搜索真是个好东西,没有前想找点东西忒费劲,也不知道去哪找,现在赶上好时候了,敲敲键盘点点鼠标问问度娘啥都知道了。虽然好些人吐槽度娘太任性,可有时候没她真不行,搜索结果和谷歌差不是一星半点儿,尤其技术贴,真怀念当年www.g.cn,但有的选吗,既然不能改变只能含着泪往前走。
开源的资源最牛逼的要说是lucene了,特别这些年不断完善,太多公司的产品用它了。另外一个是ELK,其实底层也是依托lucene做索引的核心层,从数据采集、创建索引到检索服务一条龙解决方案,支撑企业级应用绰绰有余,更大的数据规模也不在话下,分布式特性完美的顺应了时代需要(不云不开森),连喷子们都着急干跺脚找不到槽点完全生无可恋。
哥不信那套,非要挤挤这个粉刺,who说没槽点,有呀,ELK每次升级都面目全非,一点传承性都没有,完全颠覆码畜们的认知,太虐心了,本来学点东西就吃力,悟性差智商低岁数大野路子半路出家,不利因素集于一身,ELK这是借升级清理门户吗?其实ELK确实很不错,非常值得研究和学习,等有时间了一定大书特书一番。开春儿了,压箱底儿的存货发霉了,拿出来晒晒太阳曝曝光,聊聊自己的私有搜索引擎吧。
汉语分词,老祖宗流传下来的语言太美妙了,发音悦耳书写优美唯一的缺点就是疏忽了单词间距,西洋语言发音蹩脚辅音结尾声调不分全特么是缺点,但就一点好单词间空格分隔分词太省力了。吐血推荐汉语分词利器ANSJ,精度要求不高的话拿去用妥妥的,JAVA语言ToAnalysis.parse(sentence).recognition(filter)一句话搞定,管你啥字符集呢,还能自定义用户字典,自定义停用词库、属性过滤等等,真是小微企业的福音呀,感谢开源。Java分词用例可以参考,http://git.oschina.net/gonglibin/codes/rnplksfcy07ezivm3q4th53,另一个是基于字典库自己实现的C分词,http://git.oschina.net/gonglibin/codes/2570vrhlbutonmjxqc1az97。
停用词表,汉语词汇可分为两个大类,实词和虚词,以及十五个小类。其中,名词、动词、形容词、数词、量词、代词、副词、区别词、状态词共九小类为实词;介词、连词、助词、语气词等四小类为虚词。加之两类特殊的词,拟声词和叹词,共同组成汉语词汇类型。就分析系统本身而言,实词中的数词、量词、代词、区别词、状态词,以及虚词四小类、特殊词类的拟声词和叹词均收录在停用词表中。看看吧,为啥说汉语精彩呀,光词性分类就相当疯狂了,当然具体表定义还要具体分析,看行业看业务看需求,应该是各有各的不同。
正排索引,正向索引是在完成分词后,对词组进行特征标注的过程,包括展现频率、出现位置、词组格式等属性。正向索引在内存中以键值对方式暂存,将文档ID作为主键,词组集合作为值,在导入至倒排索引后删除。可以选择的容器很多,不考虑效率哪种都中。
倒排索引,倒排索引以字或词组为关键字创建索引,关键字对应的记录项保存了出现这个字或词组的文档集合,记录着该文档的ID和各个字符在该文档中出现的位置信息及描述。由于每个字或词组对应的文档数量是动态变化的,所以倒排表的建立和维护较为复杂,哥觉得复杂不代表别人也觉得复杂噢。由于查询的时候可以一次性得到查询关键字所对应的全部文档ID的集合,所以计算效率较高。在检索过程中,响应速度是一个较为关键的性能指标,而索引的建立是在后台进行,虽然效率相对差一些,但并不会影响到整个搜索引擎的总体效率。
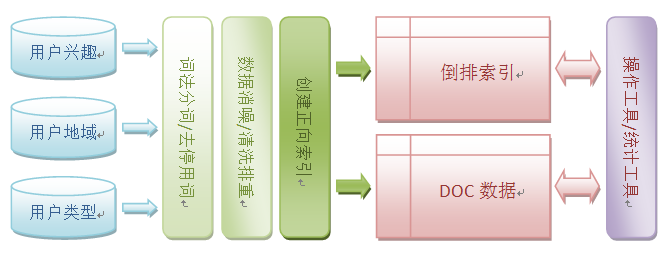
索引创建,数据应用是对结果数据进行一系列的预处理,按照定义的格式生成索引数据保存起来,等待搜索引擎加载模块的初始化操作,假设索引数据包括用户兴趣、用户地域、用户类型等维度。数据加载模块读取存储器中的中间数据并写入到内存数据库中,一个或多个搜索引擎的实例将内存映射到本进程中,保证数据样本一致性和并发访问。
搜索引擎通过解析URL的入口参数,对检索集进行整合排序操作后,返回给调用用户。用户根据不同的业务类型向数据引擎发起资源定位请求,从而获取搜索结果。一次完整的检索请求由两个步骤组成,索引查询和数据传输。第一步将关键字对应的DOC数据的ID集合返回,应用层再对ID集合遍历,逐一获取对应的DOC快照片段或全量文本。
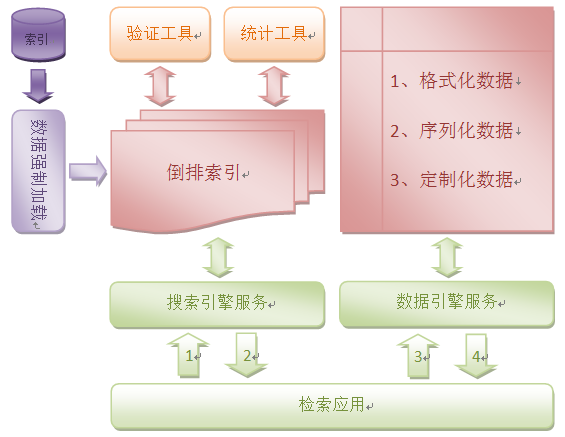
1、解析URL参数,获取索引项、关键字、逻辑关系及结果区间;
2、根据各个关键字获取文档ID集合,仅留存符合的索引字段项;
3、根据索引字段项逻辑关系归并多个关键字对应的文档ID集合;
4、根据关键字展现频率、出现位置、词组格式等属性来计算权重;
5、根据权重值按照降序执行排序,按用户请求集合结果区间返回;
检索流程是一个高度实时性同步通信服务系统,用户搜索操作的请求与应答需要控制在毫秒级时间段内,在搜索特性上同时具备BFS(广度优先)与DFS(深度优先)的特性,并且通过tf-idf向量模型来评估一个字或一个词组在语料中的重要程度。
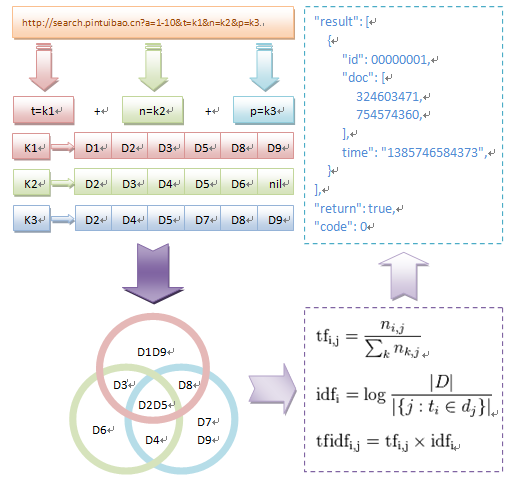
摆糊了这么多说说咋存的吧,正排用单链放内存里,管他呢内存有的是不用白不用,倒排放codis里分布式全权托管,定义好数据结构想怎么用怎么用,持久化啦读写异常啦内存管理啦基本不用过问,连接池里取出一个用,想着还就行了,搜索优化略微费点心,无论如何省不掉的,工作量的大头,水很深,拼技术拼体力看颜值看人品的活儿。DOC集合扔mongodb里,半结构化加分布式个人觉得稳定性效率并发各方面还是挺合适的。最后补充说明下,搜索技术是一个非常庞大的全面性系统性的复杂工程,值得学习的地方非常多,对个人技能的提升很有帮助,今天这篇low文就算是一个好的开始吧。
北京去年冬天不太冷,今年春天来的又早,柳絮没往年多,高速出京一如既往的堵,天真蓝云真白难得好天气,吉野家的什锦蘑菇饭浓重的荤油味冒充假素食,培训班的孩子们匆匆忙忙扒拉几口饭又赶下一场去了,不容易可也没办法,苦点累点总比被淘汰好,除了那些高尚的、纯粹的、脱离了低级趣味的人们。两年一届的上海车展即将拉开帷幕,劳斯莱斯法拉利兰博基尼早早被预定光了,今年下手又晚了,午饭鸡蛋灌饼里一定多加两片生菜,安慰一下那颗受伤的心。