有点小错误正在修改!!!!
最近学习了关于python的一点点知识,做出一点点小小程序来帮助自己加深印象,如果有需要的朋友也可以借此互相交流和沟通!
一、首先我们先查询指定网站的robots协议信息,如我们今天要爬去的网站:http://music.taihe.com/robots.txt,点击链接跳转到页面发现页面不存在
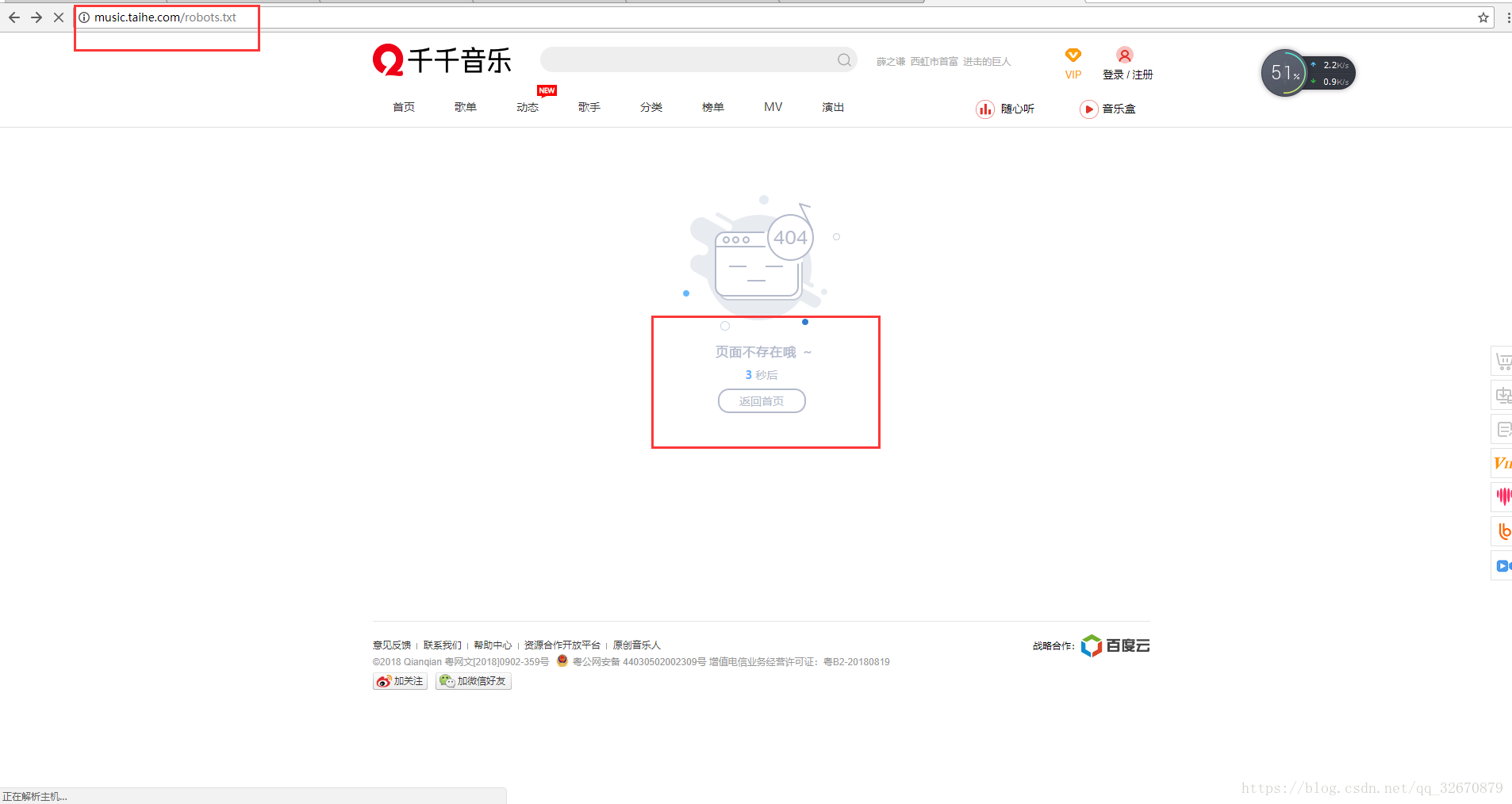
如果网站没有对应的robots协议信息,则表示我们可以根据我们的需要理性的对我们需要的数据进行获取[坏笑]。
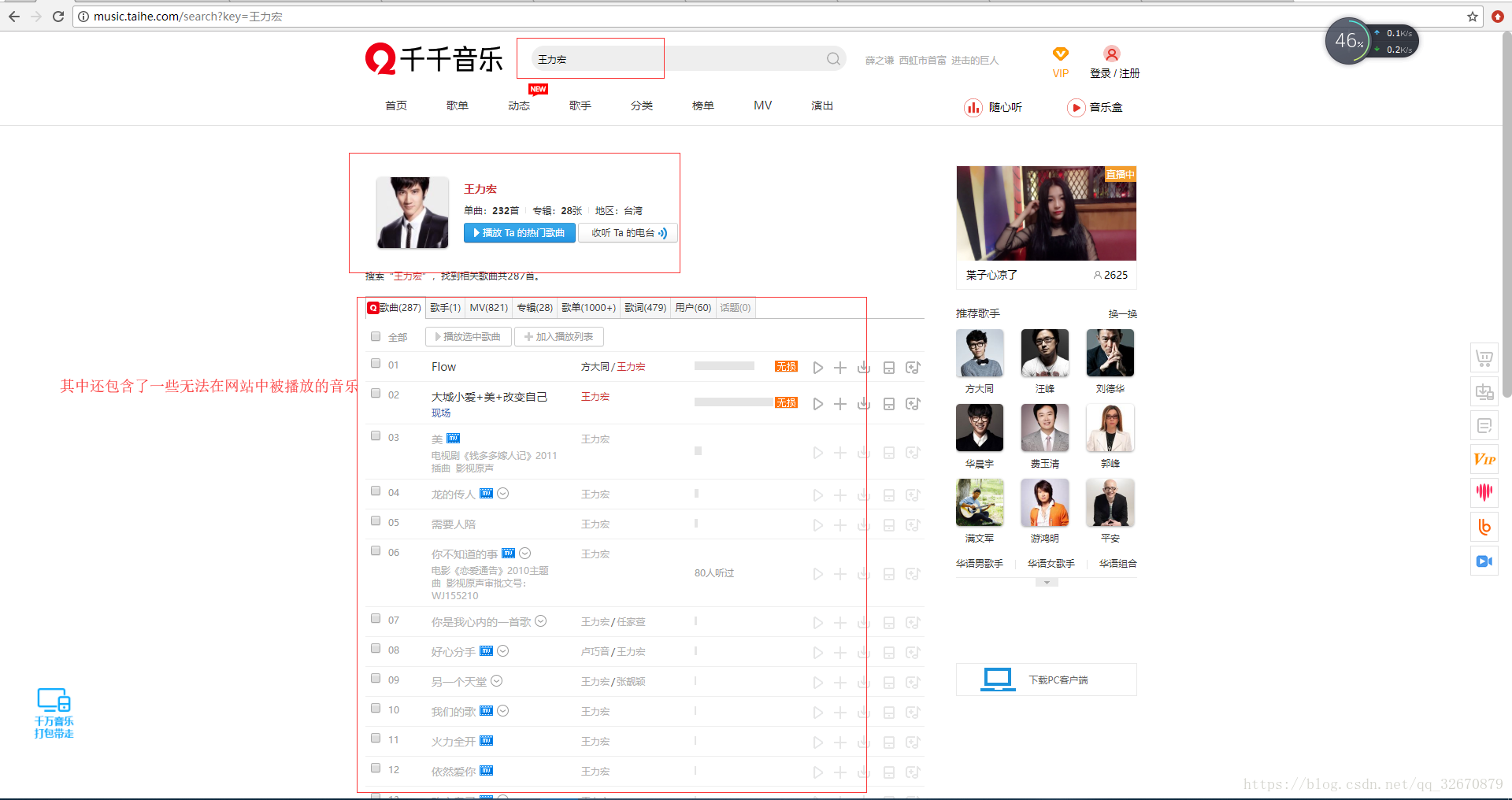
二、当我们输入歌手名称如:王力宏,之后敲回车键,url地址更新为:
“http://music.taihe.com/search?key=王力宏”可以看到页面中的关于歌手王力宏的音乐列表信息如下图:(可以看到其中某些歌曲并不能点击和播放)
三、查看网页对应的html页面(查看网页源代码,查看网页中的数据是否为静态数据填充的)
右键单击网页中的空白处,选择“查看网页源代码”,可以看到页面对应的基本的html页面组成元素。
可以在网页中通过歌曲列表中的某一项的名称,在源代码中查找的方式,查看是否存在与源代码中,即可进行简单的确认数据是否为动态加载的数据信息。(如果网页中的列表信息存在源代码中,则证明是静态数据展示,否则为动态加载的数据,然后展示在页面中的)
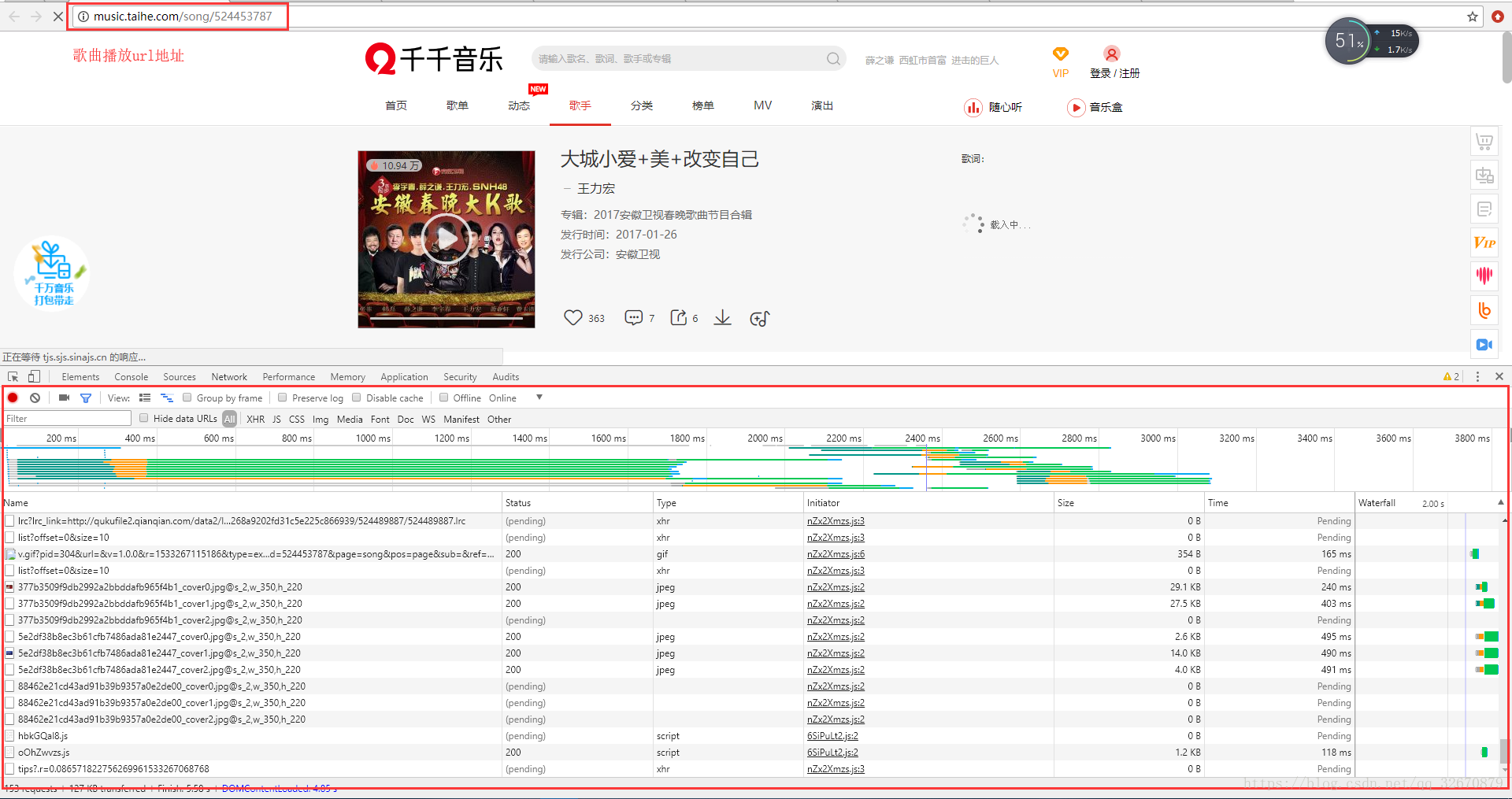
四、点击某一首列表中的某一首歌曲进入播放界面如下:
(其中我们可以注意到歌曲播放页面的网页url地址为:http://music.taihe.com/song/524453787,当我们进入该网页后,按下键盘上的F12可以查看该页面下的console控制台,选择网络标签,查看请求该页面时,浏览器向服务器发送的请求以及服务器反馈的数据信息)
(通过url地址我们可以知道,每首歌的播放地址其实只有后面歌曲id的不同,因此我们要在上一个web页面中通过这个ID获取到歌曲列表中所有歌曲的id信息,这样我们就可以通过id找到所有的歌曲对应的web页面了。)
分析上方的网页url我们知道了每首歌曲播放页面只是对应的歌曲id不同,鉴于以上分析得到的结果,我们复制歌曲的id值,回到搜索结果页面,url地址为:http://music.taihe.com/search?key=王力宏,然后在网页中右键单击,选择查看网页源代码,进行全局搜索(按下Ctrl + F ,,调用查找选项,再按下Ctrl + V)将id值放到搜索框中,找到id值所在的位置。
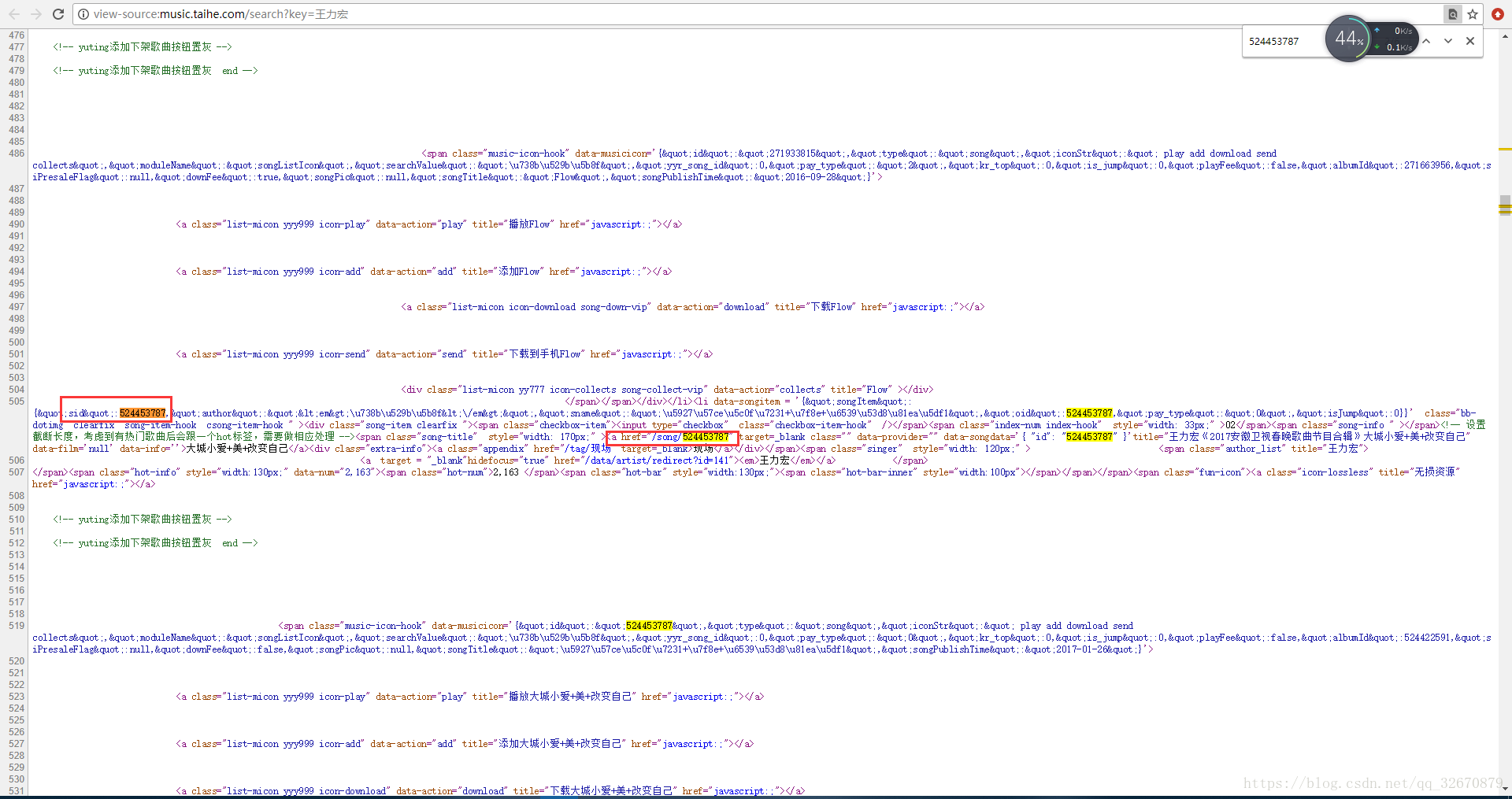
五、通过re正则表达式获取到所有得id值
从上图中我们可以看到很多可以匹配到一首歌曲的id信息的上下文,我们也需要对各个列表项中的匹配到id值的上下文进行简单的区分,帮助我们可以通过re获取到所有的id信息。
在此处我使用的是sid":271933815,,因为歌曲id为纯数字信息,所以我通过\d进行匹配,加号表示匹配加号前的数据信息一个或多个。
正则表达式为:song_ids = re.findall(r'sid":(\d+),', search_html),此处的search_html是歌曲列表页面的网页数据信息,列表形式展示。
六、获取音乐数据的真实的地址,即外链
在歌曲播放页面我们通过F12检查网页,查看网络请求,然后在其中找到其传回的data中包含mp3地址的即可
#encoding=utf-8
#-*- encoding : utf-8 -*-
#/python-pachong/music-baidu/music_spider.py
#爬百度音乐上面的文件信息----------------搜索音乐,并输出前几首,然后由用户指定下载。。。
import requests
import re
import json
import os
# data = {
# 'key': '刘德华'
# }
# search_url = 'http://music.baidu.com/search?key='
key = raw_input("请输入想要获取对应音乐的的歌手:"),
ids = {0,20,40}
data = {
'key': key,
#"刘德华"
#"王力宏"
#"Declan Galbraith",
's': 1,
# 'start': ','.join(str(ids)),
'start': 0,
'size': 20,
'third_type': 0,
}
search_url = 'http://music.taihe.com/search/song'
search_response = requests.get(search_url,params=data)
# print type(search_response)
search_response.encoding="utf-8"
search_html = search_response.text
# print search_html
song_ids = re.findall(r'sid":(\d+),', search_html)
data = {
'songIds': ','.join(song_ids),
'hq': 0,
'type': 'm4a,mp3',
'pt': 0,
'flag': -1,
's2p': -1,
'prerate': -1,
'bwt': -1,
'dur': -1,
'bat': -1,
'bp': -1,
'pos': -1,
'auto': -1,
}
song_link = 'http://play.taihe.com/data/music/songlink'
song_response = requests.post(song_link, data=data)
# 将返回的数据转换为字典
# print song_response
song_info = song_response.json()
# print song_info
song_info = song_info['data']['songList']
# print song_info
# 遍历数组,获取其中的歌曲名称和链接
i = 1
print "开始下载歌曲..."
for song in song_info:
print "正在现在第%d首歌曲\t歌曲名称为:%s" % (i, song['songName']),
i += 1
song_name = song['songName']
singer_name = song['artistName']
song_lrc = song['lrcLink']
print song_lrc
#判断歌词文件url是否为空,如果为空,那么将url地址设置为空
# if (song_lrc == ""):
# song_lrc="暂无歌词"
#创建一个以歌手名称命名的文件夹
if not os.path.exists('music/%s' %singer_name):
os.mkdir('music/%s' %key)
with open('music/%s/%s_%s.mp3' % (singer_name, song_name, singer_name), "wb") as f:
if song['songLink'] != "":
response = requests.get(song['songLink'])
f.write(response.content)
f.close()
with open('music/%s/%s_%s.lrc' % (singer_name, song_name, singer_name), 'wb') as f1:
if song_lrc != '':
response = requests.get(song_lrc)
f1.write(response.content)
f1.close()
else:
f1.write('此歌曲暂无歌词')
f1.close()
print "%s*********下载完毕" % song['songName']