一、算法解释
使用决策树二元分类分析StumbleUpon数据集,预测网页是暂时性(Ephemeral)或是长青的(Evergreen),
并且调校参数找出最佳参数组合,提高预测准确度。决策树的优点:条例清晰、方法简单、易于理解、使用范围广等。
决策树介绍:
当我们使用决策树分类算法训练数据后,会以 feature(特征字段)与label(标签字段)建立决策树。
决策树
当我们使用历史数据执行训练时会建立决策树。可是决策树不可能无限成长,因此我们必须限制它的最大分支与深度,
所以必须设置下列参数:
-a. maxBins 参数:
决策时每一个节点最大分支数
-b. maxDepth 参数:
决策树最大深度
-c. Impurity 参数:
决策树分裂节点时的方法,为什么选择特征进行分支
当树的父节点在分裂子节点时,以什么方法作为依据?例如,湿度以60为分割点,分为大于60或小于60;或者湿度
以50为分割点,分为大于50或小于50.到底哪种方式比较好呢?此时有Gini 与 Entropy 两种判断方式:
-i. 基于系数(Gini):
由意大利统计学家Corrado Gini 发明,用于计算数值散步程度(Statistical Dispersion,统计离差)的指标。
决策树算法对每种特征字段分割点计算估值,选择分裂后最小的基尼指数(Gini)方式。
-ii. 熵(Entropy):
熵(Entropy)也被用于计算机系统混乱的程度。决策树算法对每种特征字段分割点计算估值,选择分裂后最小的熵(Entropy)方式。
SVM
SVM,即Support Vector Machine(支持向量机),是一种使用线性分割平面的二元分类算法。其原理是通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
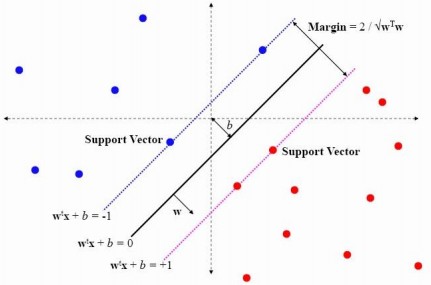
建立步骤
"""
构建机器学习模型步骤;
1、如何搜集数据 ?
历史数据
2、如何进行数据准备 ?
提取特征字段和标签字段 - 特征工程 (花费时间最多的)
3、如何训练模型 ?
使用什么算法进行训练模型
4、如何使用模型预测 ?
使用训练的模型如决策树模型,进行预测
5、如何评估模型的准确率?
使用某一个标准来评估模型的准确率,二元分类中使用 AUC 作为评估标准
6、模型训练参数如何影响准确率?
训练模型时,针对算法传递不同的参数将会影响准确率和训练时间。
如使用决策树算法,其中参数impurity、maxDepth、maxBins的值设置
7、如何找出准确率最高的参数组合?
不同的参数,不同的组合得到的模型不一样,准确率也不痒。
8、如何确认是否Overfiiting(过度训练,过拟合):
Overfiting(过度训练)是指机器学习所学到的模型过度贴近trainData,从而导致误差变得很大。
我们使用另一组数据testData再次测试,以避免overfitting的问题。
- 如果训练评估阶段是AUC很高,但是测试阶段AUC很低,代表可能有overfitting的问题。
- 如果测试与训练评估阶段的结果中AUC差异不大,就代表无overfitting的问题。
"""二、代码实现
放在这里看不出数据效果,已经转换成网页,点击这里,spark中SVM模型建立