一、定义:
Class:指定该域类型对应的solr的类型
Analyzer:指定分析器
Type:index、query,分别指定搜索和索引时的分析器
Tokenizer:指定分词器
Filter:指定过滤器
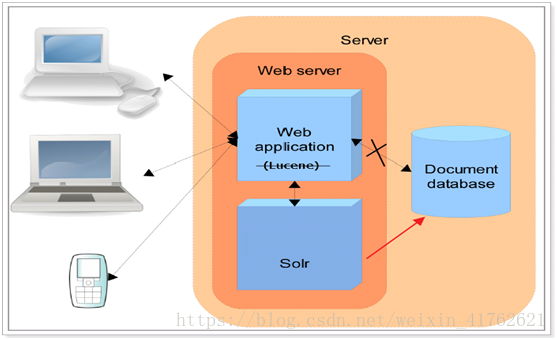
Solr是apache的顶级开源项目,它是使用java开发 ,基于lucene的全文检索服务器,solr同样没有视图渲染的功能。
Solr是如何实现全文检索的呢?
索引流程:solr客户端(浏览器、java程序)可以向solr服务端发送POST请求,请求内容是包含Field等信息的一个xml文档,通过该文档,solr实现对索引的维护(增删改)
搜索流程:solr客户端(浏览器、java程序)可以向solr服务端发送GET请求,solr服务器返回一个xml文档。
二、solr和Lucene的区别
Lucene是一个全文检索引擎工具包,它只是一个jar包,不能独立运行,对外提供服务。
Solr是一个全文检索服务器,它可以单独运行在servlet容器,可以单独对外提供搜索和索引功能。Solr比lucene在开发全文检索功能时,更快捷、更方便。
三、solr安装(Windows环境下)
1.下载solr并解压,此处解压包名为solr-4.10.3
下载地址:http://archive.apache.org/dist/lucene/solr/
下载版本:4.10.3
Linux 下需要下载 lucene-4.10.3.tgz , windows 下需要下载 lucene-4.10.3.zip2.运行环境
l Jdk:1.7及以上
l Solr:4.10.3
l Mysql:5X
l Web服务器:tomcat 7
3.安装部署
- 安装tomcat,安装文件夹名为tomcat
- 将solr-4.10.3/example/webapps下的solr.war拷贝到tomcat/webapps目录下
- 解压缩solr.war,启动tomcat,再关闭tomcat,即解压缩成功,成功后将war包删除
- 将solr-4.10.3/example/lib/ext下的所有jar包拷贝到tomcat/webapps/solr/WEB-INF/lib目录下
- 将solr-4.10.3/example/resources拷贝到tomcat/webapps/solr/WEB-INF/classes目录下(没有该目录则创建)
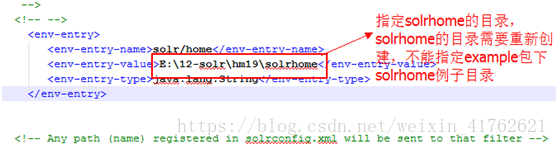
- 指定solrhome目录,下面简写solrhome目录为hm19/solrhome,修改tomcat/webapps/solr/WEB-INF/web.xml
- solrhome和solrcore关系:Solrhome是solr服务运行的主目录,一个solrhome目录里面包含多个solrcore目录,一个solrcore目录里面了一个solr实例运行时所需要的配置文件和数据文件
- 安装solrcore,拷贝solr-4.10.3/example/solr目录下所有东西到hm19/solrhome目录下
- solrcore配置
- solrcore配置,/hm19/solrhome/collection1/conf/solrconfig.xml,主要配置三个标签:lib标签、datadir标签、requestHandler标签如果对该文件不进行配置也可以,即使用默认的配置项
- 拷贝solr-4.10.3/contrib文件夹和solr-4.10.3/dist文件夹拷贝到hm19目录下
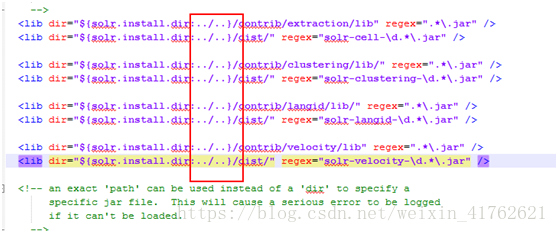
- 修改solrconfig.xml的lib标签
- datadir标签:每个SolrCore都有自己的索引文件目录 ,默认在SolrCore目录下的data中,这里不配置
- requestHandler标签:requestHandler请求处理器,定义了索引和搜索的访问方式,这里不配置
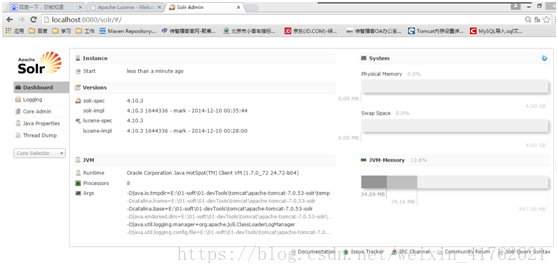
- 启动solr服务:http://localhost:8080/solr


4.多solrcore配置(看情况配置,可不配)
复制solrhome下的collection1目录到本目录下,修改名称为collection2
修改solrcore目录下的core.properties,将 name=collection1 改为 name=collection2
5.solr的基本使用
- schema.xml(hm19/solrhome/collection1/conf/schema.xml):主要配置了solrcore的一些数据信息,包括Field和FieldType的定义等信息,在solr中,Field和FieldType都需要先定义后使用。
- schema.xml配置:定义域的类型,将下面的代码加到schema.xml里面,位置:与其他fieldType平行就好
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Name:指定域类型的名称
Class:指定该域类型对应的solr的类型
Analyzer:指定分析器
Type:index、query,分别指定搜索和索引时的分析器
Tokenizer:指定分词器
Filter:指定过滤器
- 配置中文分词器(使用ikanalyzer进行中文分词)
- 将ikanalyzer的jar包拷贝到tomcat/webapps/solr/WEB-INF/lib目录下
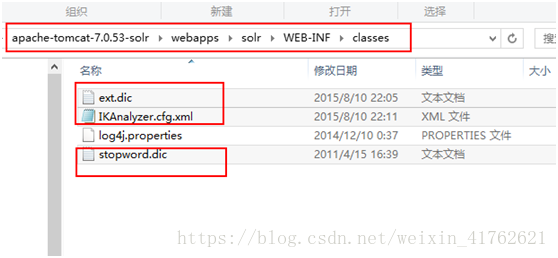
- 将ikanalyzer的扩展词库的配置文件拷贝到tomcat/webapps/solr/WEB-INF/classes目录下
- 配置中文分词器的fieldType,在schema.xml配置
- 配置使用中文分词器的fieldType
- 重启tomcat,就可以使用中文分词器的搜索域了
- 将ikanalyzer的jar包拷贝到tomcat/webapps/solr/WEB-INF/lib目录下


6.solrj的使用(solr服务器的java客户端)
- 引入jar包,将solr-4.10.3/dist/solr-solrj-4.10.3.jar和solr-4.10.3/example/lib/ext/*.jar拷贝到项目的lib文件夹
- 添加、修改索引:在solr中,索引库中都会存在一个唯一键,如果一个Document的id存在,则执行修改操作,如果不存在,则执行添加操作
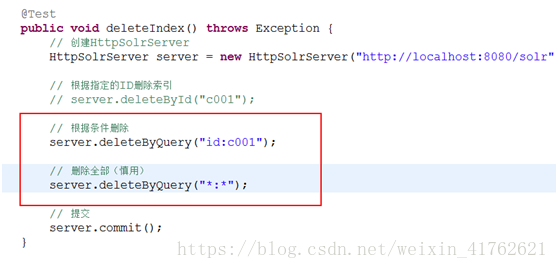
- 删除索引(根据ID)
- 删除索引(根据条件)
- 查询索引