',code.__len__(),'\t',node.possibility)
word_dict[word]['Huffman'] = code这一过程需要遍历所有节点。遍历可以用递归来完成,但是这里使用栈来完成遍历过程
八、CBOW加层次的网络结构-连续词袋模型
CBOW模型是根据上下文词,来推断当前词发生概率(实现判断这句话是否是自然语句;并获得词向量)。两个模型(CBOW和skip-gram)都是以Huffman树作为基础,Huffman树非叶节点存储的中间变量(初始化为零向量),而叶节点对应存储的单词词向量(随机初始化),假设已经有一个构造好的Huffman树,以及初始化完毕的各个向量,可以开始输入文本来进行训练
CBOW模型和skip-gram模型输入-映射-输出层简略图
CBOW模型输入-映射-输出层图
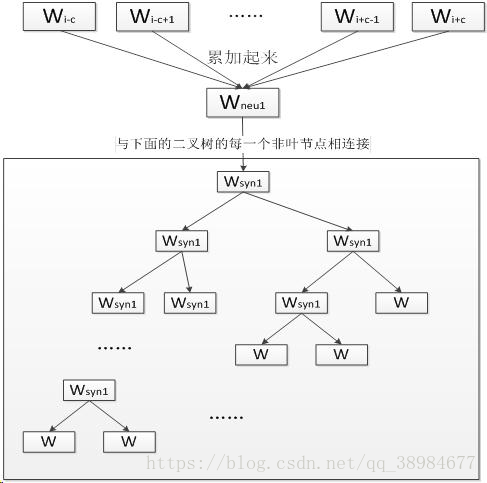
上图的解释:
第一层(最上面的那一层)称为输入层,输入的是若干个词向量(输入单词向量的数目是由window size参数决定,因为使用的是词袋模型,输入的2c个单词向量是平等的),中间在神经网络概率语言模型中从隐含层到输出层的计算是主要影响训练效率的地方,CBOW和Skip-gram模型考虑去掉隐含层。实践证明新训练词向量的精确度可能不如NNLM模型(具有隐含层),但可以通过增加训练语料的方法来完善
第三层(输出层-softmax层,维度与第一层维度相同)是方框里面的那个二叉树(以词库中的词作为叶节点,并以词频为权重构造出来HUFFMAN树,如果词库中有D个词,则有D个叶子节点),叫霍夫曼树,W代表一个词,Wsyn1是非叶节点是一类词堆,还要继续往下分
九、CBOW模型流程举例-帮助理解
corpus={i drink coffee everyday},预测"coffee"
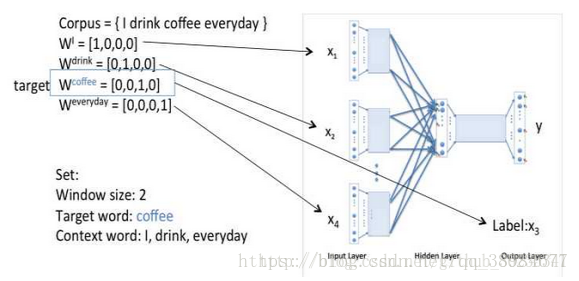
1.window size=2,取"coffee"左右两边各两个词(左边为"I","drink",右边为"everyday"),词向量共有3个维度(对应下图W矩阵的行数),第一次初始化为one hot encode(维度为词库大小)
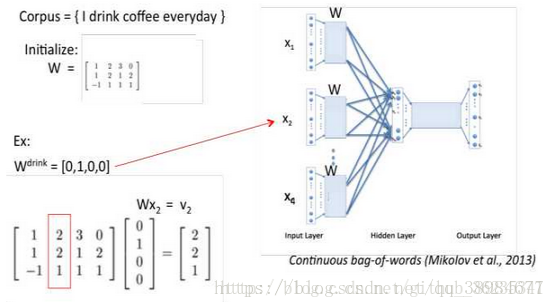
2.词向量的第二次随机初始化处理,W为随机初始化矩阵(n*m,n为词向量维度大小,w为词库中单词个数),v为第一层输入的词向量(依次算出Windows size个词的第一层输入词向量,即v1,v2,v3)
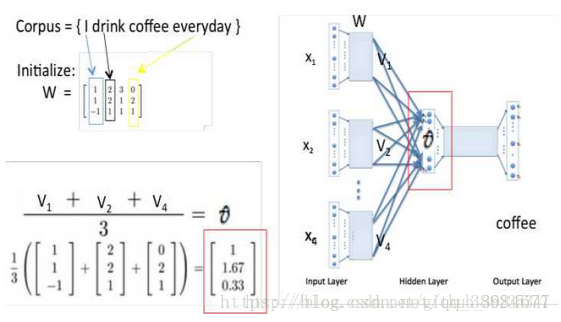
3.对Windows size个词的词向量加总后求平均值(到第二层)
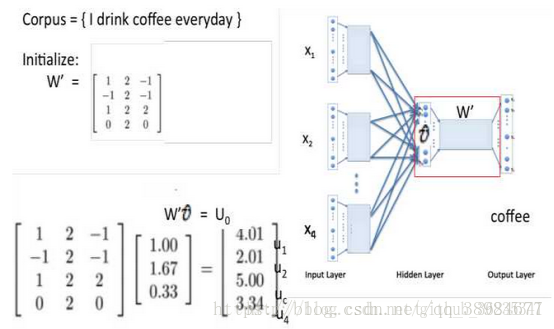
4.隐藏层到输出层之间的连接W',Xw即上图中的Uo,当Xw传导到输出层,因为输出层是一个二叉树,每一次分支都可视为进行一次二分类(左边负类0,右边正类1,直接比较大小即可)
根据sigmoid函数,二分类函数写成:

故一个节点被分到正类的概率是:

θ向量是逻辑回归模型当前节点的待定参数,将每个分支的概率相乘即所需的p(W|CONTNT(W))
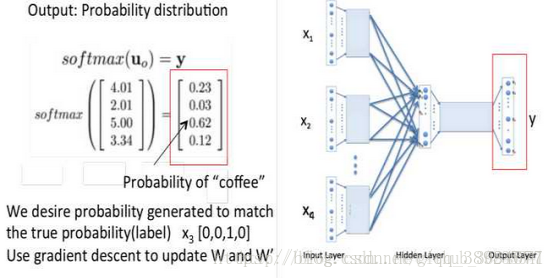
5.最终,通过大量的数据迭代,使用梯度下降更新W和W’(初始化是用小随机数生成),来最小化loss函数,训练结束后的W就是词向量的矩阵,任何一个单词的One-Hot表示乘以这个矩阵W就可以得到其词向量的表示(这里也解释了为何输出和输出必须是相同的维度)
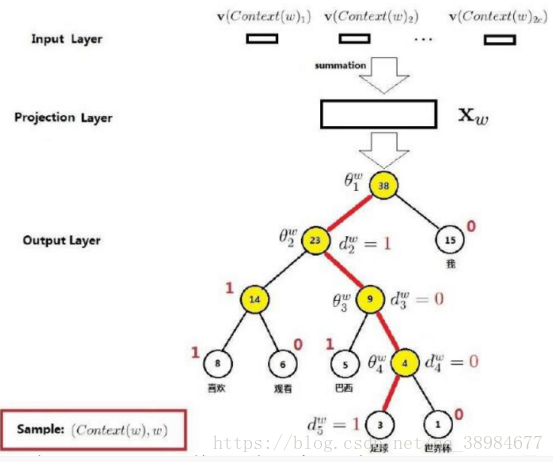
6.详细说明从映射层到输出层:需要借助之前构造的Huffman树.从根节点开始,映射层的值需要沿着Huffman树不断进行logistic分类,并且不断的修正各中间向量和词向量
此时中间的单词为w(t),而映射层输入为 pro(t)=v(w(t-2))+v(w(t-1))+v(w(t+1))+v(w(t+2)),假设此时单词为“足球”,即w(t)=“足球”,则其Huffman码可知为d(t)=”1001”,根据Huffman码可知,从根节点到叶节点的路径为“左右右左”,即从根节点开始,先往左拐,再往右拐2次,最后再左拐,既然知道路径,那么就按照路径从上往下依次修正路径上各节点的中间向量。在第一个节点,根据节点的中间向量Θ(t,1)和pro(t)进行Logistic分类。如果分类结果显示为0,则表示分类错误(应该向左拐,即分类到1)则要对Θ(t,1)进行修正,并记录误差量。接下来处理完第一个节点之后,开始处理第二个节点。方法类似修正Θ(t,2)并累加误差量。接下来的节点都以此类推,在处理完所有节点,达到叶节点之后,根据之前累计的误差来修正词向量v(w(t))。这样,一个词w(t)的处理流程就结束了,如果一个语料库中有N个词,则需要将上述过程在重复N遍,从w(0)~w(N-1)
十、skip-gram模型
skip-gram模型输入的是当前词的词向量,输出的是周围词的词向量(通过当前词预测周围词)

词Wi与huffman树直接连接,没有隐藏层
skip-gram表示“跳过某些符号”。例如句子“中国 足球 踢得 真是 太烂 了”有4个3元词组,分别是“中国 足球 踢得”、“足球 踢得 真是”、“踢得 真是 太烂”、“真是 太烂 了”,句子的本意都是“中国足球太烂”,可是上面4个3元组并不能反映出这个信息
此时使用Skip-gram模型允许某些词被跳过,因此可组成“中国足球太烂”这个3元词组。如果允许跳过2个词,即2-Skip-gram,那么上句话组成的3元词组有18个,有8个词组能够正确反映例句中的真实意思;另一方面扩大了语料,3元词组由原来的4个扩展到了18个。语料的扩展能够提高训练的准确度,获得的词向量更能反映真实的文本含义
skip-gram的原理不作更具体的剖析了,大同小异
十一、注意事项
1.架构(skip-gram慢,对罕见字有利,CBOW快);训练算法(负采样对罕见字有利,分层softmax对常见字和低维向量有利);window大小(skip-gram通常在10附近,CBOW在5附近);优化训练速度,选择CBOW模型速度较快,线程数设置成与CPU核的个数一致,迭代次数5次
注:window预测词与当前词的最大距离(词嵌入的质量非常依赖于上下文窗口大小的选择,大的上下文窗口学到的词嵌入更反映主题信息,小的更反映词的功能和上下文语义信息)
2.提高词向量的精度:一般来说维数越多越好,当然也有例外;训练数据集越大越好,覆盖面广,质量也要尽量好
3.词向量的短语组合word2phrase:比如‘中国河’要变成一个专用短语,那么可以用‘中国’+‘河’向量的平均数来表示,然后以此词向量来找一些近邻词
4.word2vec词聚类:先进行分词存储为.txt文件(word2vec的输入文件),计算的是余弦值(0-1),值越大代表两个词关联度越高。可以挖掘一些关于某词的派生词,或者寻找相同主题时可以使用
5.词向量的可加性:vector(巴黎)-vector(法国)+vector(意大利)=vector(罗马),即意大利的巴黎约等于罗马(差表示投影(向量的差:向量逐位相减),就是一个单词在不同上下文中的相对出现)
6.不需要去停用词。目前word2vec较好方法是Negative Sampling,论文中提出该方法为了应对停用词,会进行subsampling(二次抽样)
7.需要去除语料库中出现次数过少的词(模型对于低频词向量训练不充分,向量置信度不高,也会影响其他向量的效果)
8.向量维度通常设50-200维
9.实验显示,负采样次数取15次的效果略好于5次;Negative Sampling方法比哈夫曼树的方法准确度高
10.如果有很多条研究语料,彼此之间相互独立,且不同语料之间(分词之后)有很多重复的词,可以进行合并后一起处理
11.一个在线测试网站:http://cikuapi.com/index.php